Envoyer à l'action OpenAI
Vue d'ensemble
L'action Envoyer à OpenAI vous permet d'envoyer des informations, telles qu'une valeur d'entrée de chaîne, à OpenAI. Vous pouvez spécifier un certain Type de Modèle pour recevoir l'invite dans le contexte de la génération de texte, d'image ou d'audio.
REMARQUE : Pour que cette option soit disponible, vous devez d'abord répertorier votre clé API dans l'onglet Paramètres.
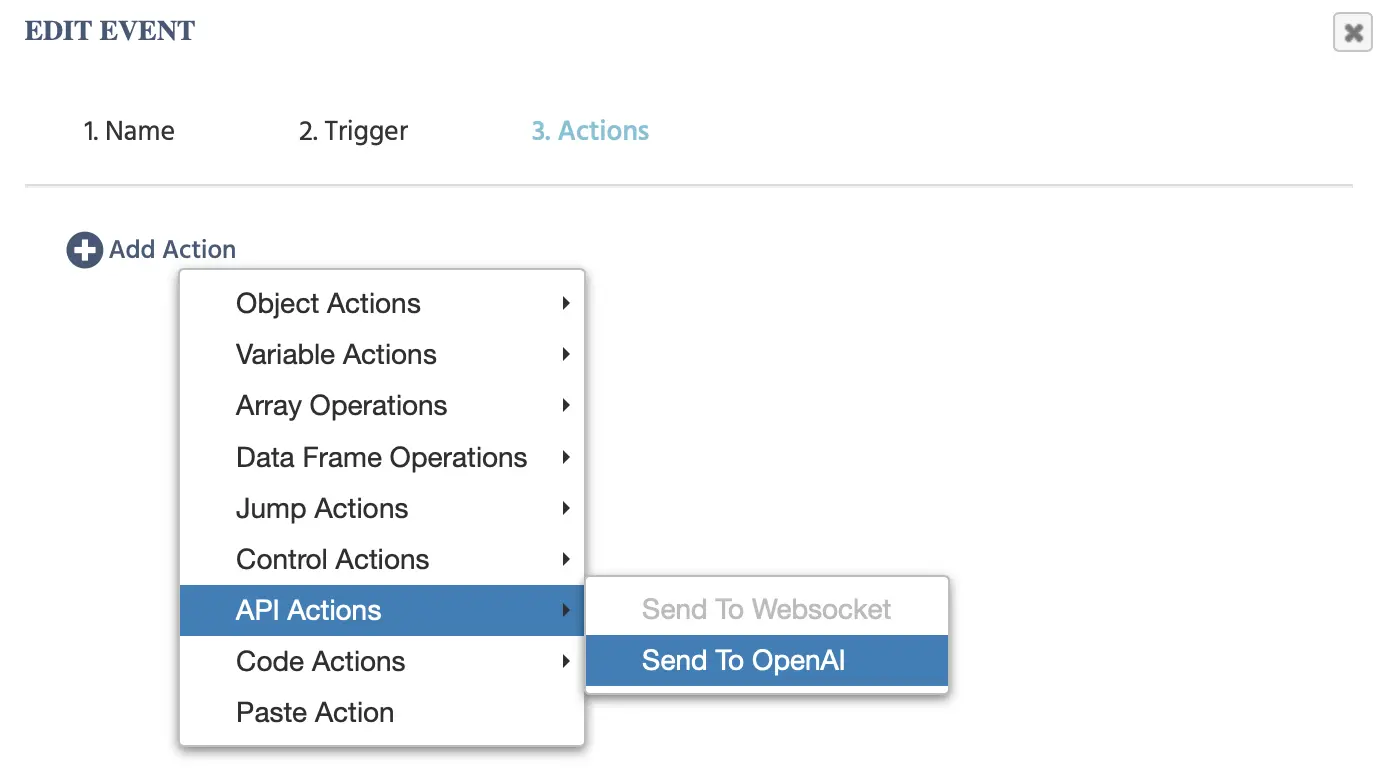
Les options suivantes apparaîtront lorsque vous cliquerez sur cet événement :
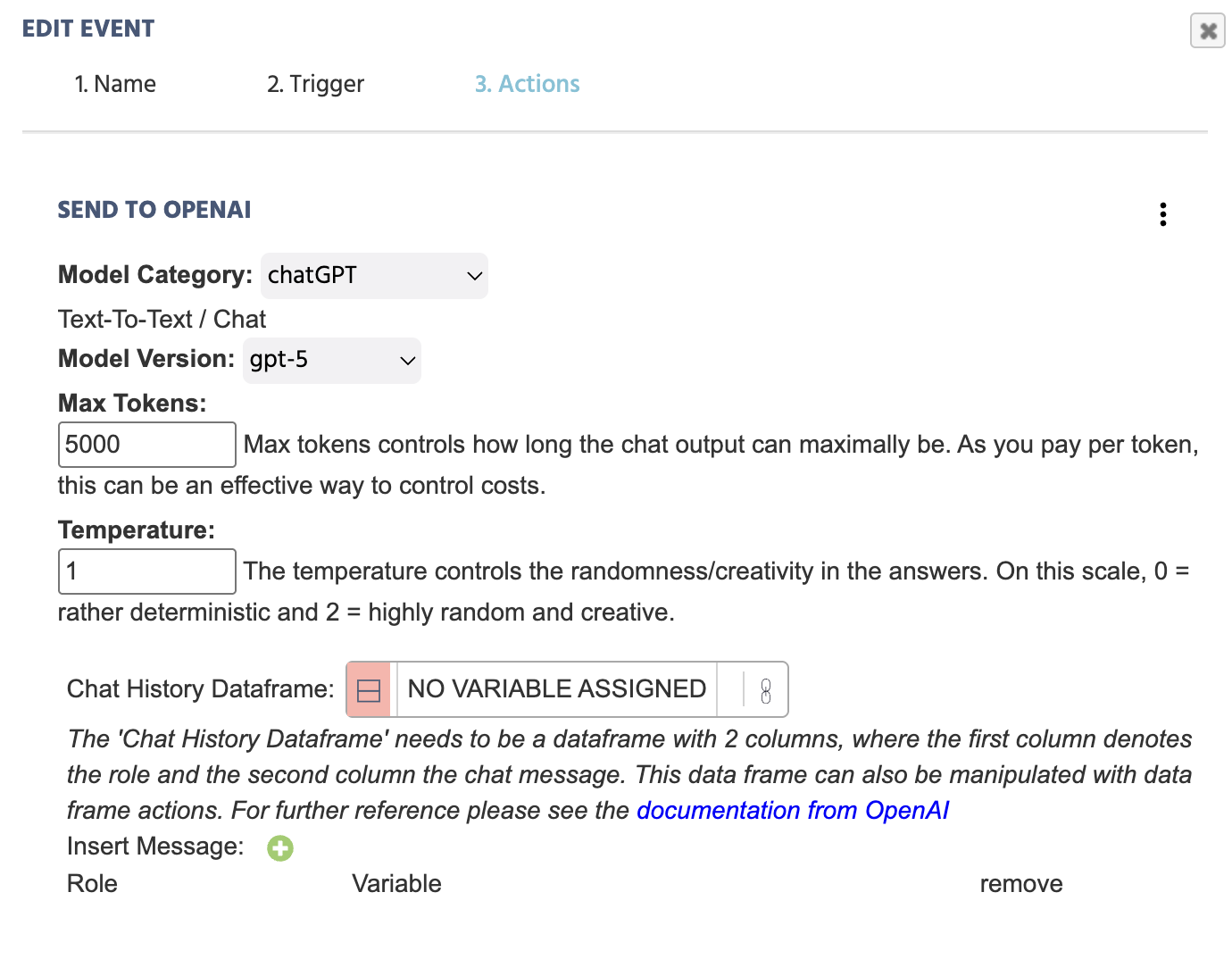
En fonction de la Catégorie de Modèle choisie,
Catégorie de Modèle
| Catégorie de Modèle | Description |
|---|---|
ChatGPT | Envoyer une entrée de texte à OpenAI dans le but de générer une réponse textuelle. |
Génération d'Image | Envoyer une entrée de texte à OpenAI dans le cadre de la génération d'une image. |
