Leitfaden zur Erstellung einer Lexikalischen Entscheidungsaufgabe
Hinweis: Der untenstehende Leitfaden stammt aus dem Jahr 2021 und könnte aufgrund jüngster Änderungen in der Benutzeroberfläche nicht mehr aktuell sein. Bitte nutzen Sie ihn als allgemeine Referenz, um zu verstehen, wie der Aufbau von Aufgaben angegangen werden kann. Für eine aktuelle Version der Lexikalischen Entscheidungsaufgabe - importieren Sie diese Vorlage: https://www.labvanced.com/page/library/74678
Willkommen zu einem weiteren Labvanced-Leitfaden zur Studienerstellung! Dieser Inhalt ermöglicht Ihnen die Erkundung eines der bemerkenswerten Studienerstellungen in der Psychologie und Psycholinguistik, der lexikalischen Entscheidungsaufgabe (LDT). Bei dieser Aufgabe muss ein Befragter schnell entscheiden, ob die präsentierten Buchstabenkombinationen Wörter sind oder nicht. Das Wort wird paarweise oder allein angezeigt, und der Befragte muss basierend auf der gesamten Präsentation bestimmen, ob es sich um ein Wort oder ein Nichtwort handelt. Wenn beispielsweise das Wort „PARROT & BRIDGE“ präsentiert wird, antwortet eine Person: „Ja, beide sind echte englische Wörter“, aber wenn die Buchstaben „XVERA & BRIDGE“ präsentiert werden, antwortet sie „Nein, eines der Wörter ist kein echtes englisches Wort“.
Die LDT wurde von Meyer und Schvanveldt (1970) eingeführt, wobei die Forscher das Ziel verfolgten, die Organisation des Langzeitgedächtnissystems und wie Menschen Informationen aus seiner Speicherung abrufen, zu verstehen. In ihrer ursprünglichen Studie fanden sie heraus, dass die Leistung der Aufgabe (schneller und genauer antworten) besser war, wenn die präsentierten zwei Wörter semantisch verwandt waren als das nicht verwandte Paar. Dies scheint anzuzeigen, dass die Worterkennung auch die verwandten Informationen aktiviert, die die Erkennung des anderen verwandten Wortes beeinflussen.
Die aktuelle Studienerstellung ähnelt der ursprünglichen Studie von Meyer & Svaneveldt (1970), jedoch mit weniger Versuchen. Ihre ursprüngliche Arbeit präsentierte 48 assoziierte Wortpaare, und die Befragten entschieden, ob die Wortpaare echt (z. B. COFFEE und TEA) oder nicht (z. B. COFFEE, SOHDA) waren. Ähnlich wie bei der Erstellung der Stroop-Aufgabe ist dieses Paradigma in Labvanced ein relativ unkomplizierter Prozess. Um systematisch von Anfang bis Ende zu arbeiten, umfasst dieser Leitfaden die Schritte in 5 Teilen:
- Variablenbestimmung (UVs & AVs)
- Einrichtung der Frames (Fixierung, Ziel, Feedback-Nachrichten)
- Einrichtung der Stimuli (visuell & auditiv)
- Einrichtung der Ereignisse
Ohne weitere Umschweife, lassen Sie uns mit der Erstellung der ersten Aufgabe beginnen, indem wir die wichtigen Variablen für die Studienstruktur bestimmen.
Teil I: Variablenbestimmung
Wie bei jeder Studienvorbereitung ist die Bestimmung der Variablen wichtig für die Studienstruktur. Dafür können wir den Faktorenbaum verwenden, um die Faktoren (oder unabhängigen Variablen) und deren jeweilige Stufen (oder Kategorien) zu bestimmen. Im Rahmen der aktuellen multimodalen Stroop sind die Faktoren und deren Stufen wie folgt:
- Faktor 1 - Wort/Nichtwort
- a. Stufe 1 - Wort
- b. Stufe 2 - Nichtwort
- Faktor 2 - semantische Beziehung
- a. Stufe 1 - verwandt
- b. Stufe 2 - unverwandt
Die vollständige Darstellung dieses Aufbaus im Faktorenbaum ist ebenfalls unten dargestellt (siehe Abbildung 1A). Mit diesem 2 X 2 orthogonalen Aufbau wird Labvanced 4 verschiedene Bedingungen erstellen (siehe Abbildung 1B) in den Trials & Conditions mit jeder Faktor-Kombination. Wie dargestellt, führt dies zu allen möglichen Kombinationen von Wort/Nichtwort X semantischer Verwandtschaft. Außerdem können wir die Anzahl der Versuche pro Bedingung bestimmen, und wir werden 5 Versuche pro Bedingung festlegen - insgesamt 20 Versuche.
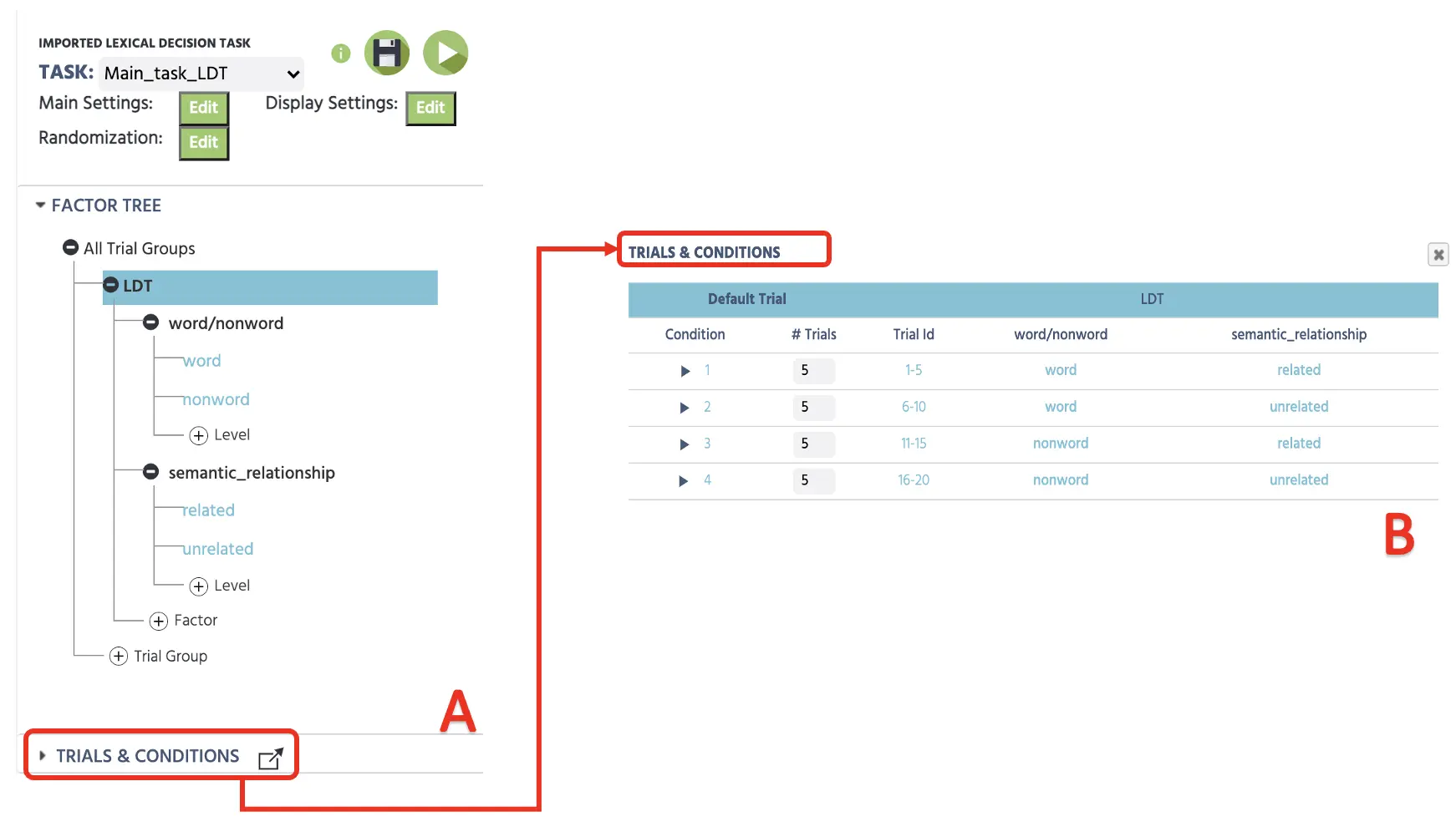 Abbildung 1. Ursprünglicher Canvas-Aufbau, der die Bestimmung von Faktoren mit Stufen im Faktorenbaum (A) und die anschließend kombinierte Darstellung mit 4 Versuchen in jeder Bedingung (B) veranschaulicht.
