Tâche de Présentation Visuelle Séquentielle Rapide (RSVP) Guide
La tâche de présentation visuelle séquentielle rapide (RSVP) est une méthode d'affichage de textes ou d'images dans l'affichage central qui défile rapidement. Les observateurs doivent lire ou identifier la cible le plus rapidement possible dans le flux et sont notamment utilisés dans le domaine de la linguistique, des neurosciences et de la psychologie cognitive. Ce paradigme est couramment utilisé pour examiner les taux de lecture individuels, évaluer les déficiences visuelles, la dyslexie et la recherche sur l'attention (par exemple, le clignement attentif, l'aveuglement par répétition). Il existe de nombreuses façons de configurer la tâche RSVP selon l'investigation du chercheur, mais le guide actuel créera une tâche qui nécessite de détecter la répétition de mots le plus rapidement possible (voir Figure 1 ci-dessous).
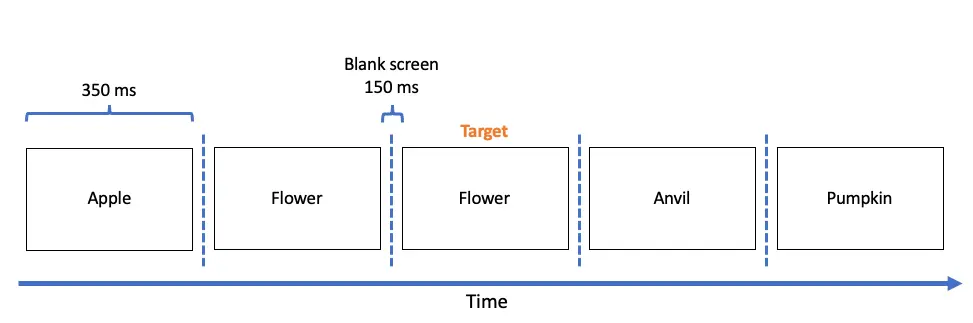 Figure 1. Représentation schématique de la tâche principale de répétition de mots. Les mots répétés servent de cible dans la tâche d'identification (par exemple, "Fleur").
Figure 1. Représentation schématique de la tâche principale de répétition de mots. Les mots répétés servent de cible dans la tâche d'identification (par exemple, "Fleur").
Contrairement aux expériences précédentes qui nécessitaient d'assigner manuellement des textes et des images, nous allons utiliser la fonctionnalité Data Frame dans Labvanced pour permettre au programme de référencer la feuille de données CSV et de présenter les mots selon sa structure préparée. Le Data Frame de Labvanced est une fonctionnalité en cours d'amélioration sur la plateforme qui permettra une présentation de stimuli plus efficace et une évitement des erreurs lors de la configuration des stimuli. En utilisant la fonctionnalité Data Frame, le présent guide progressera en quatre parties, comprenant :
- Préparation du Data Frame
- Configuration des cadres
- Configuration des stimuli
- Configuration des événements
Comme indiqué dans la première figure ci-dessus, la séquence d'affichage des essais comprendra :
- Cadre 1 : 500 ms de la croix de fixation
- Cadre 2 : 350 ms de la présentation du premier mot (référencé par le Data Frame)
- Cadre 3 : 150 ms d’un écran vide
- Cadre 4 : 350 ms du deuxième mot
- Cadre 5 : 150 ms d’un écran vide
- Cadre 6 : 350 ms du troisième mot
- Cadre 7 : 150 ms d’un écran vide
- Cadre 8 : 350 ms du quatrième mot
- Cadre 9 : 150 ms d’un écran vide
- Cadre 10 : 350 ms du cinquième mot
Au-delà de ce guide étape par étape, le modèle d'étude complet est également disponible en utilisant ce lien. Avec ce contexte et cette introduction, plongeons dans la création du Data Frame de cette étude.
Partie I : Préparation du Data Frame et configuration des variables
Pour préparer le Data Frame dans Labvanced, nous allons préparer une feuille Google séparée. Ici, nous listerons les chaînes de mots que nous allons présenter, et la figure ci-dessous représentera les mots qui seront utilisés pour la construction de la tâche actuelle (voir Figure 2 ci-dessous). Il convient de noter que chaque mot est présenté un nombre égal de fois en tant que cible. La ligne indique le nombre d'essais que nous allons définir, et chaque colonne représente chaque cadre pour afficher les textes. Par exemple, nous montrerons la présentation séquentielle de citrouille-avion-fleur-fleur-enclume dans le premier essai, avec le deuxième texte fleur servant de cible.
