
任务向导 | 快速实验构建指南
概述
如果您喜欢使用电子表格 / CSV 数据设置实验任务,任务向导可以帮助您加速实验任务创建过程!
使用任务向导,您可以从一个 CSV 文件和刺激文件中创建整个实验任务结构,包括刺激、事件、变量、因素、条件、随机化和数据记录。利用任务向导,您还可以选择刺激配对和画面转换,并在几分钟内拥有带有内置随机化和数据记录的定制任务结构。
工作流程提示: 在继续使用向导之前,查看下面的内容以了解如何组织 / 命名您的刺激并提前准备 CSV 文件可能会有所帮助。如果您有任何问题,请随时与我们联系!
访问任务向导
根据您在任务创建过程中的位置,访问任务向导的路径略有不同。
| 学习状态 | 访问任务向导的路径 |
|---|---|
| 新学习 | 创建新学习 → 设置任务 → 继续上传刺激 |
| 现有学习 | 打开现有学习,在 学习设计 标签下点击 + 新任务 选择 实验任务 → 继续上传刺激 |
进度条
访问实验任务向导后,将出现一个对话框,顶部显示准备任务的步骤和阶段:

有关任务向导功能的一般介绍,请查看此视频:
刺激上传在任务向导中
在此初始步骤中,您将上传实际的刺激文件。
- 上传所有刺激: 点击此处上传您所有的实验刺激(如果您有图片、视频等)。如果您有文本刺激,只需点击“下一步”并继续上传 CSV 文件。您将在后面指定刺激分配应如何工作(将在接下来的部分中描述)。请注意:
