发送到 OpenAI 操作
概览
发送到 OpenAI 操作为您提供了将信息(例如字符串输入值)发送到 OpenAI 的能力。您可以指定某种 模型类型 来以文本、图像或音频生成的上下文接收提示。
注意: 要使用此选项,您必须先在 设置 标签下列出您的 API 密钥。
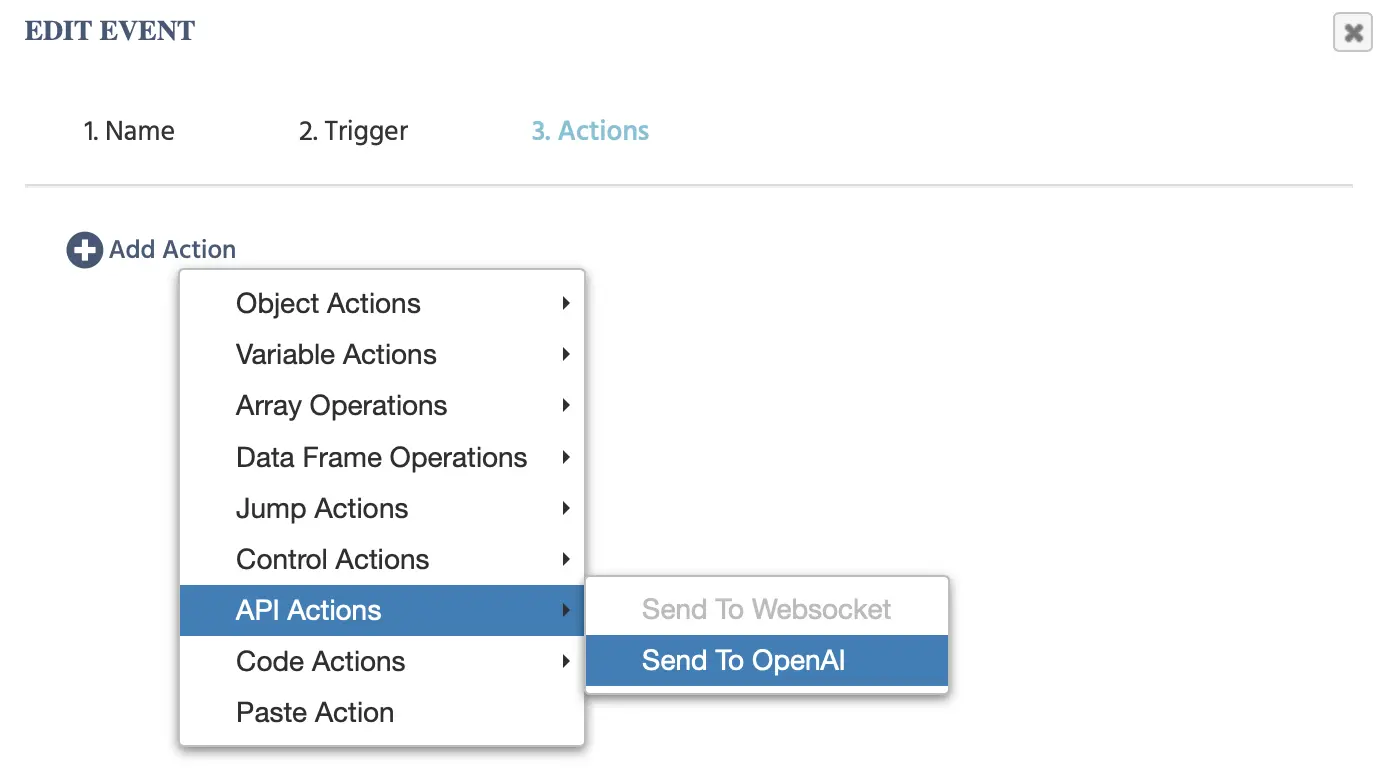
单击此事件后将出现以下选项:
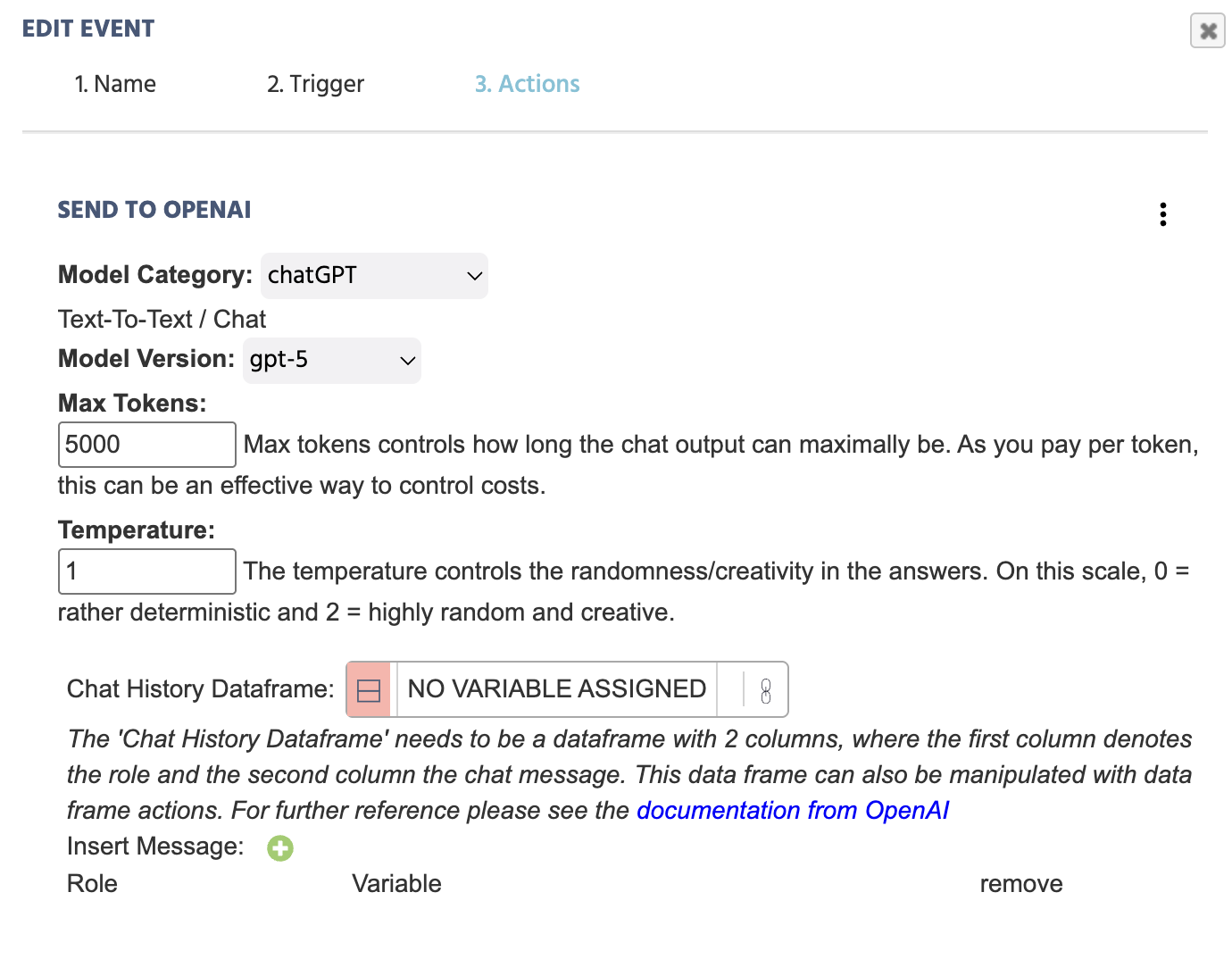
根据选择的 模型类别,
模型类别
| 模型类别 | 描述 |
|---|---|
ChatGPT | 将文本输入发送到 OpenAI,以生成基于文本的响应。 |
图像生成 | 将文本输入发送到 OpenAI,以生成图像。 |
生成音频 | 将文本输入发送到 OpenAI,以生成音频。 |
ChatGPT - 模型类别
以下是提供所有必要信息时此事件的功能示例:
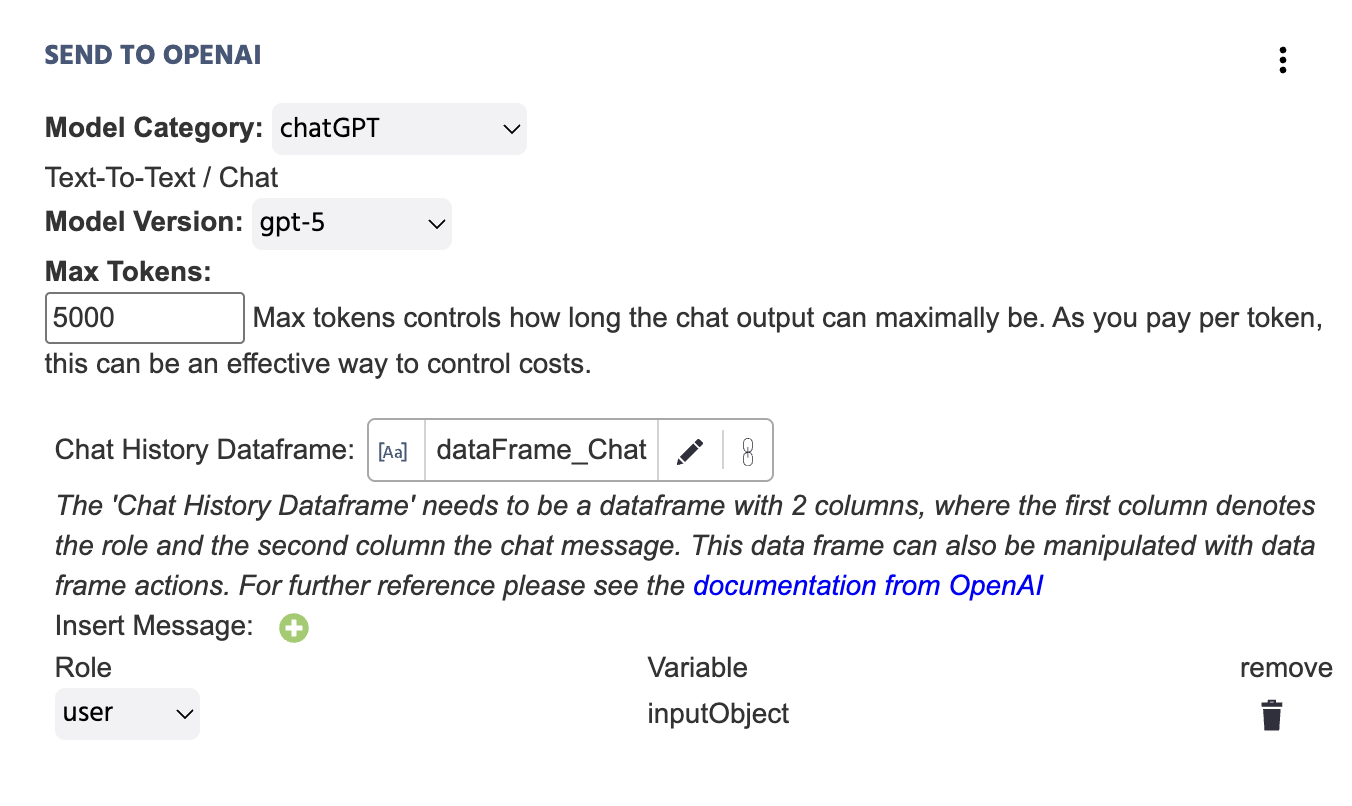
以下是关于选择 ChatGPT 作为 模型类别 的 发送到 OpenAI 操作中所包含字段的详细说明:
| 菜单项 | '发送到 OpenAI' 操作选项 - ChatGPT |
|---|---|