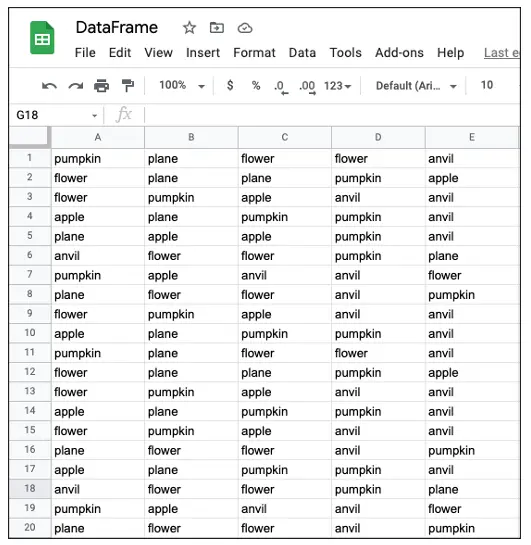
Figure 2. Affichage de la feuille Google avec la configuration de texte pour afficher chaque essai respective des lignes individuelles. Notez que les 20 lignes représentées serviront au même nombre d'essais dans l'éditeur de tâches.
En procédant à l'éditeur de tâches Labvanced, nous ouvrirons un nouveau cadre de toile et créerons quelques variables. Tout d'abord, cliquez sur Ajouter une variable en haut à droite de l'affichage et procédez avec les options suivantes représentées dans la figure ci-dessous (voir Figure 3). Ensuite, cliquez sur le bouton vert Modifier le Data Frame et sélectionnez Télécharger des données CSV 2D. Cela ouvrira le Stockage de Fichiers Labvanced, qui transférera les données CSV de la feuille Google vers ce dépôt. Après le transfert, sélectionnez les mêmes données (nommées DataFrame.csv dans ce cas) pour compléter la préparation du Data Frame. Cliquez ensuite sur Ok et sauvegardez le Data Frame dans la variable Data Frame.
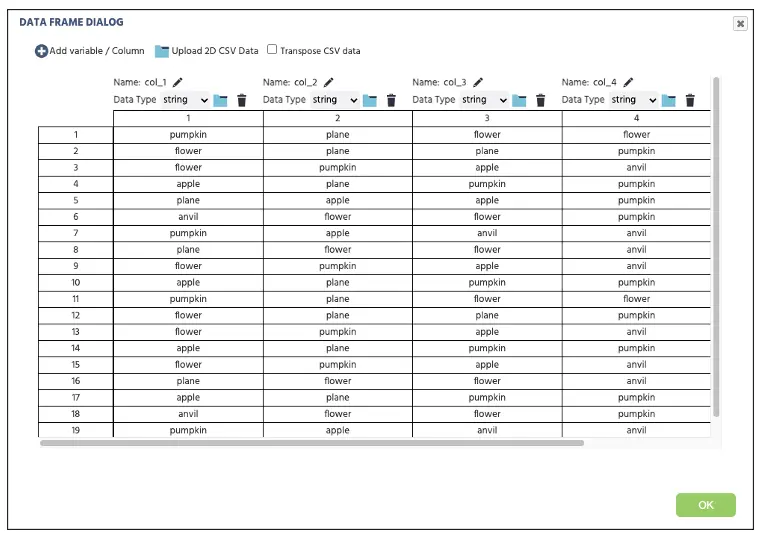 Figure 3. Affichage de la configuration du Data Frame Labvanced transféré depuis la feuille Google dans la Figure 2.
Figure 3. Affichage de la configuration du Data Frame Labvanced transféré depuis la feuille Google dans la Figure 2.
Avant de passer à la partie suivante, nous allons créer quelques variables supplémentaires. Comme lors des étapes précédentes, localisez et cliquez sur Ajouter une variable. Nous nommerons la variable Word1 avec le Type de Donnée défini comme Chaîne (voir Figure 4 ci-dessous). Nous allons répliquer cette étape quatre fois de plus pour les variables Word2, Word3, Word4 et Word5. Plus tard dans ce guide, nous allons assigner chaque colonne du Data Frame à chaque variable et lier aux cadres pour afficher les textes RSVP.
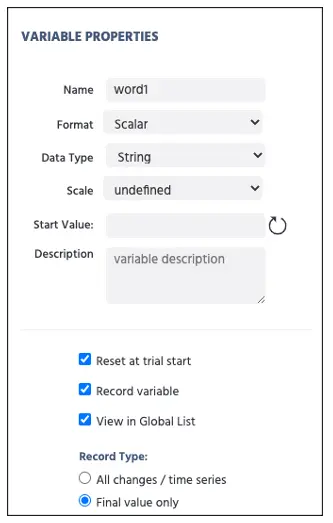
Figure 4. Affichage de la création de variable pour word1 avec le type de donnée chaîne.