- 所有文件扩展名必须在刺激类别中保持一致! 例如,您不能在不同列之间切换 .jpg 或 .jpeg(请参见下面的图像示例)
- 根据文件上传器的工作方式,所有任务特定的刺激必须在同一个文件夹中。
- 点击“确定”后,您可以立即继续上传 CSV。
- 下一步(我已上传所有刺激): 继续进入任务向导的下一个阶段。
📌 实践学习: 如果您想下载示例数据以开始尝试任务向导,请使用以下链接下载我们提供的工作材料:
https://www.labvanced.com/static/taskWizardExamples.zip
CSV 上传在任务向导中
在上传刺激后,现在是时候上传您的 CSV 文件了。在接下来的部分中我们将更详细地解释如何设置 CSV。
从 CSV 到任务设置
CSV 在任务创建过程中的基本理念:
- 行: 您的 CSV 文件中的每一行将创建一个实验任务中的试次。在下图中,默认流程将生成 8 个试次——当然,您可以稍后编辑以根据实验设计需求更改试次数量。
- 列: 第一行可以用作列标题来命名刺激。每一列必须是一个单独的刺激元素(图像、视频等)或数据类别(将在下一节中描述)。请注意,每列的长度必须相同(即所有单元都已填充)。
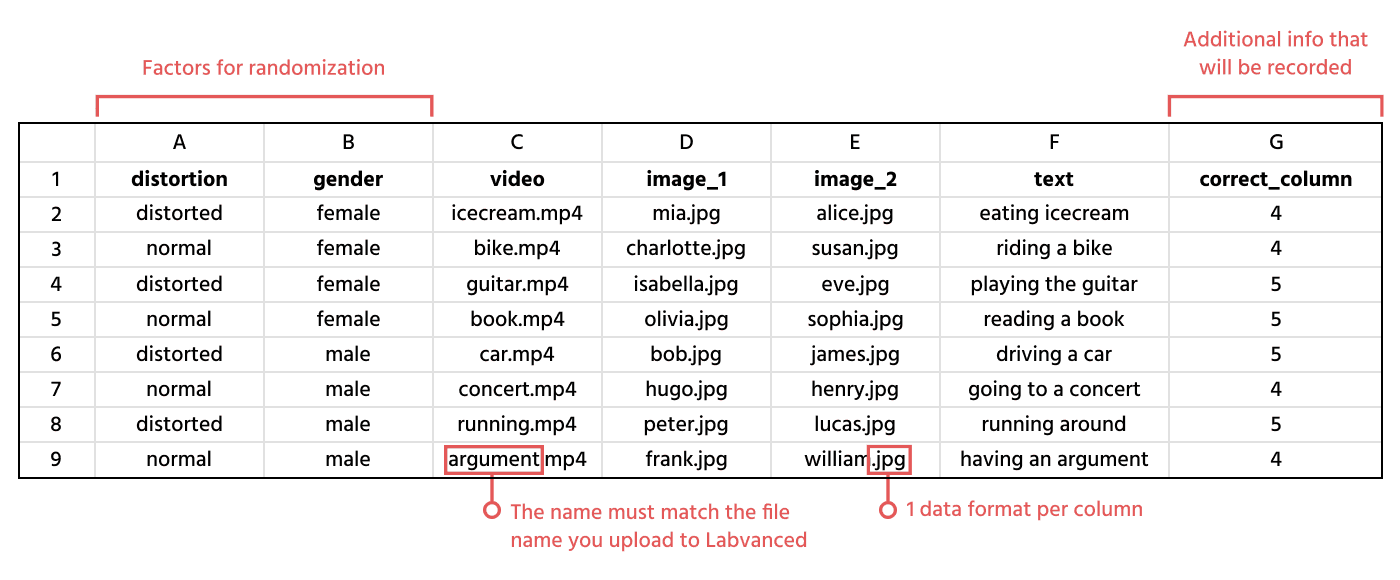
我们将在接下来的部分中更详细地解释上面的图像。
准备您的 CSV 文件
现在让我们讨论一下您应该 / 可以放入 CSV 文件中的信息种类。
CSV 文件可以包含 3 种不同类别的数据,即刺激、因素和附加信息:
| 数据类别 | 规格 / 描述 | 示例 |
|---|---|---|
| 刺激 | 刺激可以是文件名(图像、视频或音频),也可以是纯文本字符串。请注意:对于 CSV 文件中的所有刺激,相应的对象将自动创建。然后,在任务向导的后面部分,即 画面和刺激安排 步骤中,您将有机会按您希望的方式在展示给参与者的画面上排列它们。确保使用正确结尾的文件名,例如“flower.jpg” | 上面的图像中的 A列 表示视频刺激标题; B-C列 代表图像刺激的标题; D列 表示基于文本的刺激。 |
| 因素 | 因素就像您刺激的类别标签,必须包括与同一行中的刺激相关的水平 / 值。 例如,如果一个因素叫“失真”,它可能有两个可能的值“失真”或“正常”,每一行中的图像刺激因此应包含这些因素值之一; 一行中图像刺激失真的类别将因此为“失真”,而正常或控制图像的类别将为“正常”。 注意: 您可以为分配不同因素添加多个列,以便最后每一行都可以包含多个因素的值。例如,您可以添加一个称为“性别”的因素,对于图像刺激“alice.jpg”,其值将为“女性”。因此这将使这个试次的分类为“失真 x 女性”。这些组合因素在后面称为条件。 | 上面的图像中的 F-G 列 |
| 附加信息 | 此类数据可用作您希望每个试次记录的附加(刺激)描述,但既不是刺激本身,也不是因素 / 条件信息。 例如,您可能想要编码两种刺激中哪个是“正确的”,以计算受试者给出的答案是否正确。所有刺激信息将自动记录。 | 上面的图像中的 E 列 |