模型类别 | 指定与特定操作相关的 AI 模型类别。在这种情况下,选择 ChatGPT 用于文本对文本场景。有关其他选项,如图像或音频生成,请参见下面的部分。 |
模型版本 | 指定在实验中应调用的 ChatGPT 版本。可用选项包括:
|
最大 Token | 最大 token 控制聊天输出的最长时间。由于您按 token 付费,这可以是控制成本的有效方法。 |
温度 | 温度控制答案的随机性/创造性。这个尺度上,0 = 相当确定,2 = 非常随机和有创意。 |
聊天历史数据框 | 链接到一个具有两列的数据框变量。第一列将表示“角色”,第二列将表示“聊天消息”。该操作的值将自动追加到此处链接的数据框中。 数据框还可以通过数据框操作进行操作。有关进一步的参考,请查看 OpenAI 的文档。 |
插入消息 ‘+’ | 单击此项后,将出现变量对话框。您需要指明发送给 OpenAI 的“变量”值及其相关消息的“角色”:
|
注意 1: 还可以参考 这个演练,在其中我们一步一步地构建一个研究,集成 ChatGPT 并利用此操作。
图像生成 - 模型类别
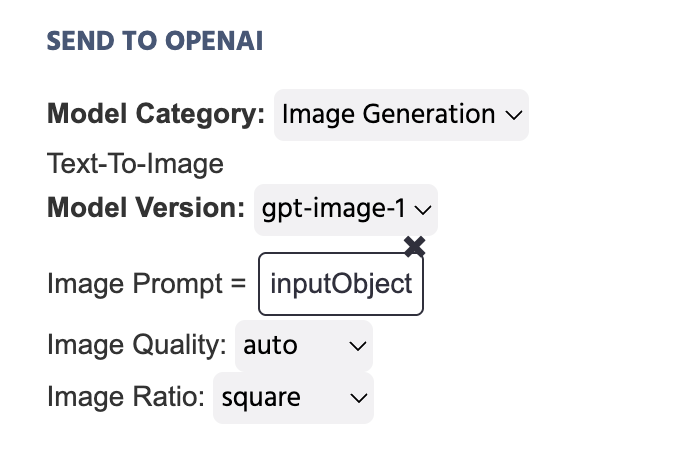
在下面的示例中,存储在 输入对象 中的文本作为将发送到 OpenAI 的 图像提示 进行设置:
有用的演示: 查看 这个演示,该演示利用 OpenAI 触发器和操作进行图像生成。参与者被要求输入提示,然后该提示用于生成图像。
以下是关于选择 图像生成 作为 模型类别 的 发送到 OpenAI 操作中所包含字段的详细说明:
| 菜单项 | '发送到 OpenAI' 操作选项 - 图像生成 |
|---|---|
模型类别 | 指定与特定操作相关的 AI 模型类别。在这种情况下,选择 图像生成 用于文本到图像场景。有关其他选项,如图像或音频生成,请参见下面的部分。 |
模型版本 | 指定在实验中应调用的 ChatGPT 版本。可用选项包括:
|
图像提示 | 提供设置应生成的图像提示的选项。常用方法包括设置像字符串文本这样的 常量值 或使用像 输入对象 变量并将其链接于此。 |
图像质量 | 提示您指明将根据上述文本提示生成的图像质量。选项包括: |
图像比例 | 提示您指明将生成的图像比例。 |
图像风格 | 如果选择 DALL-E-3 作为 模型版本,此选项将出现以指定图像风格。选项包括:自然和生动。 |
生成音频 - 模型类别
在下面的示例中,存储在 输入对象 中的文本作为将发送到 OpenAI 的 提示 进行设置:
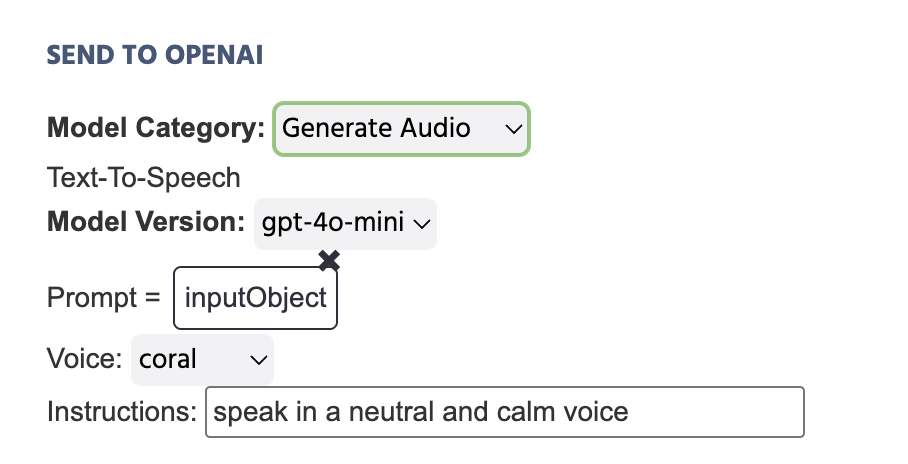
以下是关于选择 生成音频 作为 模型类别 的 发送到 OpenAI 操作中所包含字段的详细说明:
| 菜单项 | '发送到 OpenAI' 操作选项 - 生成音频 |
|---|---|
模型类别 | 指定与特定操作相关的 AI 模型类别。在这种情况下,选择 生成音频 用于文本到音频场景。有关其他选项,如图像或音频生成,请参见下面的部分。 |
模型版本 | 指定在实验中应调用的 ChatGPT 版本。可用选项包括:
|
提示 | 提供设置应生成的音频提示的选项。常用方法包括设置像字符串文本这样的 常量值 或使用像 输入对象 变量并将其链接于此。 |
声音 | 设置应采用的生成音频的声音音调。可用选项包括:
|
说明 | 输入对生成音频形态的进一步说明,例如“以中性和冷静的语气讲话……” |
有用的演示: 查看 这个演示,该演示利用 OpenAI 触发器和操作进行音频生成。生成的口语文本通过 OpenAI 生成,并用于将段落大声朗读给参与者,参与者必须回答选择题。
重要说明
- 由于 OpenAI 每天都在发展,请查看 OpenAI 的文档,以获取有关聊天的进一步说明,并考虑浏览其他模型类别的文档,例如文本到音频。