Stroop-Aufgaben-Erstellung Leitfaden
Hallo! Willkommen zu einem weiteren Leitfaden zur Erstellung von Studien. Diese Informationen enthalten den Aufbau eines der häufig verwendeten psychologischen Experimente, der Stroop-Aufgabe. Kurz gesagt, die Stroop-Aufgabe präsentiert ein Farbwort mit übereinstimmender Tintenfarbe (d.h. Text „Rot“ mit roter Tinte) oder nicht übereinstimmender Tintenfarbe (d.h. Text „Rot“ mit grüner Tinte), und der Teilnehmer muss selektiv aufmerksam sein und zwischen der Tinte oder dem Text unterscheiden (d.h. rotes oder grünes Text in bestimmten Versuchen und Tintenfarbe in anderen unterscheiden). Üblicherweise zeigt der Befragte eine geringere Leistung (z.B. langsamere Unterscheidung und weniger Genauigkeit durch Tastendruck) im nicht übereinstimmenden Zustand im Vergleich zum übereinstimmenden Wort aufgrund des Informationswettbewerbs (d.h. der Diskrepanz zwischen dem Text und der Tintenfarbe). Kritisch wird die Verzögerung bei der nicht übereinstimmenden Antwort als die Aufmerksamkeit (oder kognitive) Kontrolle operationalisiert, um die verschiedenen Populationen zu bewerten, wie z.B. Personen mit intensiver Spielerfahrung, mono- vs. multilingual und aufmerksamsfordernde Berufe (z.B. Luftverkehrskontrolle) um ihre Interferenzkontrolle zu untersuchen. Für praktische klinische Anwendungen wird das Stroop-Paradigma verwendet, um die Aufmerksamkeitsdefizite und kognitiven Fähigkeiten verschiedener psychologischer Störungen wie Schizophrenie, bipolare Störung oder schwere Depressionen zu bewerten. Die Erstellung dieses Paradigmas in Labvanced ist ein relativ einfacher Prozess im Vergleich zu anderen komplexen experimentellen Designs, aber dieser aktuelle Leitfaden wird den Prozess detailliert in 5 Teilen erklären, die Folgendes umfassen:
- Variablenbestimmung (IVs & DVs)
- Frame-Einrichtung (Fixierung, Ziel, Rückmeldemeldungen)
- Stimuli-Einrichtung (visuell & auditiv)
- Ereignis-Einrichtung
- Block-Einrichtung
Um das Paradigma interessanter zu gestalten und die Einrichtung der Audio-Stimuli zu demonstrieren, werden wir das Stroop-Paradigma als multimodale Einrichtung aufbauen, die zwei verschiedene Modalitäten der Stimuli-Präsentation präsentiert: visuelle und auditive Präsentation. Insgesamt wird der aktuelle Leitfaden drei verschiedene Aufgaben erstellen, bei denen die Teilnehmer sich entweder auf Folgendes konzentrieren müssen:
- Text (z.B. Unterscheidung des Texts - rot oder grün, während die präsentierte Textfarbe und gleichzeitig das auditive Wort ignoriert wird)
- Farbe (z.B. Unterscheidung der präsentierten Farbe - rote oder grüne Tinte, während die Textsemantik und das gleichzeitig präsentierte auditive Wort ignoriert werden)
- Auditiv (z.B. Unterscheidung des projizierten Tons - rot oder grün, während die Textsemantik und die präsentierte Farbe ignoriert werden)
Ohne weitere Umschweife, lassen Sie uns mit der Erstellung der ersten Aufgabe beginnen, indem wir die wichtigen Variablen für die Studienstruktur bestimmen.
Teil I: Variablenbestimmung
Wie bei jeder Studienvorbereitung ist die Bestimmung der Variablen für die Studienstruktur wichtig. Dazu könnten wir den Faktorenbaum verwenden, um die Faktoren (oder unabhängigen Variablen) und ihre zugehörigen Levels (oder Kategorien) zu bestimmen. Für die Zwecke der aktuellen multimodalen Stroop-Aufgabe sind die Faktoren und ihre Levels wie folgt:
- Faktor 1 - Text
- Level 1 - grün
- Level 2 - rot
- Faktor 1 - Text
- Faktor 2 - Farbe
- Level 1 - grün gefärbter Text (d.h. grün oder rot)
- Level 2 - rot gefärbter Text (d.h. grün oder rot)
- Faktor 2 - Farbe
- Faktor 3 - Audio
- Level 1 - Audio-Sound mit der Wortpräsentation „grün“
- Level 2 - Audio-Sound mit der Wortpräsentation „rot“
- Faktor 3 - Audio
Die vollständige Anzeige dieses Setups im Faktorenbaum ist auch unten dargestellt (siehe Abbildung 1A). Mit diesem 2 X 2 X 2 orthogonalen Setup wird Labvanced 8 verschiedene Bedingungen erstellen (siehe Abbildung 1B) in den Trials & Conditions mit jeder Faktorenkombination. Wie dargestellt, führt dies zu allen möglichen Kombinationen von Text X Farbe X Audio. Außerdem können wir die Anzahl der Versuche pro Bedingung bestimmen, und wir werden 4 Versuche pro Bedingung festlegen - insgesamt 32 Versuche.