Générer de l'Audio | Envoyer une entrée de texte à OpenAI dans le but de générer de l'audio. |
ChatGPT - Catégorie de Modèle
Voici un exemple fonctionnel de à quoi ressemble cet événement lorsque toutes les informations nécessaires sont fournies :
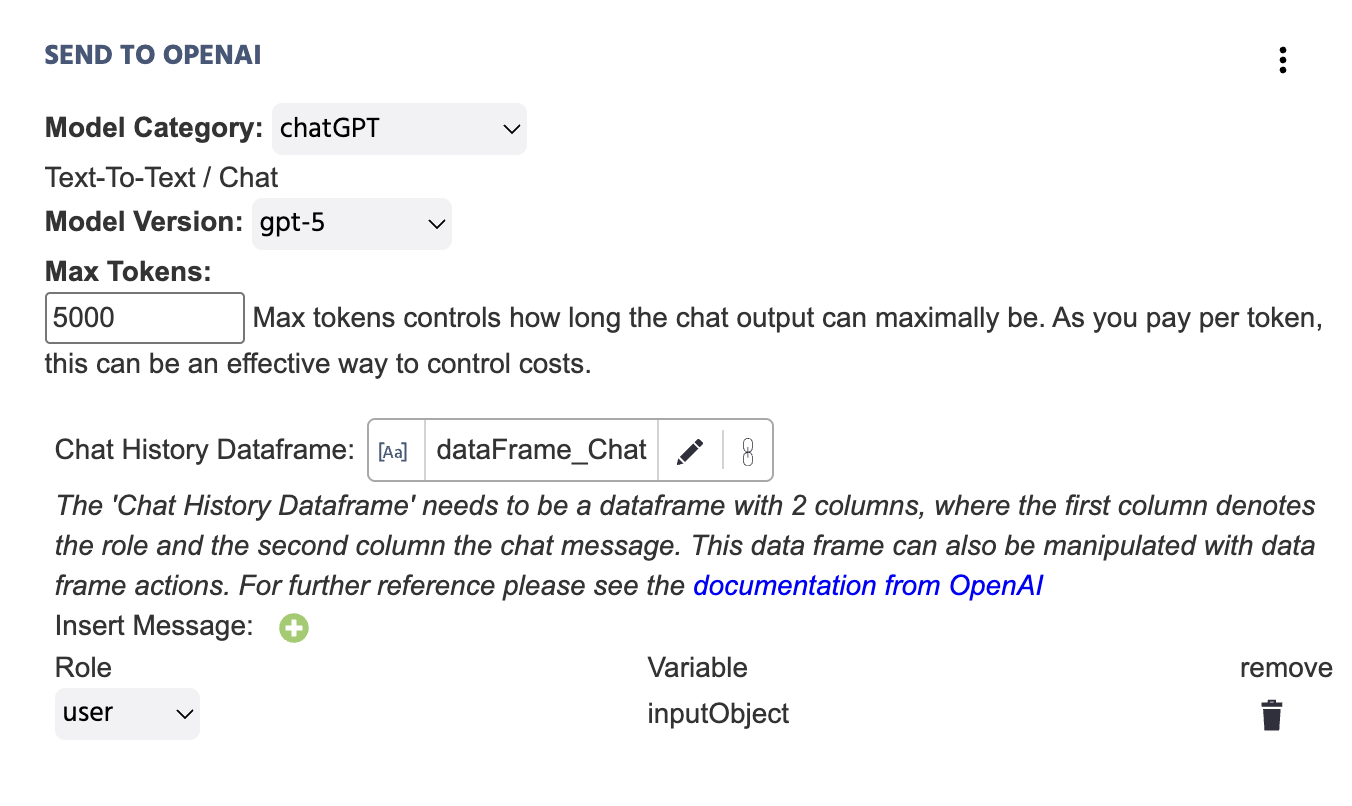
Voici une explication plus approfondie des champs inclus sous l'action Envoyer à OpenAI avec ChatGPT sélectionné comme Catégorie de Modèle :
| Élément de Menu | Options de l'Action 'Envoyer à OpenAI' - ChatGPT |
|---|---|
Catégorie de Modèle | Spécifie la catégorie du modèle IA pertinent pour l'action particulière. Dans ce cas, ChatGPT est sélectionné pour les scénarios texte-à-texte. Pour les autres options, comme la génération d'images ou d'audio, reportez-vous aux sections ci-dessous. |