Partie II : Configuration des cadres
La deuxième partie de ce guide concerne la création des cadres que les observateurs verront pendant la participation. Encore une fois, la tâche actuelle suivra la procédure générale mentionnée dans la Figure 1 composée de 10 cadres. Comme indiqué, un essai commencera par une croix de fixation (cadre 1) pendant 500 ms, suivi de la présentation de cinq combinaisons d'écran de texte (par exemple, cadre 2) pendant 350 ms, suivi de l'intervalle inter-essai vide (par exemple, cadre 3) pendant 150 ms. Pour créer ces cadres, nous cliquerons sur le bouton Toile dix fois en bas de l'affichage Labvanced (voir Figure 5A) et nommerons chaque cadre (voir Figure 5B) comme suit :
- Cadre 1 : fixation
- Cadre 2 : word1
- Cadre 3 : vide
- Cadre 4 : word2
- Cadre 5 : vide
- Cadre 6 : word3
- Cadre 7 : vide
- Cadre 8 : word4
- Cadre 9 : vide
- Cadre 10 : word5
Ensuite, nous allons saisir 20 pour le # Essais sur Essais & Conditions (voir Figure 5C) alors que nous présentons vingt essais de flux texte comme nous l'avons déterminé dans la configuration du Data Frame. Avec cela, nous avons maintenant tous les cadres nécessaires pour montrer la séquence d'essais. Dans la partie suivante, nous allons ajouter tous les stimuli dans chaque toile que les participants verront pendant leur participation.
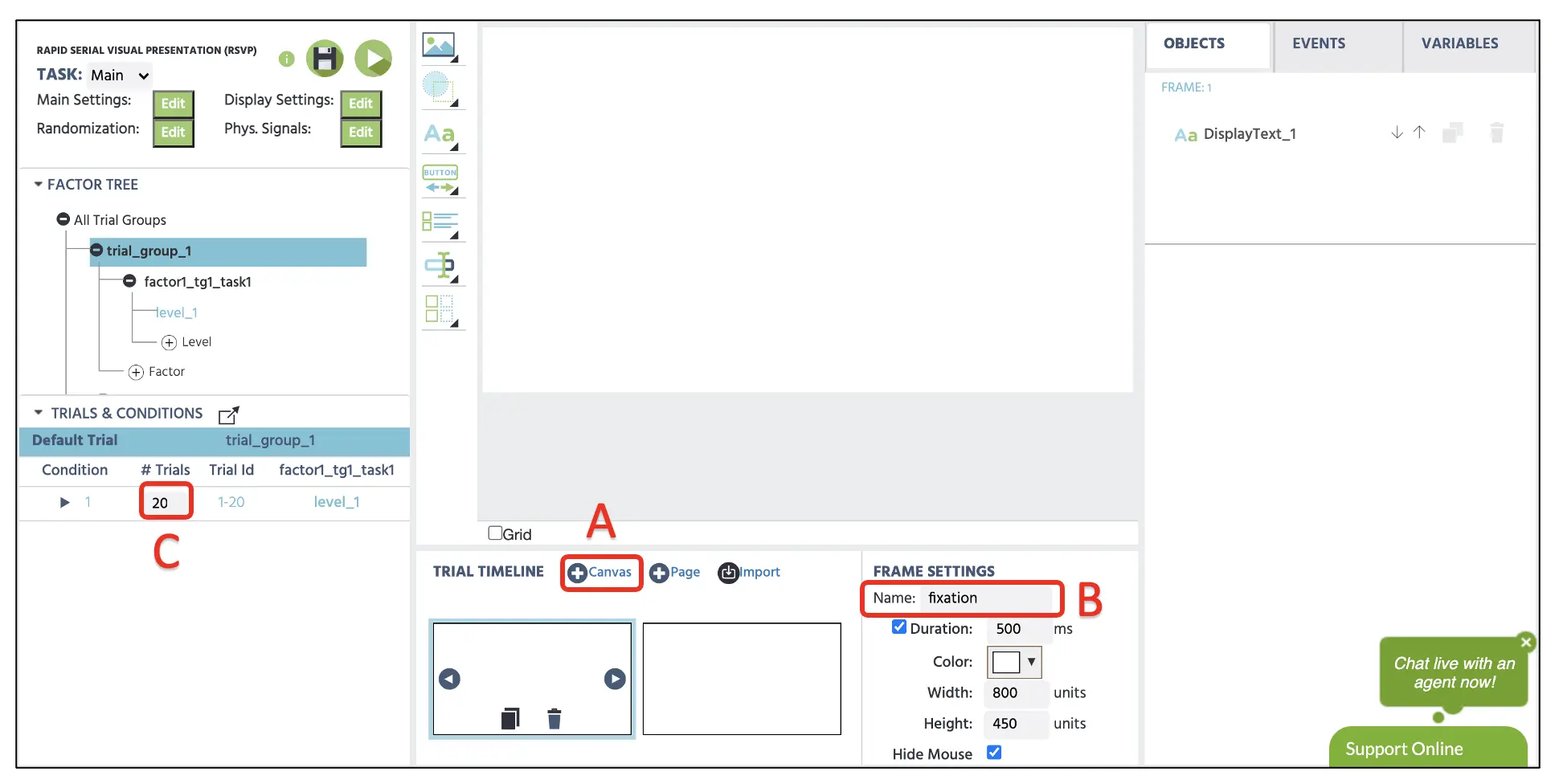 Figure 5. Affichage d'un essai échantillon avec création de cadre de toile (A), nom de cadre (B), et saisie du nombre d'essais (C).