上传 CSV 文件
创建完您的 CSV 后,您可以继续上传它。将出现具有选项的对话框:

任务向导中的刺激和因子选择
CSV文件的预览将出现。如果需要,您也可以在这里重新上传您的CSV文件。
在此步骤中,您可以编辑顶部字段,如下图所示:
名称: 如果每列的第一个单元格是列名,则可以在此处进行编辑。 在下面的示例中,第一列的标题为‘direction’,第二列命名为‘degree’,以此类推……数据类型: 数据类型是基于CSV中包含的值自动选择和识别的。 点击‘书本’图标允许您重新分配刺激,而‘垃圾桶’图标将删除整个列,务必小心!用作: 此字段在这篇帖子中最需要关注。 您必须指明数据属于哪种类型的类别,如上面所讨论的(即刺激、因子或附加信息)。 根据下面的图像:- 列1将被用作‘因子’,因为在这个实验设计中,我们旨在评估单词分类的类型(即Bouba或Kiki)是否被正确识别。
- 列2是图像文件的名称
- 列3是将出现的文本字符串
- 列4也是将出现的第二个文本字符串
继续操作,您必须为所有用作字段分配值。
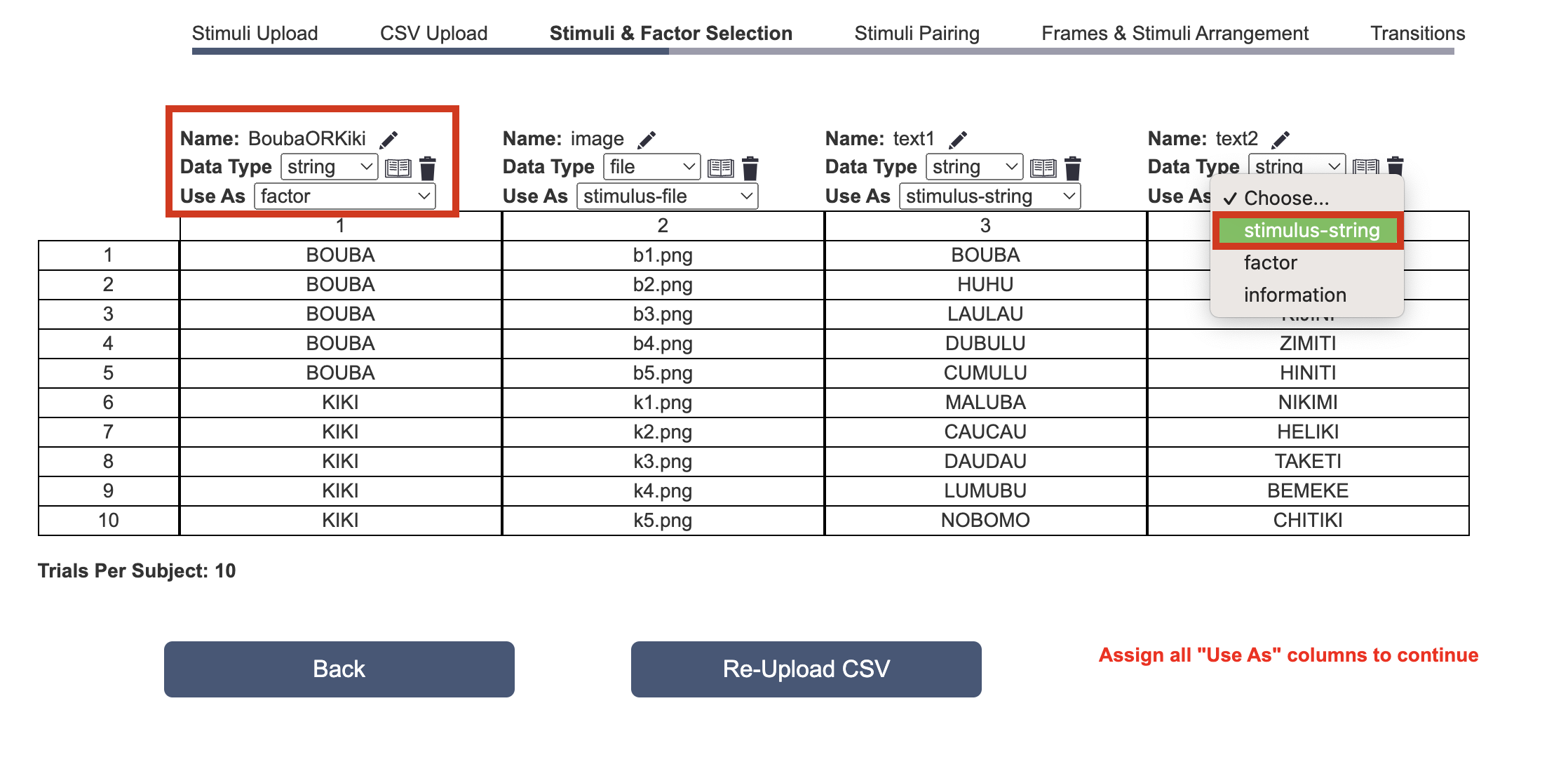
这样做后,会出现一个绿色的‘下一步’按钮,允许您进入下一阶段。
任务向导中的刺激配对
随机化配对