Version de Modèle | Spécifie la version de ChatGPT qui doit être appelée lors de l'expérience. Les options disponibles varient de :
|
Max Tokens | Les tokens max contrôlent la longueur maximale de la sortie de chat. Comme vous payez par token, cela peut être un moyen efficace de contrôler les coûts. |
Température | La température contrôle la randomité/créativité dans les réponses. Sur cette échelle, 0 = plutôt déterministe et 2 = très aléatoire et créatif. |
Historique de Discussion Dataframe | Lien vers une variable de dataframe avec deux colonnes. La première colonne désignera le ‘rôle’ et la seconde colonne le ‘message de chat.’ Les valeurs de l'action seront automatiquement ajoutées au dataframe qui est lié ici. Le dataframe peut également être manipulé avec des actions de dataframe. Pour des références supplémentaires, veuillez consulter les docs d'OpenAI. |
Insérer Message ‘+’ | En cliquant ici, la boîte de dialogue des variables apparaîtra. Vous devrez indiquer quelle valeur de ‘Variable’ est envoyée à OpenAI ainsi que le ‘rôle’ du message associé :
|
REMARQUE 1 : Consultez également ce guide où nous construisons une étude étape par étape, intégrant ChatGPT dans une étude et utilisant cette action.
Génération d'Image - Catégorie de Modèle
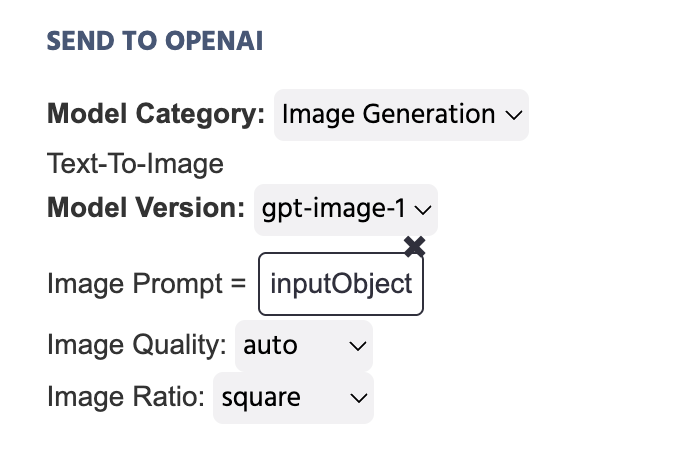
Dans l'exemple ci-dessous, la variable qui stocke le texte écrit dans un Objet d'Entrée est définie comme le Prompt d'Image qui sera envoyé à OpenAI à la suite de cette action :
Démo Utile : Découvrez cette démo qui utilise la génération d'images via le Déclencheur et l'Action OpenAI. Le participant est invité à entrer un prompt et ce prompt est ensuite utilisé pour générer une image.