Figure 5. Affichage d'un essai échantillon avec création de cadre de toile (A), nom de cadre (B), et saisie du nombre d'essais (C).
Partie III : Configuration des stimuli (croix de fixation, présentation de texte, et durée du cadre)
Cadre 1
Avec tous les cadres que nous avons préparés dans la dernière partie, nous allons maintenant définir le stimulus individuel dans chaque cadre, en commençant par la croix de fixation dans le 1er cadre. Pour créer une croix de fixation, nous pouvons commencer par cliquer sur le Afficher le Texte (voir Figure 6A) pour implémenter la zone de texte dans la toile. Ici, nous pouvons taper le + dans la boîte avec une police de couleur blanche de taille 36 et le positionner au centre de l'affichage. Nous pourrions également saisir les coordonnées X & Y spécifiques du cadre dans les Propriétés de l'Objet sur le côté droit pour la position centrale précise. Si nous voulons télécharger l'image contenant la croix de fixation ou différents stimuli, l'option Médias (voir Figure 6B) peut présenter des images, vidéos, audios, etc. Enfin, nous allons définir une durée de présentation de 500 ms en insérant des informations numériques dans la boîte de durée en dessous du nom du cadre.
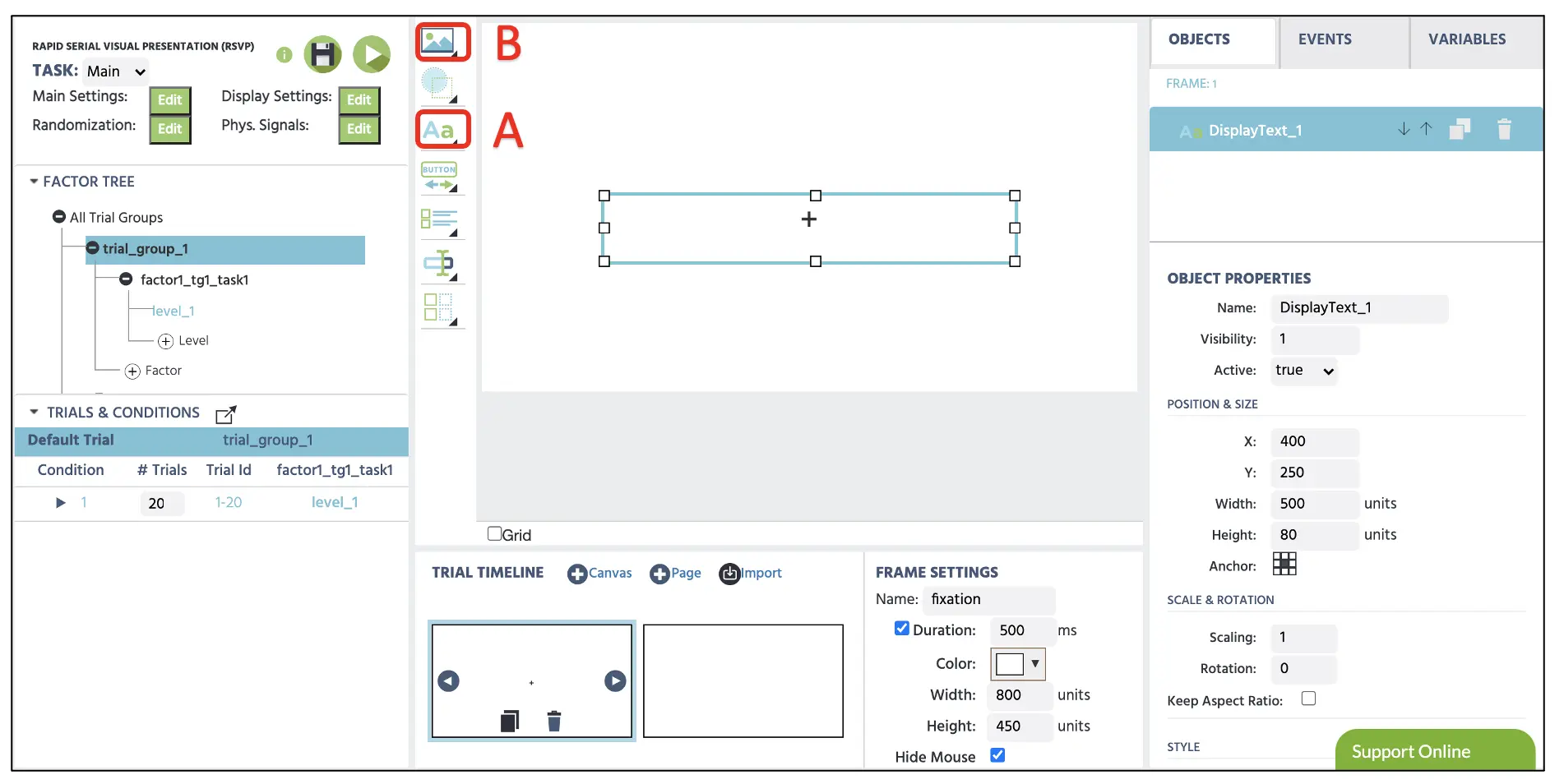 Figure 6. Affichage de la création du cadre de fixation avec l'option Afficher le Texte(A). Des images, vidéos et audios pouvaient être présentés via l'option Médias (B).