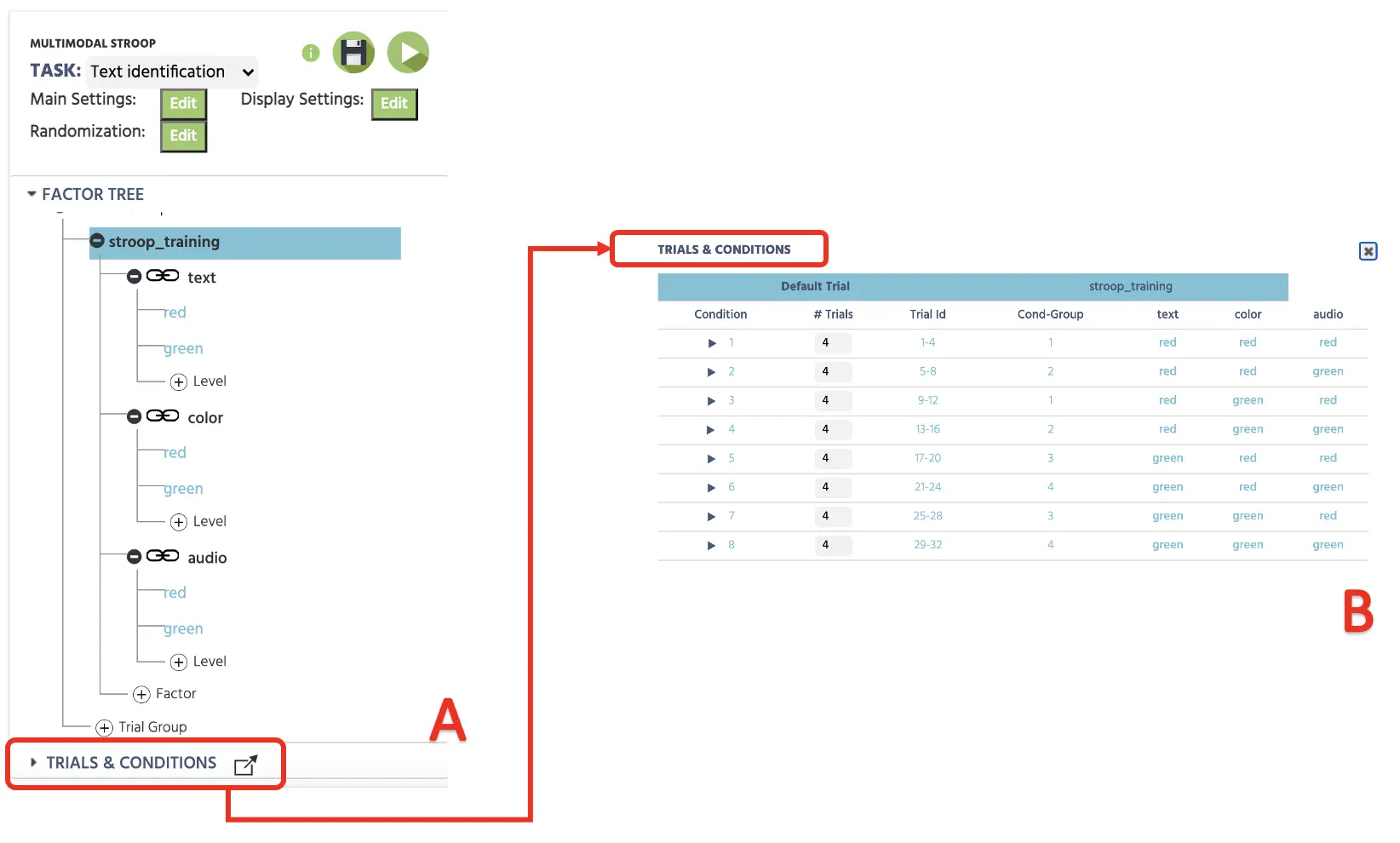 Abbildung 1. Anfängliche Canvas-Einrichtung zeigt die Bestimmung von Faktoren mit Levels im Faktorenbaum (A) und nachfolgende Kombinationen mit 4 Versuchen in jeder Bedingung (B).
Abbildung 1. Anfängliche Canvas-Einrichtung zeigt die Bestimmung von Faktoren mit Levels im Faktorenbaum (A) und nachfolgende Kombinationen mit 4 Versuchen in jeder Bedingung (B).
Bei der Versuchszufälligkeit wird Labvanced die Präsentation der Versuche je nach Randomization Setting variieren (siehe Abbildung 2). Der konventionelle Ansatz besteht darin, mit der ersten Zufallsoption fortzufahren, die eine zufällige Versuchsequenz generiert, jedoch könnte dies mit verschiedenen Optionen ( Fixiert durch Design oder Manuell) im selben Setting vorbestimmt werden. Für den Moment wird das aktuelle Setup mit Random ohne Einschränkungen fortfahren, um die Versuchsequenz zufällig zu variieren. Für weitere Informationen zu den Zufallseinrichtungen verwenden Sie bitte diesen Link für weitere Informationen.