Voici une explication plus approfondie des champs inclus sous l'action Envoyer à OpenAI avec Génération d'Image sélectionnée comme Catégorie de Modèle :
| Élément de Menu | Options de l'Action 'Envoyer à OpenAI' - Génération d'Image |
|---|---|
Catégorie de Modèle | Spécifie la catégorie du modèle IA pertinent pour l'action particulière. Dans ce cas, Génération d'Image est sélectionnée pour les scénarios texte-à-image. Pour les autres options, comme la génération d'images ou d'audio, reportez-vous aux sections ci-dessous. |
Version de Modèle | Spécifie la version de ChatGPT qui doit être appelée lors de l'expérience. Les options disponibles incluent :
|
Prompt d'Image | Vous donne la possibilité de définir le prompt pour l'image qui doit être générée. Les approches populaires incluent la définition d'une Valeur Constante comme une chaîne de texte écrite ou l'utilisation d'une variable Objet d'Entrée et son lien ici. |
Qualité de l'Image | Vous invite à indiquer la qualité de l'image qui sera générée à la suite du prompt textuel lié ci-dessus. Les options incluent : |
Ratio de l'Image | Vous invite à indiquer le ratio de l'image qui sera générée. |
Style de l'Image | Dans le cas où DALL-E-3 est sélectionné comme Version de Modèle, cette option apparaît pour spécifier le style de l'image. Les options incluent : naturel et vif. |
Générer de l'Audio - Catégorie de Modèle
Dans l'exemple ci-dessous, la variable qui stocke le texte écrit dans un Objet d'Entrée est définie comme le Prompt qui sera envoyé à OpenAI à la suite de cette action :
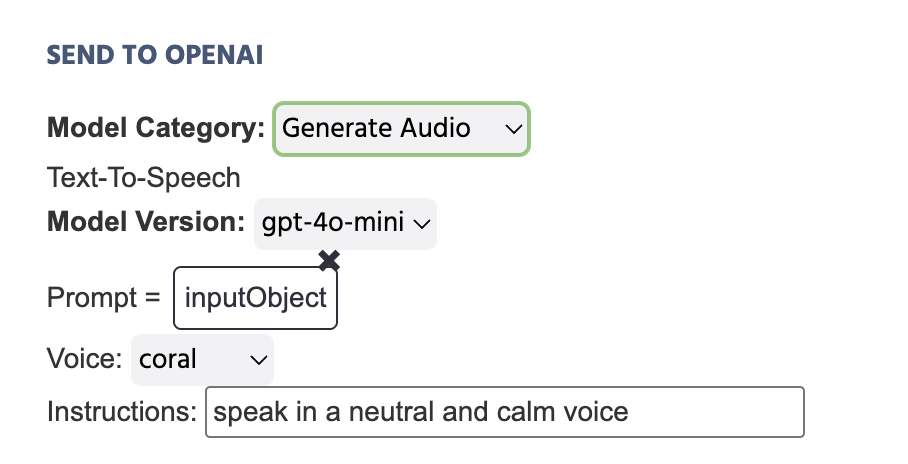
Voici une explication plus approfondie des champs inclus sous l'action Envoyer à OpenAI avec Générer de l'Audio sélectionné comme Catégorie de Modèle :
| Élément de Menu | Options de l'Action 'Envoyer à OpenAI' - Générer de l'Audio |
|---|---|
Catégorie de Modèle | Spécifie la catégorie du modèle IA pertinent pour l'action particulière. Dans ce cas, Générer de l'Audio est sélectionné pour les scénarios texte-à-audio. Pour les autres options, comme la génération d'images ou d'audio, reportez-vous aux sections ci-dessous. |
Version de Modèle | Spécifie la version de ChatGPT qui doit être appelée lors de l'expérience. Les options disponibles incluent :
|
Prompt | Vous donne la possibilité de définir le prompt pour l'audio qui doit être généré. Les approches populaires incluent la définition d'une Valeur Constante comme une chaîne de texte écrite ou l'utilisation d'une variable Objet d'Entrée et son lien ici. |
Voix | Définissez le ton de voix qui doit être adopté pour l'audio généré. Les options disponibles incluent :
|
Instructions | Tapez des instructions supplémentaires pour la forme que l'audio généré doit prendre, comme 'Parler d'une voix neutre et calme...' |
Démo Utile : Découvrez cette démo qui utilise la génération audio via le Déclencheur et l'Action OpenAI. Le texte parlé est généré via OpenAI et est utilisé dans le cadre de la lecture d'un paragraphe à haute voix aux participants pour lesquels ils doivent répondre à des questions à choix multiples.
Remarques Importantes
- Comme OpenAI évolue quotidiennement, veuillez consulter les docs d'OpenAI pour de plus amples clarifications concernant le chat et envisagez de parcourir la documentation pour d'autres catégories de modèles, comme texte-à-audio.