Figure 6. Affichage de la création du cadre de fixation avec l'option Afficher le Texte(A). Des images, vidéos et audios pouvaient être présentés via l'option Médias (B).
Cadres 2, 4, 6, 8, 10 (présentation de texte)
Dans le deuxième cadre, nous allons présenter le texte lié au Data Frame. Comme pour le premier cadre, nous allons définir l'affichage du texte à la position centrale du texte. Supprimez le message par défaut à l'intérieur de la zone de texte et cliquez sur l'icône Insérer Variable (voir Figure 7 ci-dessous). Ici, nous allons insérer la variable (par exemple, word1) que nous avons établie dans la partie précédente correspondant au nom identique du cadre (par exemple, insérer la variable word1 dans le cadre word1). Enfin, nous allons définir 350 dans la boîte de durée pour le temps de présentation. Pour les cadres vides restants (3, 5, 7, 9), nous allons seulement placer 150 dans la boîte de durée car ces cadres ne servent qu'à l'intervalle inter-essai entre chaque présentation de texte.
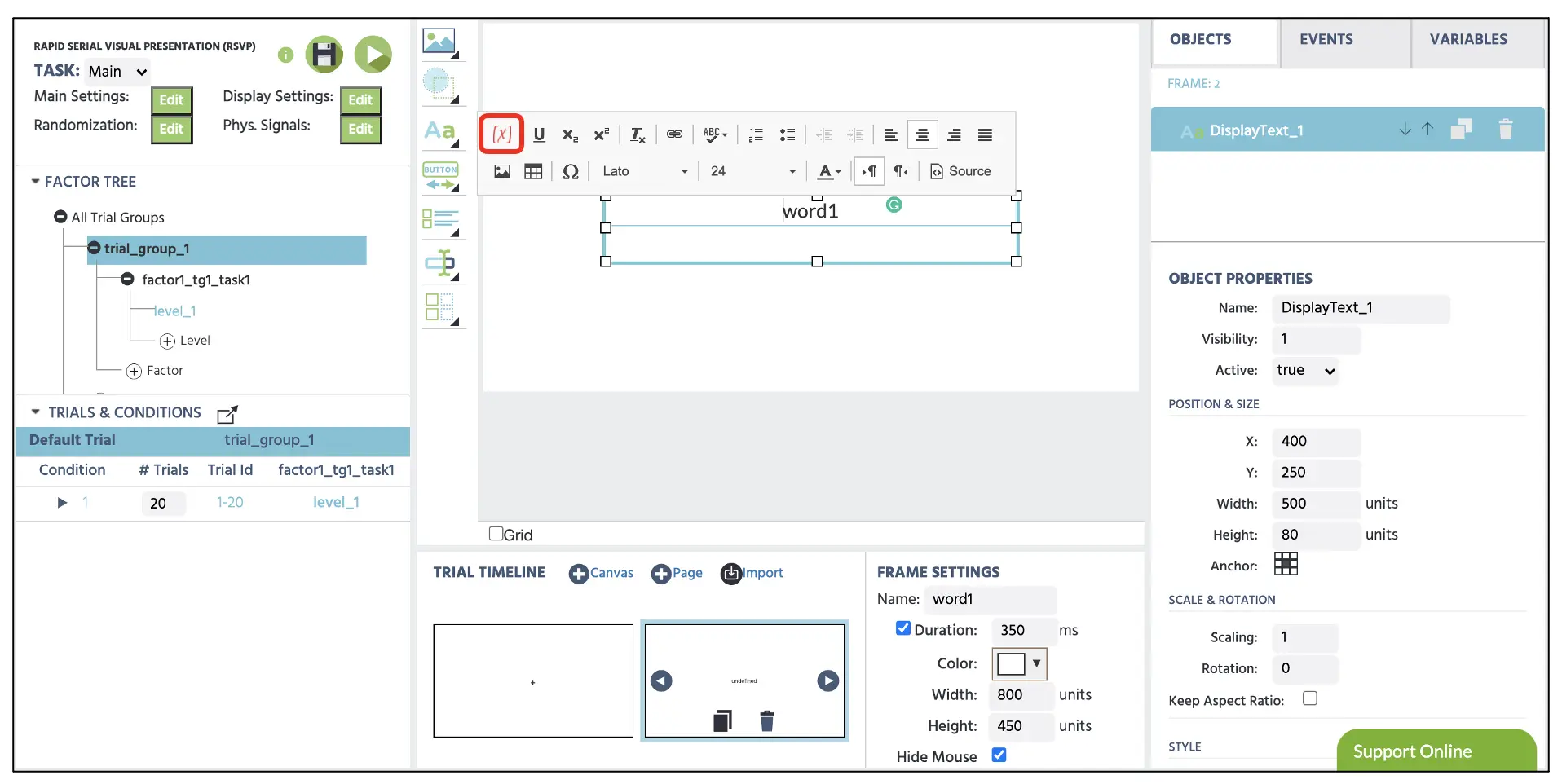 Figure 7. Affichage de la configuration du texte avec la variable word1 insérée. La boîte rouge indique l'icône Insérer Variable pour lier une variable particulière à l'affichage de texte.