您CSV文件中配对的列在随机化过程中会共同洗牌(它们的行关系将保持不变),而不同配对组的列会根据参与者独立洗牌。 换句话说,通过配对刺激,在随机化过程中它们会保持在一起。 请注意,因子始终位于第一个配对组中,而刺激和信息列可以放在任何地方。 至少必须有一个配对组,每个组必须至少有一个条目。
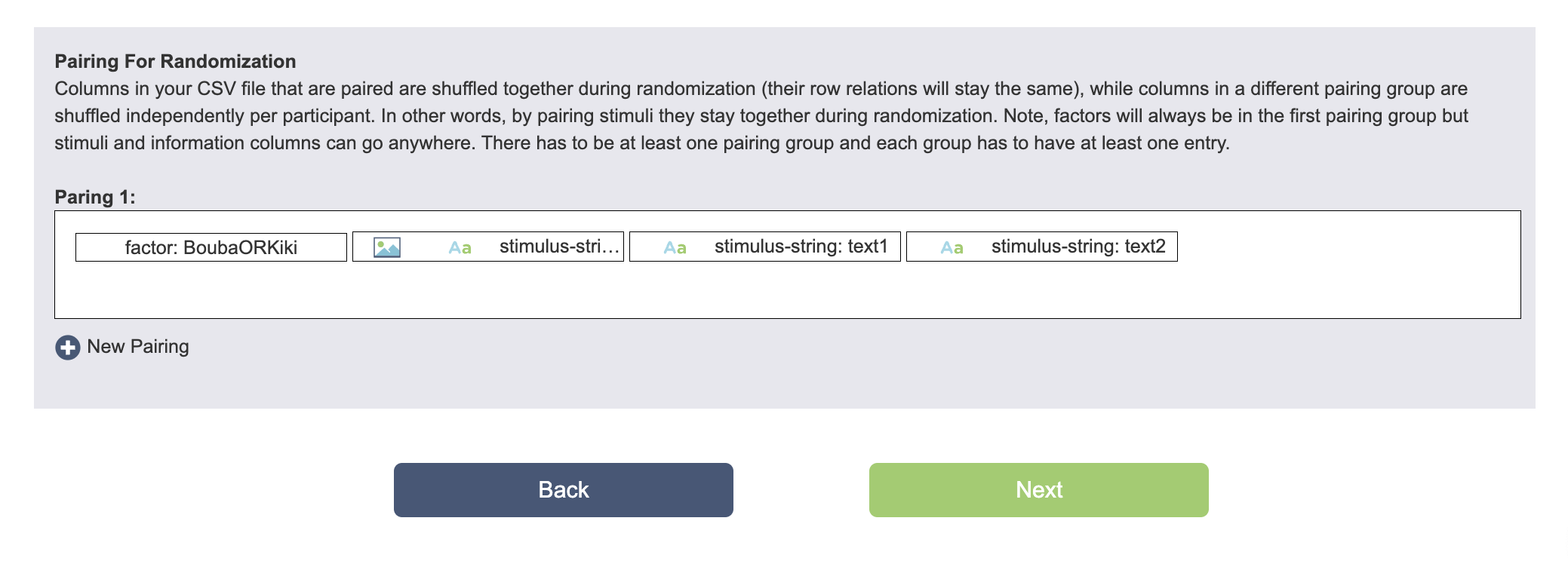
任务向导中的框架和刺激安排
将刺激放置在框架上
现在是安排您的刺激并决定每个试验有多少个框架,以及哪个刺激应放在哪个框架上的时候。 将记录的各种数据和过渡将在接下来的部分中讨论。

任务向导将自动按照您在CSV文件中的顺序每个框架放置一种刺激类型(列)。 上面的图像是从CSV文件输出的内容,显示了两节前。 同一框架上的刺激默认同时显示(您可以使用事件进行更改)。 不同框架上的刺激始终按试验时间线连续显示。 当然,所有这些内容都可以根据您的实验需求进行编辑。
在任务向导的此阶段,您可以创建新的框架,删除空框架,并在框架之间拖放刺激(例如,如果您希望文本和图像刺激在屏幕上一起显示)。 您还可以在没有任何刺激的框架上添加静态文本内容和注视十字。 在任务编辑器中将提供更详细的框架和刺激编辑选项,完成任务向导提供的基本设置过程后,框架分支逻辑,即您希望实验在试验中的一个框架与下一个框架之间如何进展,也可以在编辑器中稍后调整。 例如,如果答案是‘正确’,并希望该框架显示‘正确’作为反馈,这可以在任务编辑器中进行微调。
📌动手示例:重新排列刺激并添加注视十字: 在下面的短视频中,我们拖放刺激,使所有三个刺激在单个框架中在一起。 我们删除未使用的框架,并创建一个将在每个试验中位于刺激之前的注视十字。