Abbildung 1. Ursprünglicher Canvas-Aufbau, der die Bestimmung von Faktoren mit Stufen im Faktorenbaum (A) und die anschließend kombinierte Darstellung mit 4 Versuchen in jeder Bedingung (B) veranschaulicht.
Für die Trial-Randomisierung wird Labvanced die Präsentation der Versuche je nach Randomization Setting variieren (siehe Abbildung 2). Der konventionelle Ansatz besteht darin, mit der ersten Random-Option fortzufahren, die eine zufällige Versuchsequenz generieren wird, dies könnte jedoch im Rahmen derselben Einstellung im Voraus festgelegt werden (Fixed by Design oder Hand). Für den Moment wird der aktuelle Aufbau mit Random fortgesetzt, ohne Einschränkungen, um die Versuchsequenz zufällig zu variieren. Für weitere Informationen zu den Randomization-Einstellungen nutzen Sie bitte diesen Link für Weitere Informationen.
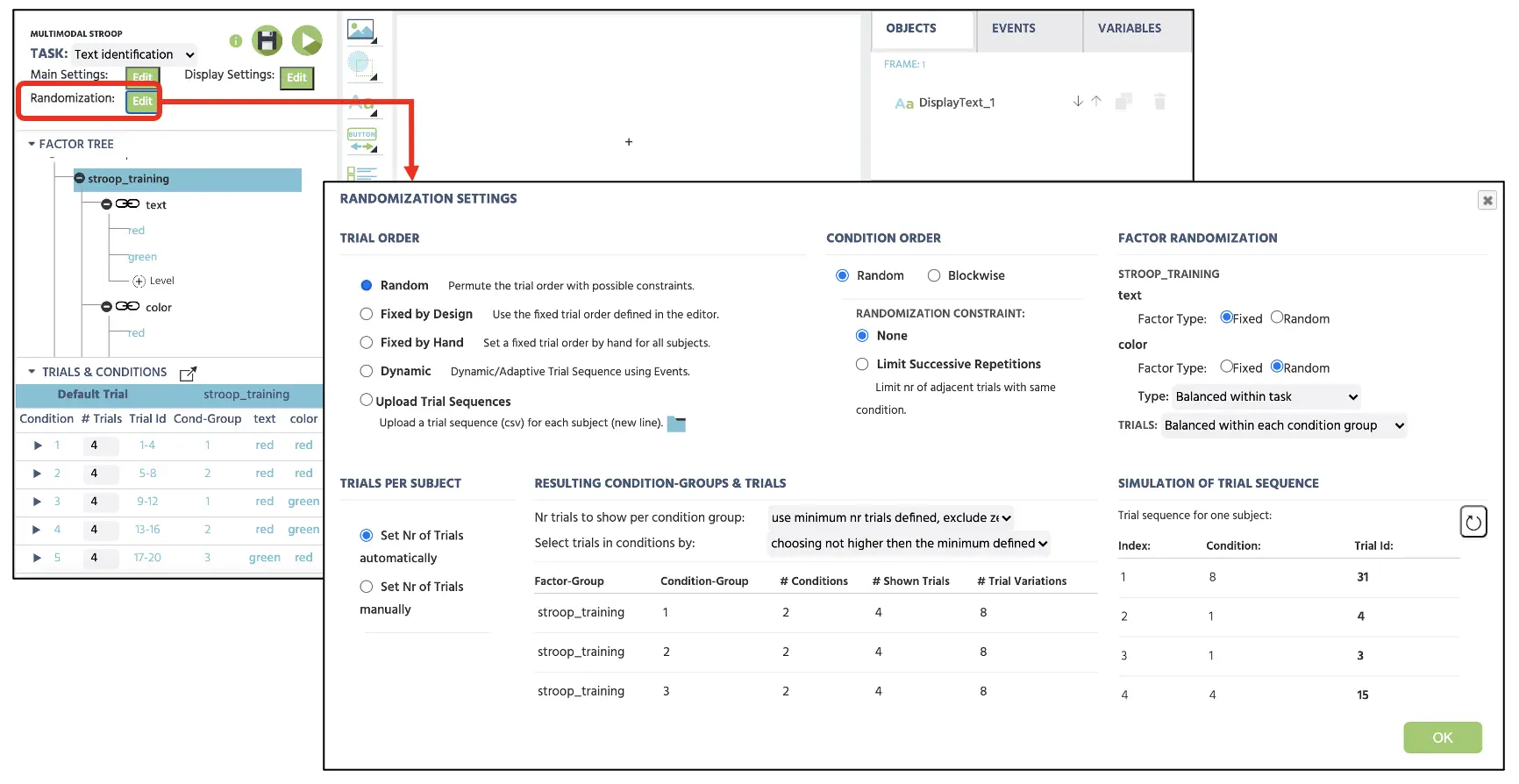 Abbildung 2. Darstellung der Randomization-Einstellung mit ausgewählter Random-Option, um die Versuche ohne Einschränkungen zufällig zu präsentieren.
Abbildung 2. Darstellung der Randomization-Einstellung mit ausgewählter Random-Option, um die Versuche ohne Einschränkungen zufällig zu präsentieren.
Teil II: Einrichtung der Frames
Der zweite Teil dieses Leitfadens wird Frames (Stimuli-Präsentation) erstellen, die die Teilnehmer während ihrer Studienteilnahme sehen werden. Insgesamt wird die aktuelle LDT dem allgemeinen Verfahren folgen (siehe Abbildung 3). Wie dargestellt, beginnt ein Versuch mit einem Fixationskreuz (Frame 1) für 500 ms, gefolgt von der Präsentation von zwei Wörtern (Frame 2). Der Teilnehmer muss „Y“ drücken, wenn er feststellt, dass beide echte Wörter sind, oder „N“, wenn mindestens eines der Wörter kein echtes Wort ist. Der Tastendruck wird gefolgt von den Feedback-Nachrichten: Korrekt (Frame 3) oder Falsch (Frame 4). Das Feedback wird für 1000 ms angezeigt.