Figure 7. Affichage de la configuration du texte avec la variable word1 insérée. La boîte rouge indique l'icône Insérer Variable pour lier une variable particulière à l'affichage de texte.
Partie IV : Configuration des événements
Dans cette partie, nous établissons une séquence logique pour que Labvanced exécute des actions spécifiques dans chaque cadre (par exemple, la durée du cadre et l'évaluation de la réponse). La création de cette séquence d'actions est connue sous le nom d'Événements sur la plateforme Labvanced. Avant de continuer, nous allons créer une nouvelle variable de Temps de réaction pour mesurer le temps de réponse à la pression de touche lorsque l'observateur détecte la répétition de texte. Cliquez sur Ajouter une variable en haut à droite de l'affichage et procédez avec les options suivantes représentées dans la figure ci-dessous (voir Figure 8).
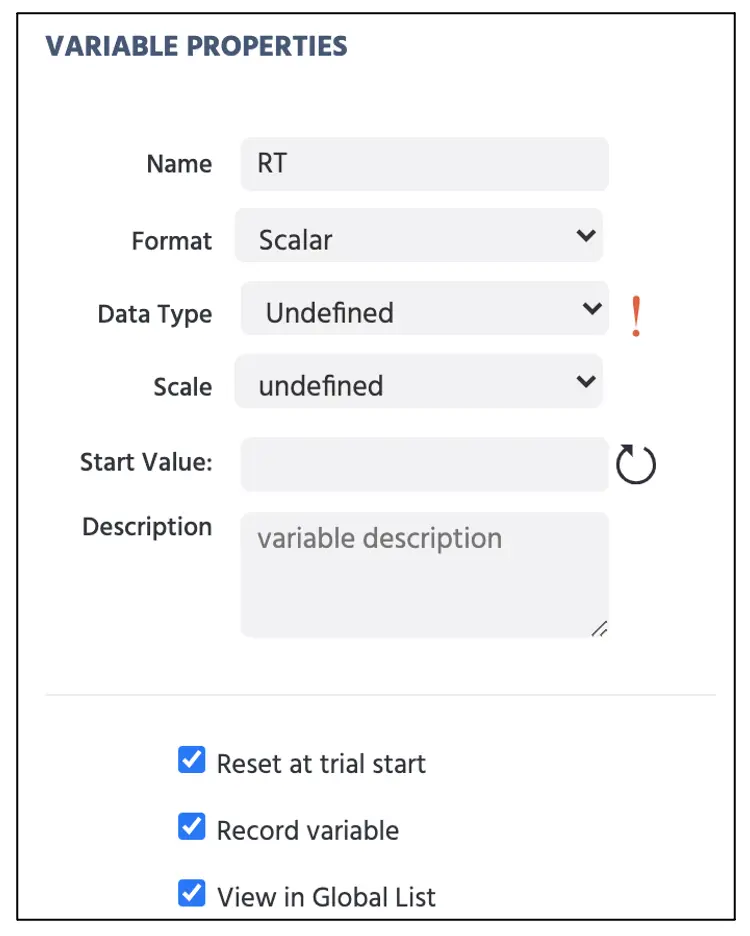 Figure 8. Affichage de la création de variable de temps de réaction (RT).
Figure 8. Affichage de la création de variable de temps de réaction (RT).