任务向导中的过渡
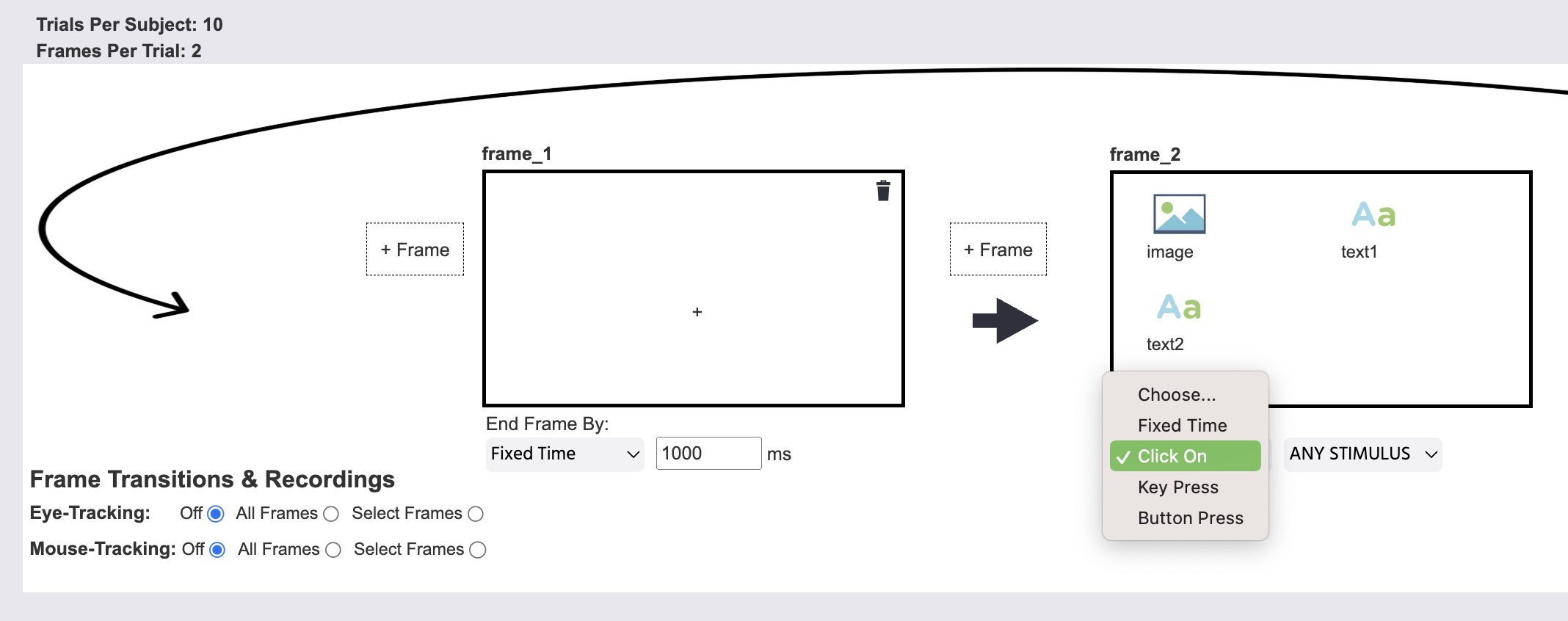
在排列框架后,是时候指定框架过渡和将要进行的记录类型了。 从这里,您可以选择是否希望为所有或特定框架激活眼动追踪或鼠标追踪。
在下面的图像中,frame_1将持续固定时间,我们指定为1000毫秒。 然后,frame_2将在点击任何刺激后结束。 请注意:对于这项研究,我们实际上希望框架在他们点击image对象时不会结束,但可以在任务编辑器中稍后通过选择该图像对象,然后在其对象属性下将活动选项设置为假来禁用。
任务向导自动设置为记录所点击的内容并将该数据存储在变量中。
关于随机化的补充说明
关于随机化,请注意以下信息:
- 默认情况下,试验顺序将完全随机化。
- 可以在
随机化设置对话框中设置更加自定义的试验顺序(例如固定顺序、分块条件、阶梯等)。 - 进一步的平衡(例如,左-右平衡的刺激)可以通过添加随机化来完成(见下图)。
- 使用
研究设计选项卡中的组或随机化分隔符,也可以进行组间平衡。 - 您可以在这里查看更多关于随机化技术的信息。
- 您还可以观看关于Labvanced中的随机化的深度视频。
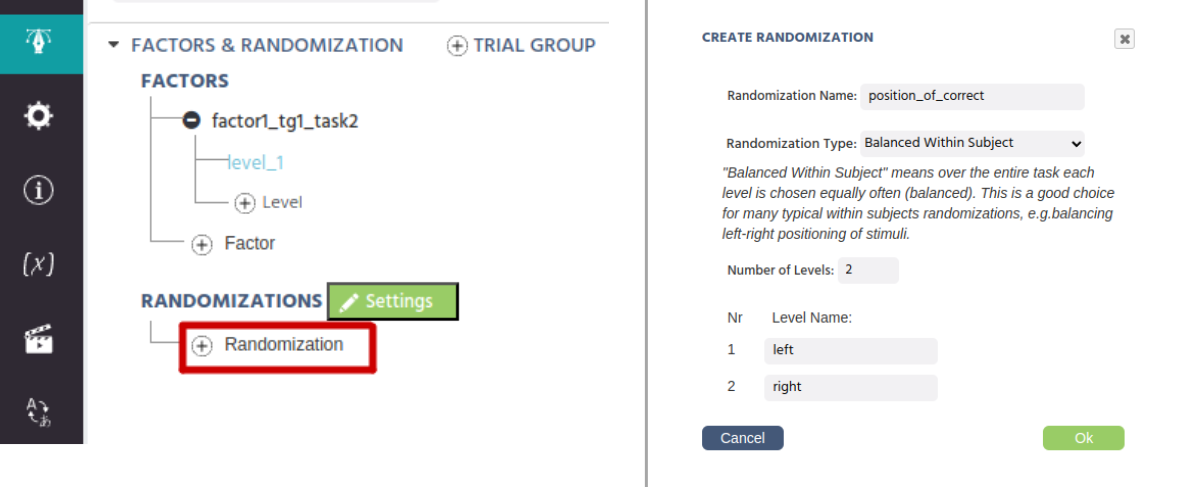
对于大多数研究,随机化可以简单直接。 但是,如果您需要帮助或对高级设计的随机化/平衡有疑问,请随时通过电子邮件或聊天支持与我们联系!