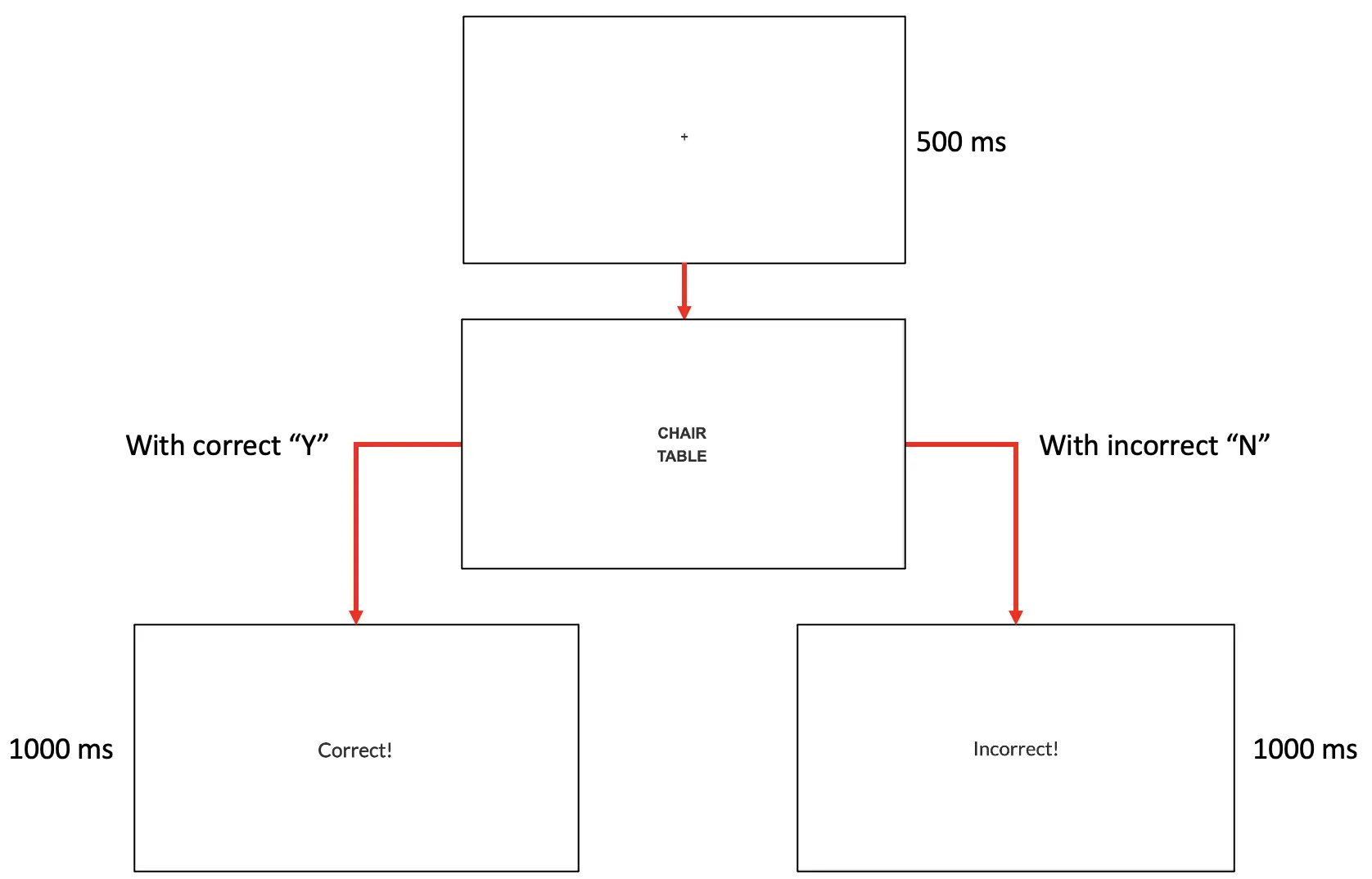 Abbildung 3. Darstellung eines Beispielversuchs. In diesem Beispiel zeigt die Präsentation sowohl echte Wörter mit verwandten Semantiken, dass der Y-Tastendruck mit einer korrekten Antwort assoziiert ist, die anzeigt, dass beide Wortstimuli echte Wörter sind, und der N-Tastendruck mit der falschen Antwort assoziiert ist, die zu der falschen Feedback-Nachricht führt.
Abbildung 3. Darstellung eines Beispielversuchs. In diesem Beispiel zeigt die Präsentation sowohl echte Wörter mit verwandten Semantiken, dass der Y-Tastendruck mit einer korrekten Antwort assoziiert ist, die anzeigt, dass beide Wortstimuli echte Wörter sind, und der N-Tastendruck mit der falschen Antwort assoziiert ist, die zu der falschen Feedback-Nachricht führt.
Der Aufbau dieser Frames beginnt mit einem Klick auf die Canvas-Schaltfläche am unteren Rand der Labvanced-Darstellung (siehe Abbildung 4A). Das viermalige Klicken zeigt 4 neue Frames an, und es wäre ideal, jeden Frame sofort zu benennen (z. B. Fixation, Ziel, Korrekt, Falsch), um die Organisation der Studie aufrechtzuerhalten (siehe Abbildung 4B). Bevor wir fortfahren, wäre es wichtig, auf den Default Trial zu klicken, um sicherzustellen, dass diese Zeile hervorgehoben ist (siehe Abbildung 4C). Dieser Teil dient als Standardvorlage für alle nachfolgenden Bedingungen. Während hervorgehoben, gelten alle Änderungen in den 4 Frames für alle Bedingungen, sodass dies bequem ist, um unnötige und sich wiederholende Setups zu vermeiden. Wenn wir beispielsweise das Fixationskreuz für eine bestimmte Dauer hinzufügen, wird dieselbe Präsentation auf alle 48 Versuche in den Trials und Conditions angewendet.
 Abbildung 4. Darstellung eines Beispielversuchs mit der Canvas-Frame-Erstellung (A), der Option zur Änderungsbenennung des Frames (B) und der Hervorhebung des Default Trials (C).
Abbildung 4. Darstellung eines Beispielversuchs mit der Canvas-Frame-Erstellung (A), der Option zur Änderungsbenennung des Frames (B) und der Hervorhebung des Default Trials (C).
Um das Fixationskreuz im ersten Frame zu erstellen, können wir auf die Display Text-Option klicken (siehe Abbildung 5A), um das Textfeld in der Canvas zu implementieren. Hier können wir das + im Feld mit einer Schriftgröße von 36 eingeben und in der Mitte der Darstellung positionieren. Wir könnten auch die spezifischen X- & Y-Frame-Koordinaten in den Object Properties auf der rechten Seite für die genaue Mittelposition eintippen. Wenn wir das Bild hochladen möchten, das das Fixationskreuz oder verschiedene Stimuli enthält, kann die Media-Option (siehe Abbildung 5B) Bilder, Videos, Audios usw. anzeigen.
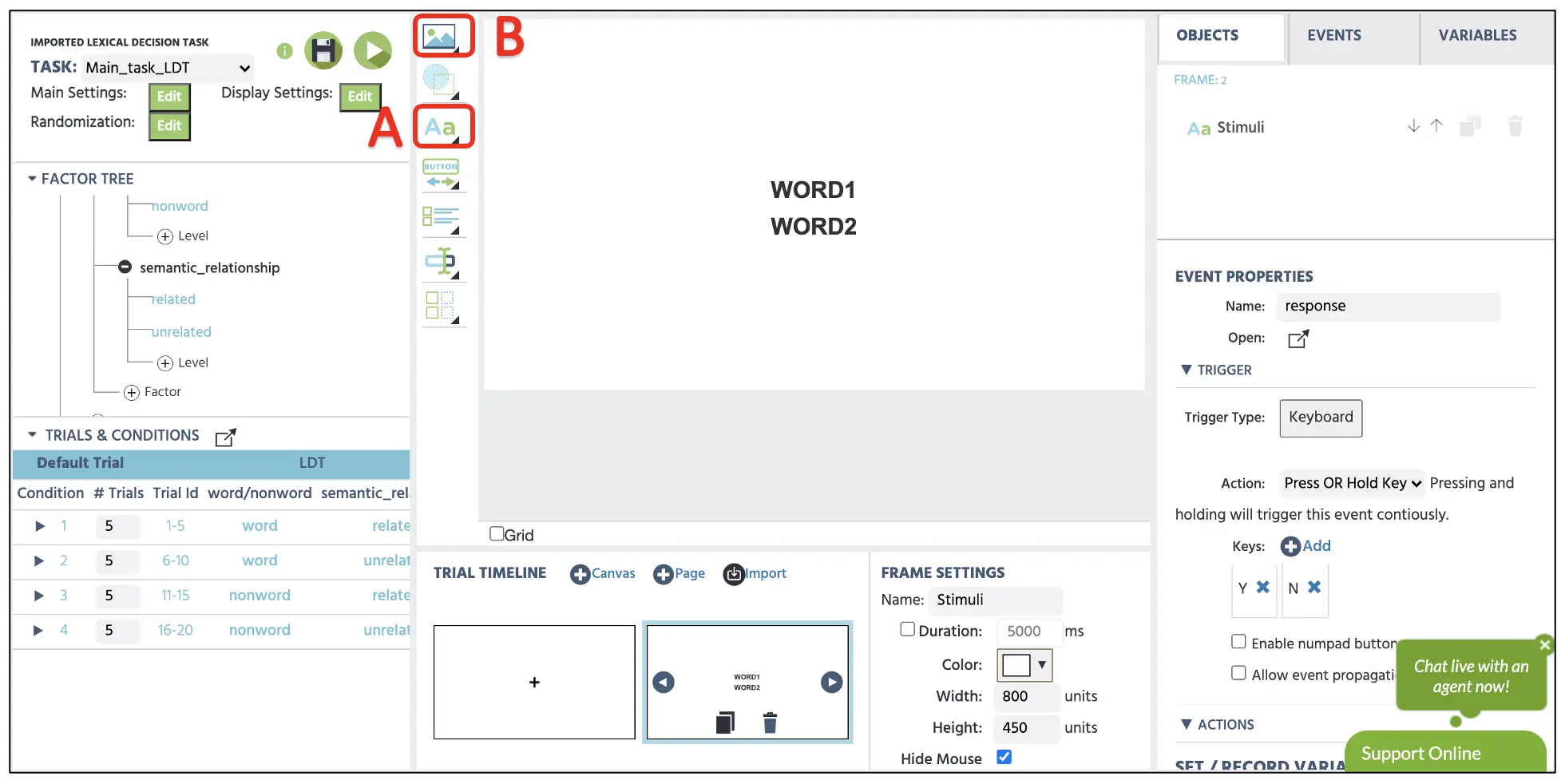 Abbildung 5. Darstellung der Erstellung des Fixationsrahmens mit der Display Text-Option (A). Bilder, Videos und Audios können über die Media-Option (B) präsentiert werden.