En avançant, nous allons créer le premier Événement liant le Data Frame à chaque variable de mot établie dans la partie précédente. Pour créer cet Événement, cliquez sur les Événements en haut à droite à côté des Variables et sélectionnez Événement de Cadre (sur ce cadre uniquement). Dans la première fenêtre de dialogue, nous pouvons nommer les Événements "Lien Data Frame" (Figure 9A) et cliquer sur suivant pour passer à l'option de Déclencheur. Ici, le type de déclencheur est Déclencheur d'Essai et de Cadre → Début de Cadre. Avec ce déclencheur, nous allons ajouter Action → Actions de variable → Définir/Enregistrer variable et sélectionner la variable word1 sur le côté gauche. À droite, sélectionnez Variable → Sélectionner valeur à partir du Data Frame → Data Frame. Nous allons sélectionner la variable Trial_Nr dans l'option de ligne et placer la valeur numérique "1" dans l'option de colonne. Nous allons répéter les étapes pour définir les variables word2, word3, word4 et word5 sur le Data Frame. Veuillez noter que chaque variable doit être définie avec un numéro de colonne correspondant (par exemple, word2 avec la colonne 2 dans l'événement Data Frame). Il est à noter que le Trial_Nr dans l'option de colonne présentera la séquence de mots dans l'ordre exact des lignes suivant le Data Frame, tandis que Trial_Id randomisera les lignes.
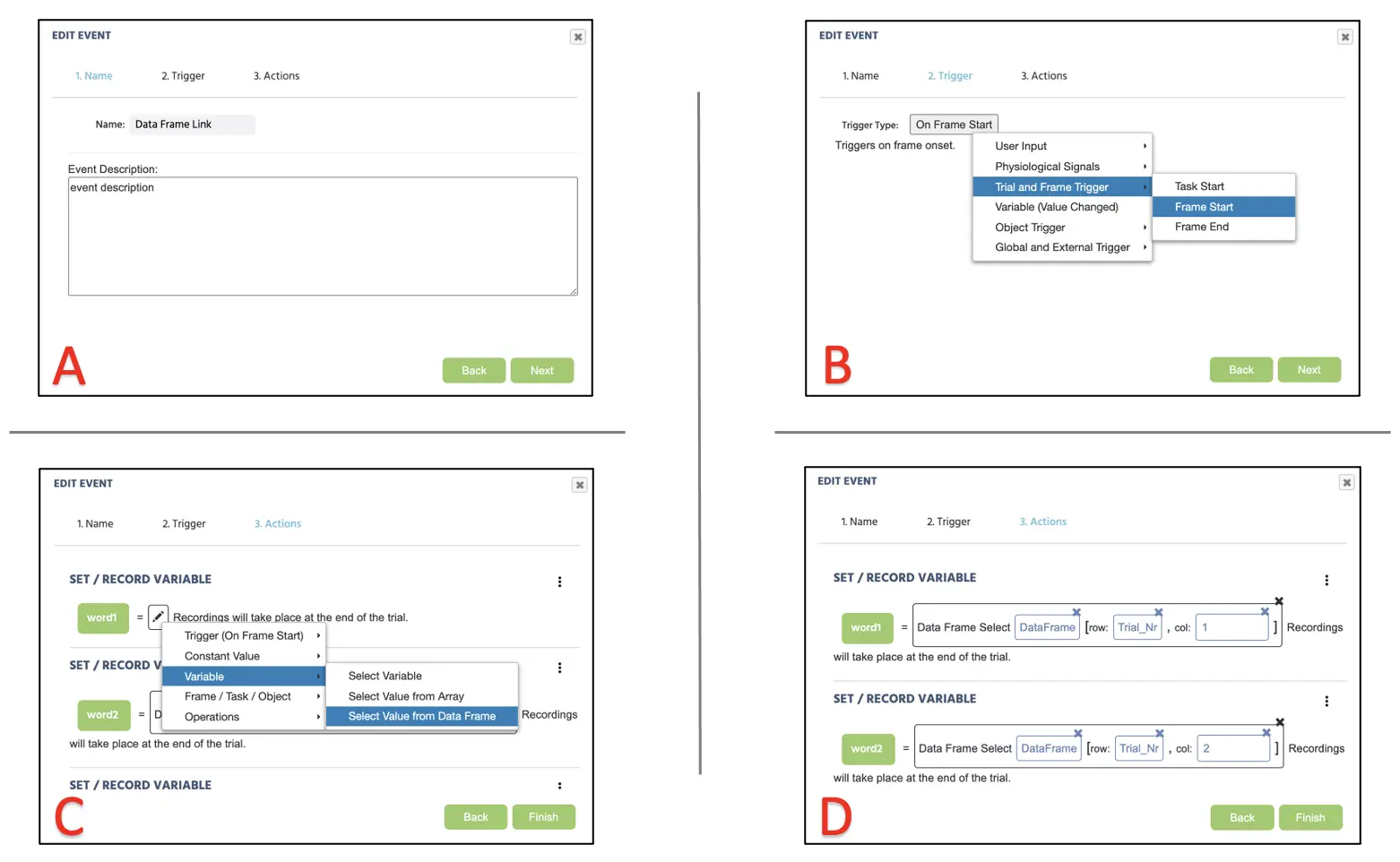 Figure 9. Affichage de la création d'Événement pour l'attribution de Data Frame suivant le nom de l'Événement (A), le déclencheur de l'Événement (B), l'attribution de Data Frame (C), et la spécification de ligne et de colonne (D).
