
变量选项卡
描述
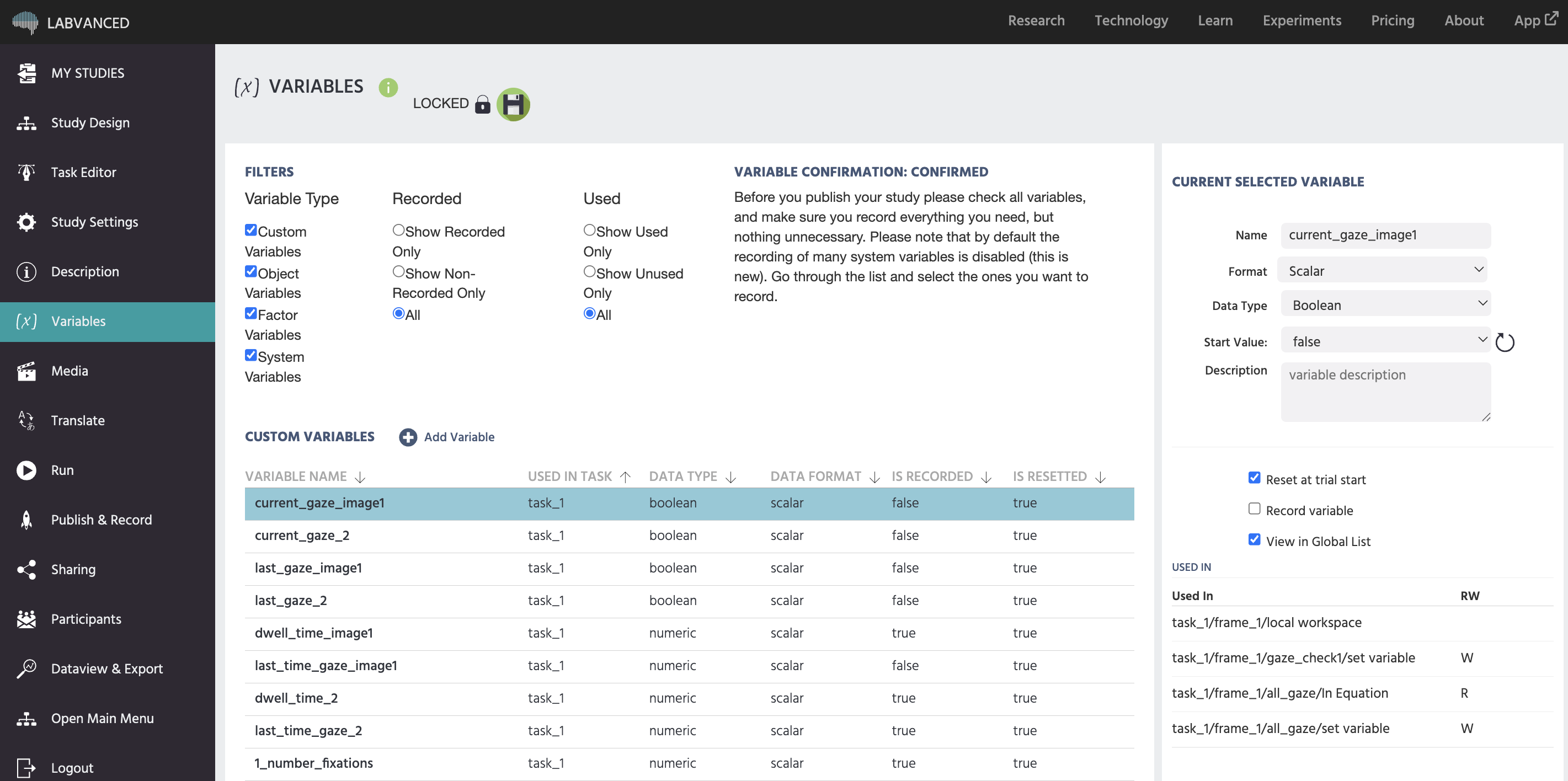
在“变量”部分,研究的所有变量都以一个列表的形式显示,按类型分类。最重要的变量属性(名称、量表、数据类型、数据格式、是否被记录、是否重置)会被显示。每个变量都可以被选择,从而在屏幕右侧显示并可以编辑该变量的属性。
重要提示: 在发布研究和开始数据录制之前,建议检查/检查所有变量属性(例如,检查所有相关变量是否被记录等)。
变量类型
在变量概述中,变量按其主要类型进行划分。主要有4种变量类型:
- 自定义变量: 所有用户创建的变量。
- 对象变量: 与(问卷)对象一起创建的所有变量(例如复选框、滑块等)。
- 因子变量: 在试验组中作为因子的所有变量。
- 系统变量: 所有自动创建的变量(Labvanced预创建)。
变量还按其范围进行分类:
- 试验变量: 这些变量是每个试验记录的变量。通常是用户创建的,一些示例包括反应时间和参与者选择。
- 会话变量: 这些变量在每个会话中仅记录一次,主要是Labvanced创建的。一些示例包括浏览器类型、屏幕大小和研究的开始/结束时间。
- 受试者变量: 这些变量在每个受试者中仅记录一次,并且是Labvanced创建的。这些变量在多个会话中保持相同,包含受试者ID等值。
研究人员通常只关注试验变量和会话变量。受试者变量对于纵向研究很有用。
删除变量
删除变量时应极为谨慎。在删除变量之前,请确保该变量未在研究的任何地方使用。当前选定变量的变量属性中将显示变量的使用情况,位于屏幕右下角(可能需要向下滚动)。虽然Labvanced会尽力更新这些变量使用情况,但在删除之前请通过查看不同任务和框架来检查某个变量是否确实未被使用。
如果您不是100%确定某个变量未被使用,建议禁用该变量的录制。这样,该变量将不会出现在数据视图中,但对您的研究没有风险。另一个选择是制作您研究的副本(复制所有变量和对象等),然后在该副本中删除相关变量并进行测试运行。这样,您可以看到没有该变量的研究效果。
如果删除了仍在某处使用的变量(例如在事件或对象中),可能会对您的研究造成不可逆转的损害!请小心!
共享变量
共享变量 是可以在会话和/或受试者之间共享的动态变量。这些变量存储在Labvanced服务器上。
受试者间平衡