Abbildung 5. Darstellung der Erstellung des Fixationsrahmens mit der Display Text-Option (A). Bilder, Videos und Audios können über die Media-Option (B) präsentiert werden.
Die Erstellung der Feedback-Nachrichten (Frame 3: Korrekt; Frame 4: Falsch) erfolgt im gleichen Prozess wie das Fixationskreuz, wobei die Nachrichten in das Textfeld eingegeben werden können, wobei eine Positionierungsoption in der Mitte der Darstellung verfügbar ist (siehe Abbildung 6). Mit den Frames 1, 3 und 4 hinter uns wird der nächste Teil des Leitfadens die Zielerstellung im Frame 2 betreffen.
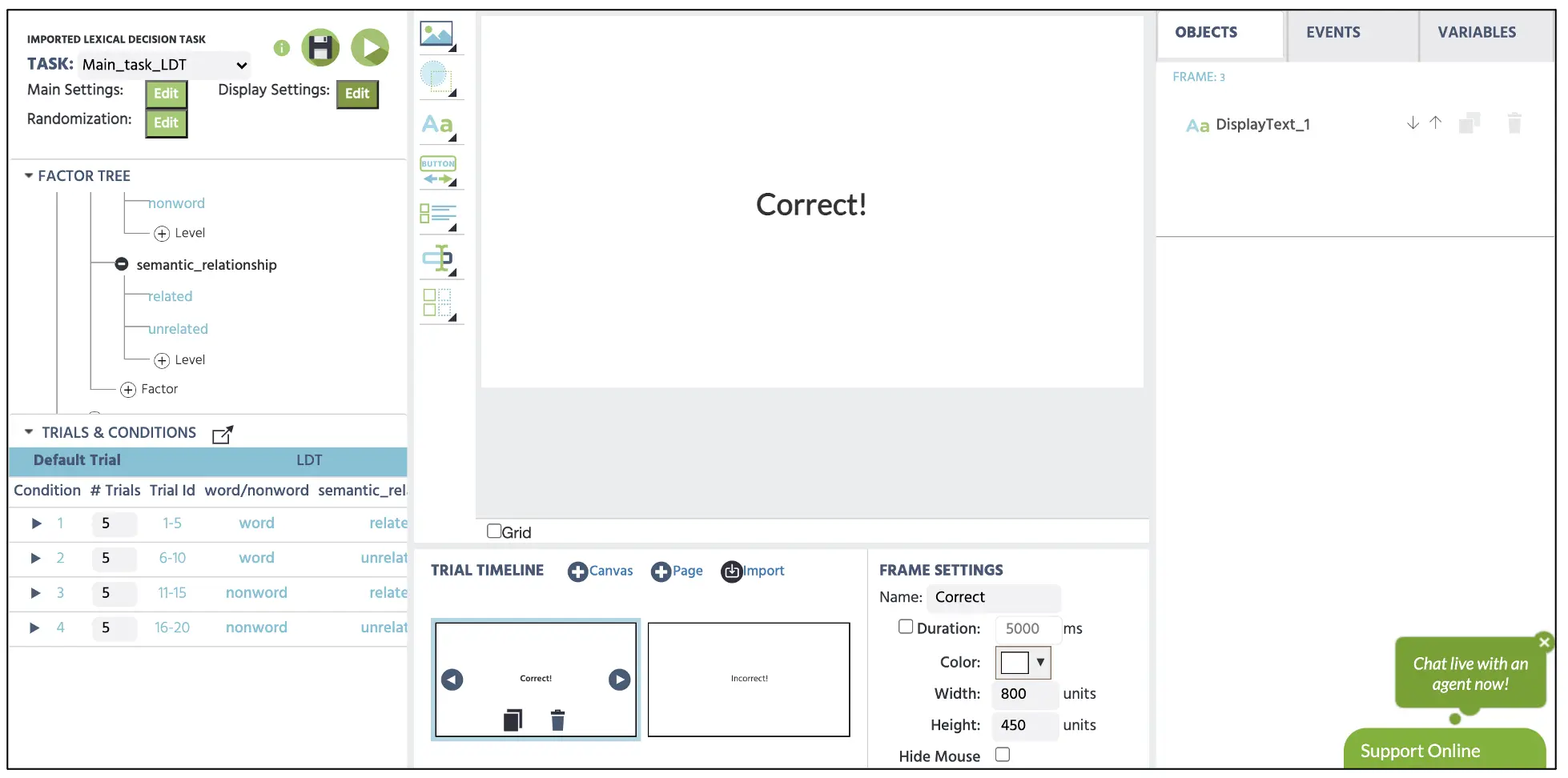 Abbildung 6. Beispieldarstellung des korrekten Feedbacks in Frame 3.
Abbildung 6. Beispieldarstellung des korrekten Feedbacks in Frame 3.
Teil III: Einrichtung der Stimuli
Um Frame 2: Wortpräsentation zu erstellen, beginnen wir mit einem Klick auf die Display Text-Option (siehe Abbildung 5 oben). Dies wird das Textfeld aufrufen, in das wir die Wörter eintippen und die Größe sowie die Platzierung über die Object Properties auf der rechten Seite anpassen können.
Wichtig ist, dass wir sicherstellen möchten, dass die richtigen Textpaare je nach entsprechender Bedingung angezeigt werden. Dies kann mithilfe der Trials und Conditions referenziert werden, die wir bereits in Teil I erstellt haben. Zum Beispiel, in der ersten Bedingung möchten wir sicherstellen, dass das Textpaar echte Wörter enthält, die semantisch miteinander verwandt sind (z. B. STUHL & TISCH; Abbildung 7). In der zweiten Bedingung präsentieren wir dennoch zwei echte Wortpaare, aber sie werden semantisch unverwandt sein. Daher können wir diesen Leitfaden für die Trials und Conditions für die Einrichtung der Stimuli referenzieren und sicherstellen, dass alle möglichen Bedingungen in unserer Studie berücksichtigt werden.