Figure 9. Affichage de la création d'Événement pour l'attribution de Data Frame suivant le nom de l'Événement (A), le déclencheur de l'Événement (B), l'attribution de Data Frame (C), et la spécification de ligne et de colonne (D).
Ensuite, nous allons créer un nouvel Événement pour l'enregistrement du temps de réaction. Pour cela, procédez avec Événement d'Essai (sur chaque cadre). Dans la première fenêtre de dialogue, nous pouvons nommer les Événements comme "Temps de réaction" (Figure 10A) et cliquer sur suivant pour passer à l'option de Déclencheur. Ici, le type de déclencheur est le déclencheur de Clavier avec Espace comme réponse autorisée. En passant à l'Action, ajoutez Action → Actions de variable → Définir/Enregistrer variable et sélectionnez la variable RT sur le côté gauche. À droite, procédez avec Déclencheur (Clavier) → Temps depuis le début du cadre (voir Figure 10B ci-dessous). Avec cela, nous demandons au programme d'enregistrer la réaction du clavier à la cible mesurée en millisecondes depuis le début du cadre. Dans la même fenêtre d'Action, ajoutez Action → Actions de variable → Définir/Enregistrer variable et sélectionnez la variable Nom du Cadre sur le côté gauche. À droite, procédez avec Cadre/Tâche/Objet → Cadre → Nom du Cadre (voir Figure 10C ci-dessous). Cliquez sur Terminer en bas de la fenêtre pour compléter la configuration des Événements pour cette étude.
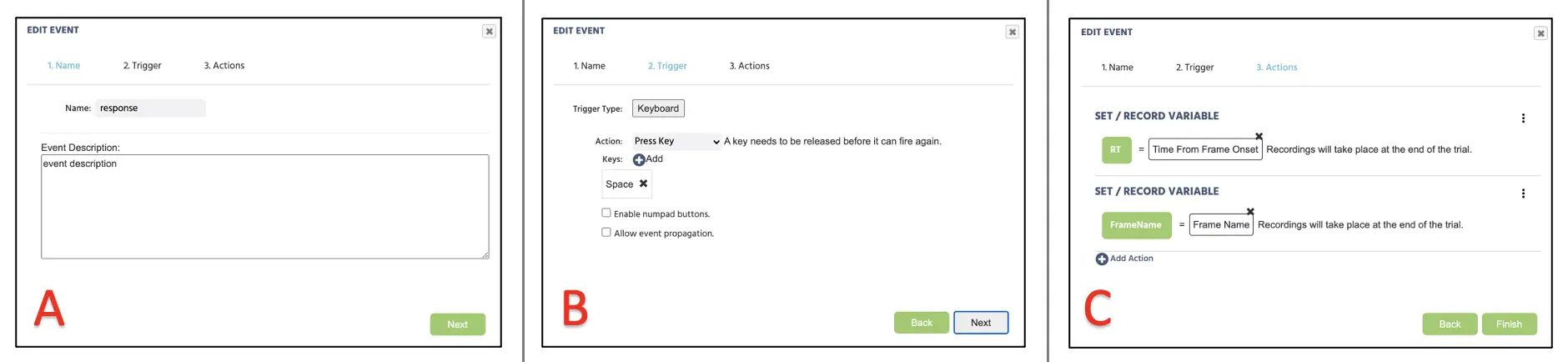 Figure 10. Affichage de la création d'Événement pour l'attribution de Data Frame suivant le nom de l'Événement (A), le déclencheur de l'Événement (B), et l'enregistrement de variable (C).
Figure 10. Affichage de la création d'Événement pour l'attribution de Data Frame suivant le nom de l'Événement (A), le déclencheur de l'Événement (B), et l'enregistrement de variable (C).
La seule chose qui reste dans ce guide est le document d'instruction/consentement, le bloc de pratique, les questions démographiques, et d'autres protocoles, mais cela varie selon le chercheur et l'enquête théorique. Pour plus d'informations sur la création de texte, veuillez consulter nos ressources lien pour des informations supplémentaires. De plus, l'étude construite est également disponible en tant que modèle de bibliothèque en utilisant ce lien et d'autres paradigmes expérimentaux. Cela dit, au nom de l'équipe Labvanced, nous espérons que ce guide fournit une base essentielle pour la construction de votre étude.