想象一个有10,000张图片的研究,但每个参与者只显示100张图片。然而,这十千张图片中的每一张都应该至少显示一次,且以随机顺序。因此需要100个参与者来完成该研究。
共享变量可以用于写入一个数组,该数组存储尚未显示的图片编号。这确保参与者2不会看到参与者1所看到的任何图片。这样可以在刺激基础上平衡受试者之间的刺激。为了防止因参与者退出而造成的不平衡,该变量可以被设置为仅在参与者作出响应后记录某张图片已被看到。这样可以确保每张图片都有可用的响应,无论参与者是否完成了研究。因此,研究将生成随机的、平衡的和完整的数据。
多会话(纵向)研究
共享变量可以用来确保受试者在纵向研究的每个会话中使用(或不使用)相同的设备。
在这种情况下,可以使用另一种版本的共享变量。在此方法中,共享变量存储在参与者的设备本地,并且仅在会话间与参与者自己共享。然而,如果受试者使用私密浏览器或设备损坏,则此方法将不起作用。
在另一个示例中,想象一个研究,每个参与者有两个会话。在每个会话中,显示100张图片,但这两次会话之间的图片完全不同。这些图片从10,000张图片的语料库中随机选择。您可以随机抽取数字并将它们保存到一个数组中,以便每个受试者选择图片,然后在下一个会话中检索该数组,以确保不被第二次选择。
多用户研究
这些变量用于涉及多个参与者的研究,以便将值从一个人发送到另一个人。此方法利用服务器存储在受试者之间分发变量。
再次回忆上面提到的研究,有10,000张图片,但每个参与者只显示100张图片。十千张图片中的每一张都应该至少显示一次,且以随机顺序。
同样,共享变量可以用于写入一个数组,该数组存储尚未显示的图片编号。在此示例中,应在研究初始化时随机抽取数字并写入数组。然后数组将包括在多用户研究中每个参与者所见的图片。这确保参与者2不会看到参与者1当前所看到的图片。
示例研究
想象一个示例研究,您的智力与一个平均智力为100分的群体进行比较。您的分数只有在与他人比较时才具有相关性。为了进行这种比较,研究人员可以进行事后分析,或者他们可以给参与者实时反馈。
使用共享变量,可以将参与者的分数推送到一个充满值的数组中。然后该数组可以进行平均,并在研究结束时将百分位数值推送回参与者。通过这种方式,随着更多个体参与研究,共享变量会动态更新,但分析是在研究过程中进行的,而不是事后进行的。