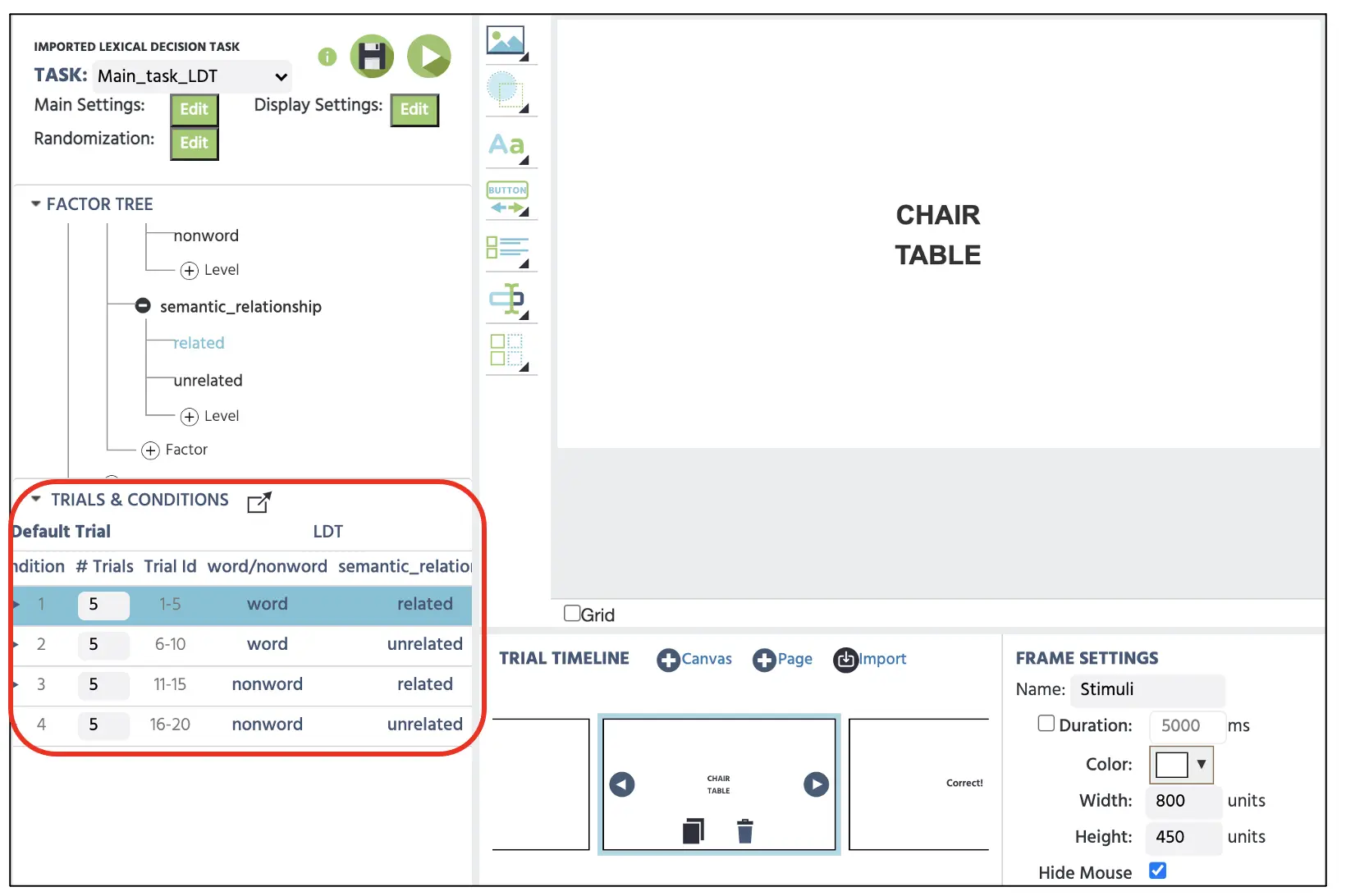 Abbildung 7. Darstellung der Canvas-Darstellung der Frame 2 Stimuli-Präsentation. Nach der ersten Bedingung im roten Kästchen zeigt dieser Versuch ein echtes Wortpaar mit semantischer Verwandtschaft. In einem solchen Versuch würde ein Y-Tastendruck (ja) mit der korrekten Antwort assoziiert werden.
Abbildung 7. Darstellung der Canvas-Darstellung der Frame 2 Stimuli-Präsentation. Nach der ersten Bedingung im roten Kästchen zeigt dieser Versuch ein echtes Wortpaar mit semantischer Verwandtschaft. In einem solchen Versuch würde ein Y-Tastendruck (ja) mit der korrekten Antwort assoziiert werden.
Der nächste Teil wird die Einrichtung des Ereignissystems mit dem Abschluss des Frame-Setups bei jeder Stimuli-Präsentation betreffen. Hier werden wir das Labvanced-Programm anweisen, der logischen Reihenfolge zu folgen, wie die Frames mit den jeweiligen Stimuli für eine bestimmte Dauer angezeigt werden sollen und wichtige Informationen wie Reaktionszeiten (ms) und korrekte Antworten zu protokollieren.
Teil IV: Einrichtung der Ereignisse
Bevor wir das Ereignissystem erstellen, müssen zwei neue Variablen (Reaktionszeit und korrekte Antwort) erstellt werden, um als abhängige Variablenmessungen zu dienen. Um neue Variablen zu erstellen, können wir auf die Variablen in der oberen rechten Anzeige klicken und Variable hinzufügen auswählen (siehe Abbildung 8). Aus dem neuen Variablenfenster werden wir mit den folgenden Schritten für die Namen und Typen fortfahren. Diese Variablen speichern wichtige Verhaltensmessungen darüber, wie schnell der Teilnehmer das Ziel identifiziert und deren jeweilige Genauigkeit bei der Leistung. Daher werden die beiden neuen Variablen sein:
- Reaktionszeit - gemessen in Millisekunden ab dem Frame-Beginn
- Korrekt - Antwortgenauigkeit (1=korrekt; 0=inkorrekt)
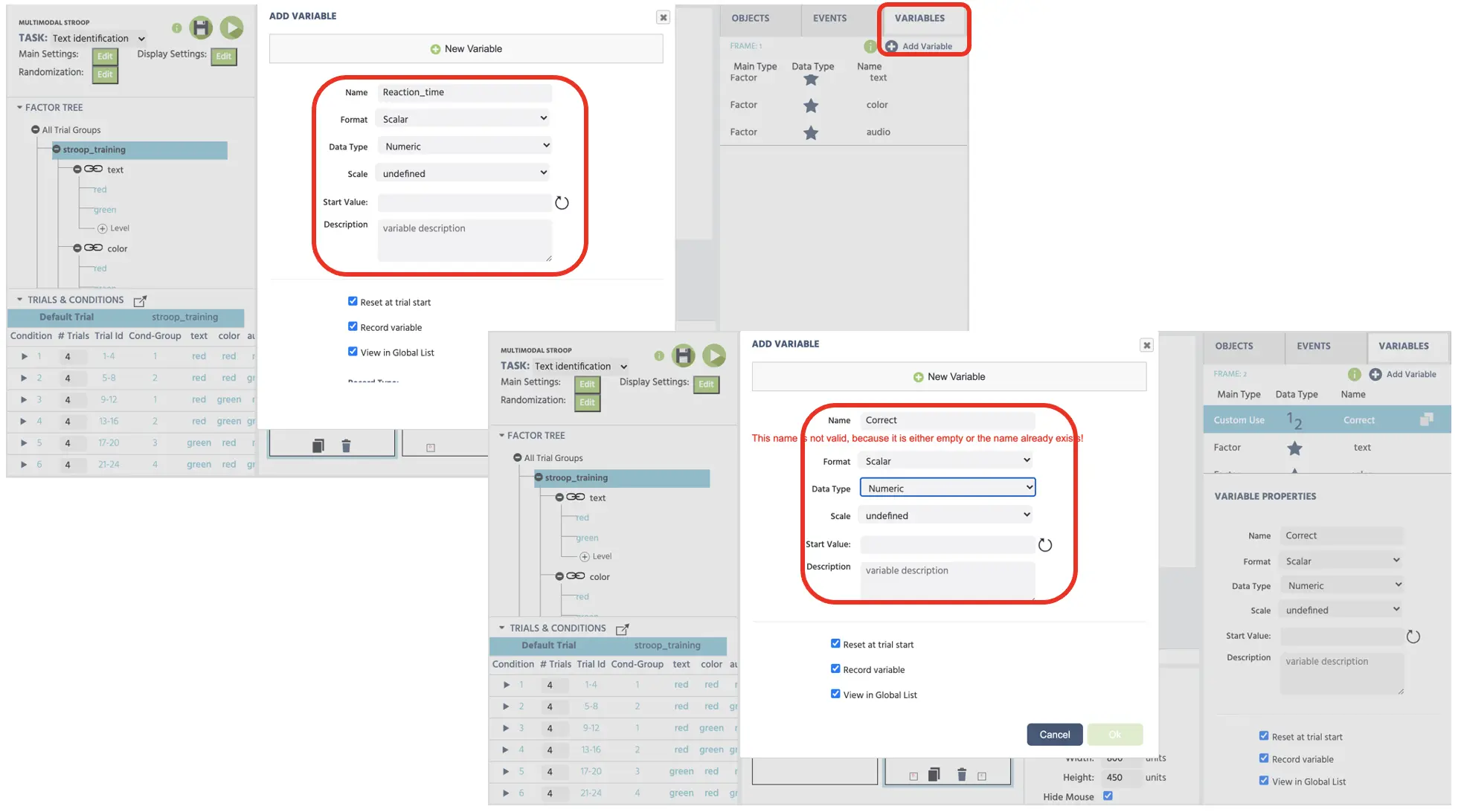 Abbildung 8. Darstellung der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp festgelegt.
Abbildung 8. Darstellung der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp festgelegt.
Folgend der allgemeinen Frame-Reihenfolge aus Teil II (siehe Abbildung 3 oben) wird der Rest des Ereignis-Setups in 4 Abschnitte unterteilt, um den Aufbau für jeden Frame detailliert zu erläutern.
Frame 1 Ereignisse: Fixationskreuz
In diesem Frame möchten wir das Fixationskreuz in der Mitte der Präsentation für 500 ms anzeigen. Daher wird die logische Reihenfolge, die wir anstreben, sein:
- Sobald der Frame beginnt
- 500 ms warten
- Und dann zum nächsten Frame wechseln
Um dies in Ereignissen umzusetzen, klicken Sie auf die Ereignisse oben rechts neben den Variablen und wählen Sie Frame Event (nur in diesem Frame). Im ersten Dialogfenster können wir die Ereignisse als „Start“ benennen und auf Weiter klicken, um zur Trigger-Option zu gelangen. Hier ist der Trigger-Typ Trial und Frame Trigger → Frame Start (entsprechend der ersten logischen Reihenfolge oben). Mit diesem Trigger möchten wir die 500 ms Frameverzögerungsaktion initiieren (2. logische Reihenfolge); daher kann dies mit Add Action → Delayed Action (Time callback) eingestellt werden, und setzen Sie 500 ms in das Verzögerungsfeld (siehe Abbildung 9). Schließlich, um die letzte logische Reihenfolge auszuführen, klicken Sie im Aktionssequenzfeld auf Add Action und fahren Sie fort mit Jump Action → Jump to → wählen Sie Next Frame (siehe Abbildung 9). Labvanced wird immer dieser logischen Reihenfolge für die Präsentation des Fixationskreuzes für alle Versuche mit diesem Setup folgen.
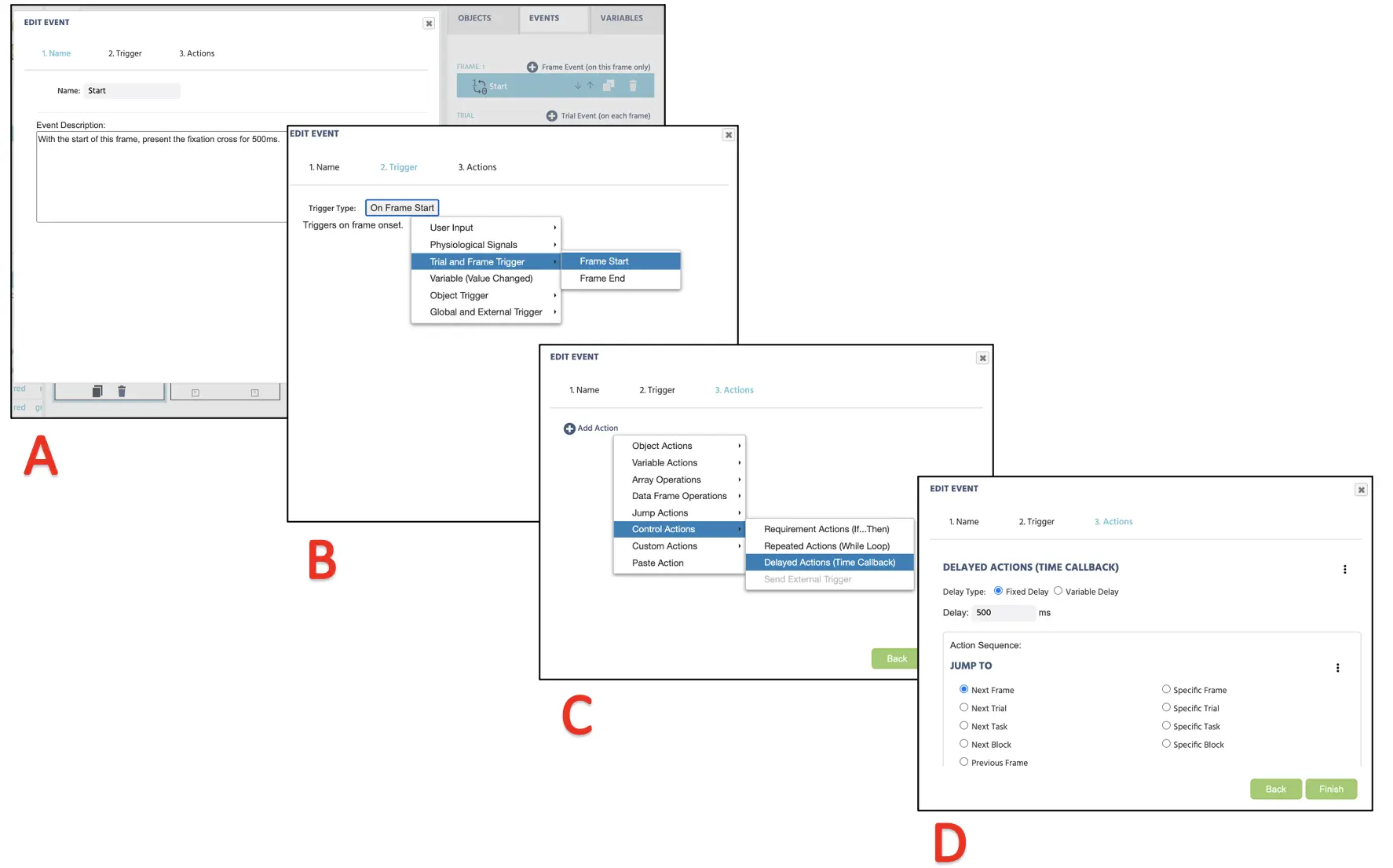 Abbildung 9. Darstellung der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) entsprechend der Ereignisbenennung (A), Trigger (B), Aktionsbestimmung (C) und gewünschter Aktionsausführung.
Abbildung 9. Darstellung der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) entsprechend der Ereignisbenennung (A), Trigger (B), Aktionsbestimmung (C) und gewünschter Aktionsausführung.
Frame 2 Ereignisse: Zielpräsentation und Reaktionsaufzeichnung
Wie bereits erwähnt, erfordert die Aufgabe von den Teilnehmern, das Wortpaar so schnell und genau wie möglich zu bewerten und zu bestimmen, ob beide echte Wörter sind. Daher werden wir den y-Tastendruck als „ja“-Antwort (beide sind echte Wörter) und den n-Tastendruck als „nein“ (mindestens eines ist kein echtes Wort) zuweisen. Um dieses bedingte Argument in Labvanced zu konstruieren, können wir die Textspalte in den Trials & Conditions verwenden, um zu bestimmen, ob der Tastendruck des Teilnehmers mit dem zugehörigen Versuch übereinstimmt. Dies würde das bedingte Argument ermöglichen und die korrekte Variable mit der jeweiligen Korrekt-/Inkorrrektmessung aufzeichnen. Daher würde dieser Frame aus folgender logischer Reihenfolge bestehen:
- Sobald der Frame beginnt
- Die Wörter präsentieren
- Wenn die Tasteneingabe korrekt ist → Korrekt = 1 aufzeichnen → Zum korrekten Feedback springen (Frame 3)
- Wenn die Tasteneingabe inkorrekt ist → Korrekt = 0 aufzeichnen → Zum inkorrekten Feedback springen (Frame 4)
Um dieses Ereignis zu erstellen, beginnen wir erneut mit einem Klick auf Ereignisse und wählen Frame Event (nur in diesem Frame). Bevor wir fortfahren, stellen Sie sicher, dass der Default Trial hervorgehoben ist, sodass die Ereignisse auf jeden Versuch angewendet werden. Da dieses Ereignis den Tastendruck des Teilnehmers anzeigt, wäre der Trigger die Benutzerinteraktion → Tastaturtrigger. Hier können wir zwei mögliche Tasteneingaben festlegen (siehe Abbildung 10), nämlich „Y“ und „N.“ Nach dem Klicken auf Weiter wird die Aktionssequenz mit Steueraktionen → Bedingungsaktionen (If...then) fortgesetzt.
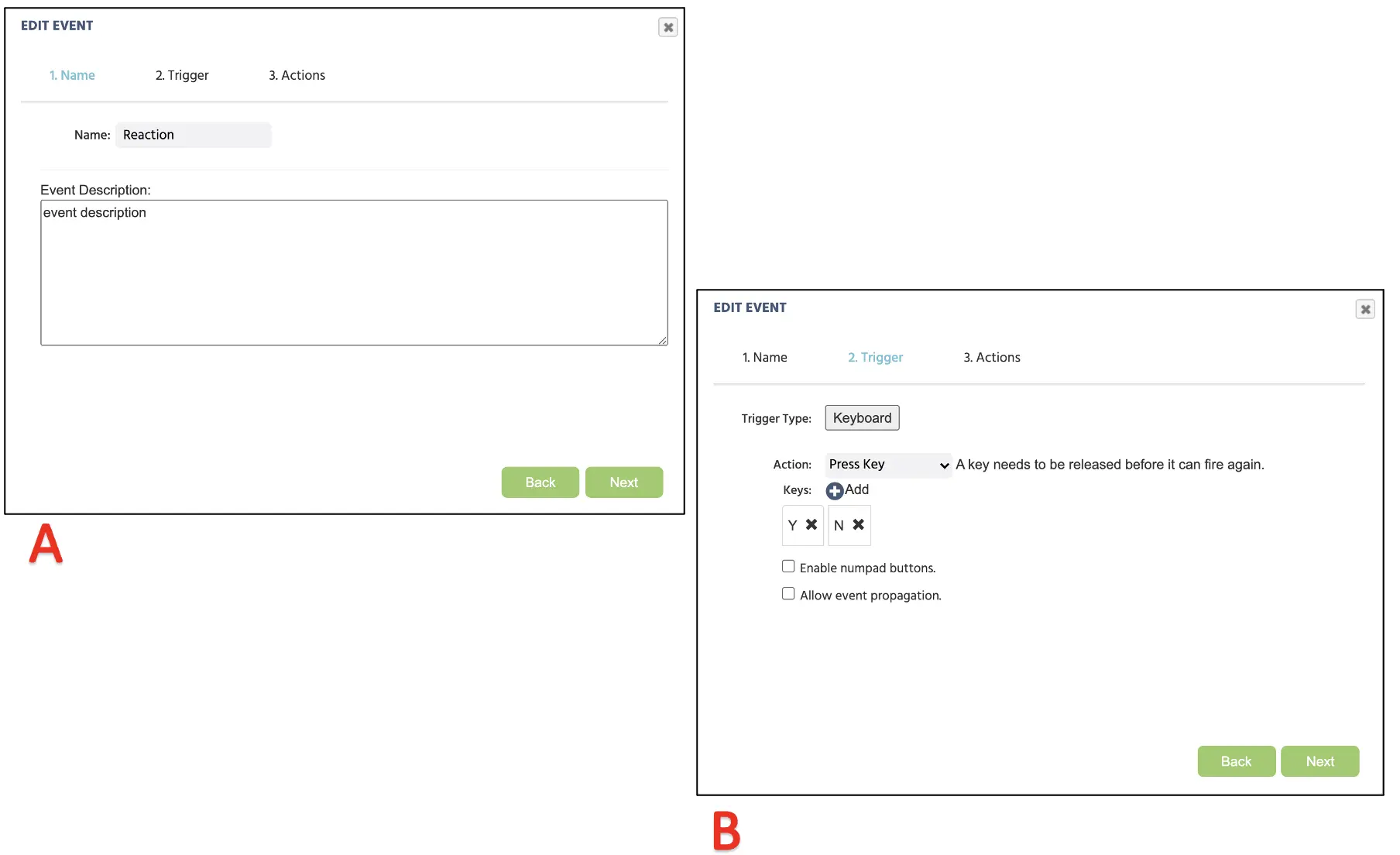 Abbildung 10. Darstellung der Ereigniserstellung für die Zuordnung der Tasteneingaben entsprechend der Ereignisbenennung (A), der Zuordnung des Triggers mit zulässigen Tasteneingaben (B).
Abbildung 10. Darstellung der Ereigniserstellung für die Zuordnung der Tasteneingaben entsprechend der Ereignisbenennung (A), der Zuordnung des Triggers mit zulässigen Tasteneingaben (B).
Bei dem If-Teil dieses Dialogs werden wir die korrekt/inkorrekt-Bedingung mit dem Ziel und der zugehörigen Tasteneingabe festlegen. Hier können wir den linken Teil als Textvariable festlegen (siehe Abbildung 11) und die rechte Seite, indem wir eine "Wort"-Zeichenfolge eingeben. Direkt darunter benötigen wir eine weitere Bedingung und setzen die linke Seite Trigger(tastatur) → ID der Taste. Dann können wir auf der rechten Seite den Buchstaben „Y“ eingeben (stellen Sie sicher, dass dieser großgeschrieben ist).
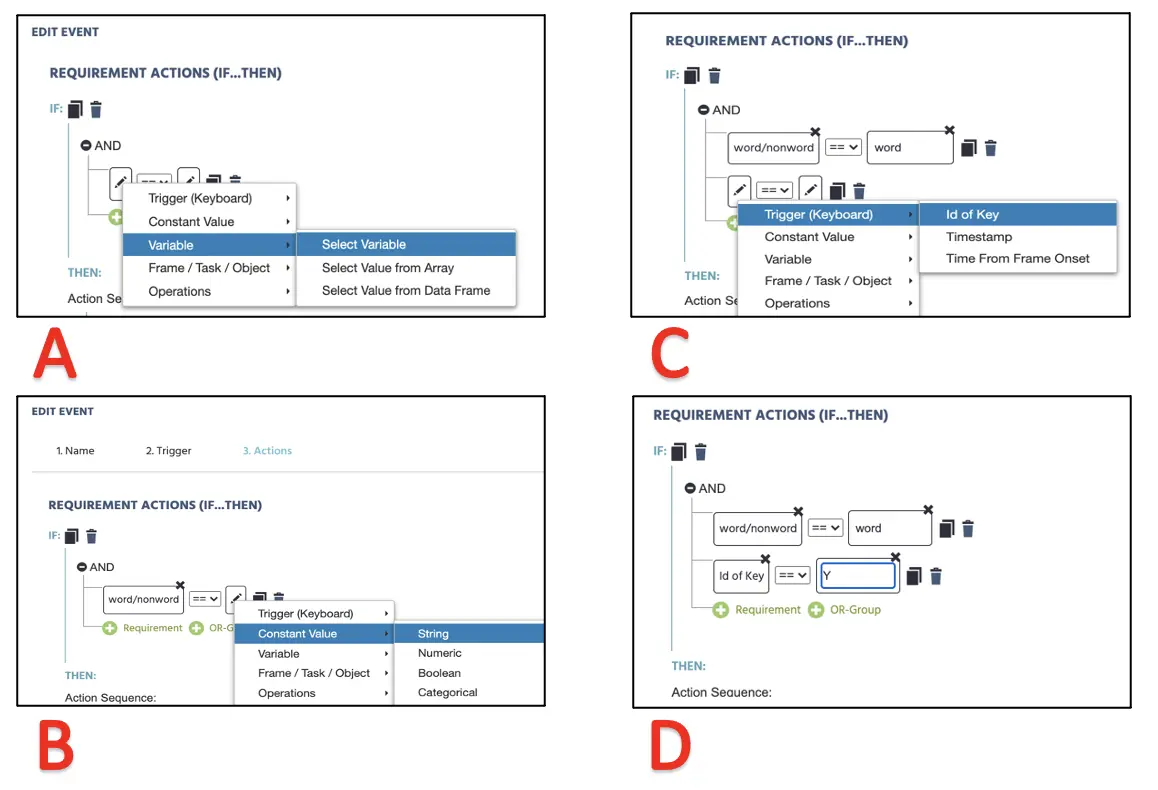 Abbildung 11. Darstellung der Ereigniserstellung für die Zuordnung der Tasteneingaben entsprechend der Variablenbestimmung (A), der zugehörigen Bedingung (B) und der Bewertung der Tasteneingabeantwort (C & D).
Abbildung 11. Darstellung der Ereigniserstellung für die Zuordnung der Tasteneingaben entsprechend der Variablenbestimmung (A), der zugehörigen Bedingung (B) und der Bewertung der Tasteneingabeantwort (C & D).
Fortfahrend zum Then-Teil weiter unten möchten wir die Aktion des Programms basierend auf der oben festgelegten IF-Bedingung festlegen. Da die „Y“-Taste die korrekte Antwort ist, wenn die Textpaare echte „Wörter“ sind, möchten wir dies als korrekt in der Variablen Korrekt festlegen und die korrekte Rückmeldung anzeigen. Um dies zu tun, können wir die Variable Korrekt auf der linken Seite festlegen/aufzeichnen und die ganze Zahl 1 auf der rechten Seite eingeben (siehe Abbildung 12). Direkt darunter klicken Sie auf die Schaltfläche Add Action, um eine Jump Action hinzuzufügen (ähnlich wie beim Fixationsrahmen), aber diesmal möchten wir die spezifische Rahmen (Korrekt) auswählen, um die „Korrekt“-Feedbacknachricht anzuzeigen. Damit haben wir die bedingte Reihenfolge festgelegt, um das Labvanced-Programm anzuweisen, die Antwort des Teilnehmers als korrekt zu protokollieren, wenn der D-Tastendruck mit der Präsentation der „roten“ Textdarstellung gemacht wurde.
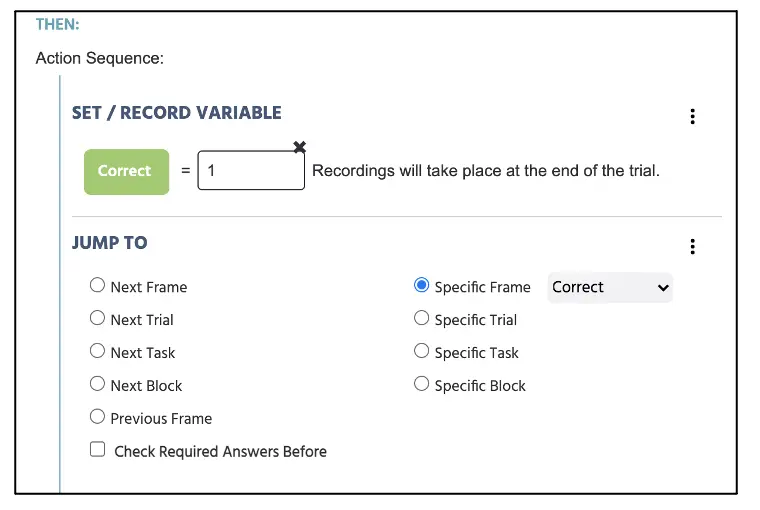 Abbildung 12. Darstellung der Ereigniserstellung gemäß Abbildung 12. Das Set/Record bestimmt die Korrekt-Variable mit 1 = korrekt (0, wenn anders) wenn die Bedingungen mit dem Aufbau in Abbildung 12 erfüllt sind.
Abbildung 12. Darstellung der Ereigniserstellung gemäß Abbildung 12. Das Set/Record bestimmt die Korrekt-Variable mit 1 = korrekt (0, wenn anders) wenn die Bedingungen mit dem Aufbau in Abbildung 12 erfüllt sind.
Indem wir das gleiche Verfahren replizieren, müssten wir auch die Bedingung für den Text „Nichtwort“ mit der korrekten Tasteneingabe erstellen (siehe Abbildung 13A). Schließlich können wir dann auf Else klicken, um die final Set/Record-Variable hinzuzufügen: Korrekt auf 0 mit einer inkorrekten Antwort zu setzen und zu dem inkorrekten Feedback-Frame zu führen (siehe Abbildung 13B). Dieses finale Argument bezieht sich darauf, dass, wenn die Tasteneingabeantwort nicht den beiden vorherigen korrekten Argumenten entspricht, wir das Programm anweisen, dies als inkorrekt (0) aufzuzeichnen.
 Abbildung 13. Darstellung der Ereigniserstellung gemäß Abbildung 13, die den Prozess für die grüne Textbedingung repliziert (A) und die inkorrekte (0) Antwort festlegt, wenn keine der korrekten Bedingungen erfüllt ist.
Abbildung 13. Darstellung der Ereigniserstellung gemäß Abbildung 13, die den Prozess für die grüne Textbedingung repliziert (A) und die inkorrekte (0) Antwort festlegt, wenn keine der korrekten Bedingungen erfüllt ist.
Frames 3 & 4 Ereignisse: Feedbackpräsentation
Die Ereignisse in den Feedback-Frames, die korrekte (Frame 3) und inkorrekte (Frame 4) Nachrichten enthalten, spiegeln denselben Prozess wie der Fixationsrahmen wider. Welchen Tastendruck der Teilnehmer auch macht, wir möchten das Feedback in der Mitte der Anzeige für 1000 ms präsentieren und dann zum nächsten Versuch übergehen. Daher wird die logische Reihenfolge, die wir anstreben, sein:
- Sobald der Frame beginnt
- 1000 ms warten
- Und dann zum nächsten Versuch springen
Um dies in Ereignissen umzusetzen, klicken Sie auf die Ereignisse oben rechts neben den Variablen und wählen Sie Frame Event (nur in diesem Frame). Im ersten Dialogfenster können wir die Ereignisse als „Start“ benennen und auf Weiter klicken, um zur Trigger-Option zu gelangen. Der Trigger-Typ ist Trial und Frame Trigger → Frame Start (entsprechend der 1. logischen Reihenfolge oben). Mit diesem Trigger möchten wir die 1000 ms Frameverzögerungsaktion initiieren (2. logische Reihenfolge); daher kann dies mit Add Action → Delayed Action (Time callback) eingestellt werden, und setzen Sie 1000 ms in das Verzögerungsfeld. Schließlich, um die letzte logische Reihenfolge auszuführen, klicken Sie auf Add Action im Aktionssequenzfeld und fahren Sie fort mit Jump Action → Jump to → wähle den nächsten Versuch. Mit diesem Setup wird Labvanced immer dieser logischen Reihenfolge für die Feedbackpräsentation für beide Frames 3 & 4 in allen Versuchen folgen. Im Allgemeinen spiegelt dieser Schritt dasselbe Verfahren und dieselben Abbildungen wider, die als Referenz verwendet werden könnten.
Letzte Anmerkung
Mit diesem letzten Setup haben wir jetzt eine funktionsfähige LDT, die aus 20 Versuchen in diesem Block besteht. Abhängig von der Studie müssen Forscher möglicherweise mehrere Sets oder Blöcke von 20 Versuchen den Teilnehmern für ihre theoretische Untersuchung präsentieren. Glücklicherweise ermöglicht Labvanced die Organisation der Studie auf der Seite Studiendesign, um verschiedene Blöcke zu organisieren (siehe Abbildung 15). Das Einzige, was in diesem Leitfaden noch bleibt, sind das Einverständnisformular, das Instruktionsdokument, demografische Fragen und andere Protokolle, die jedoch je nach Forscher und Institution variieren, um diesen Leitfaden abzuschließen. Für weitere Informationen zur Texterstellung besuchen Sie bitte unsere Ressourcen link für zusätzliche Informationen. Darüber hinaus ist die erstellte LDT-Vorlage auch in unserer Bibliothek über diesen link verfügbar, zusammen mit anderen experimentellen Paradigmen. Damit wünschen wir Ihnen alles Gute bei Ihren wissenschaftlichen Bemühungen und hoffen, dass dieser Leitfaden als wichtiger Grundstein für Ihre Studienkonstruktion dient.