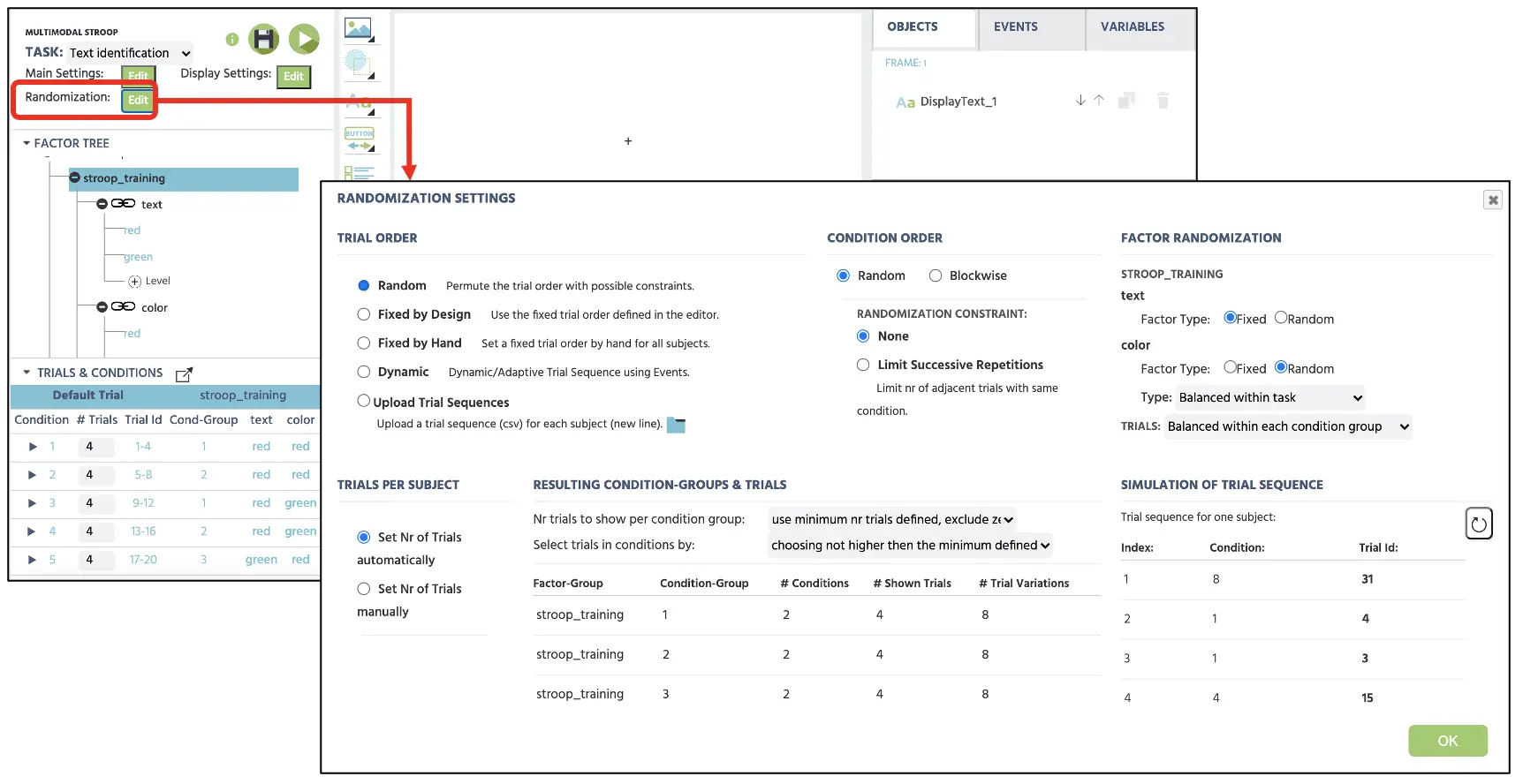 Abbildung 2. Anzeige der Zufallseinrichtung mit ausgewählter Random-Option zur zufälligen Präsentation der Versuche ohne Einschränkungen.
Abbildung 2. Anzeige der Zufallseinrichtung mit ausgewählter Random-Option zur zufälligen Präsentation der Versuche ohne Einschränkungen.
Teil II: Frame-Einrichtung
Der zweite Teil dieses Leitfadens wird Frames erstellen (Stimuli-Präsentation), die die Teilnehmer während ihrer Studienbeteiligung sehen werden. Insgesamt wird die aktuelle multimodale Stroop dem allgemeinen Verfahren unten folgen (siehe Abbildung 3). Wie dargestellt, beginnt ein Versuch mit einem Fixationskreuz (Frame 1) für 500 ms, gefolgt von der gleichzeitigen Präsentation von farbigem Text mit Sound (Frame 2) mit angezeigten Optionen für Tastendrücke. Dies wird gefolgt von Rückmeldemeldungen, Richtig (Frame 3) oder Falsch (Frame 4) Nachrichten, abhängig von der Genauigkeit des Tastendrucks. Die Rückmeldung wird für 1000 ms angezeigt.
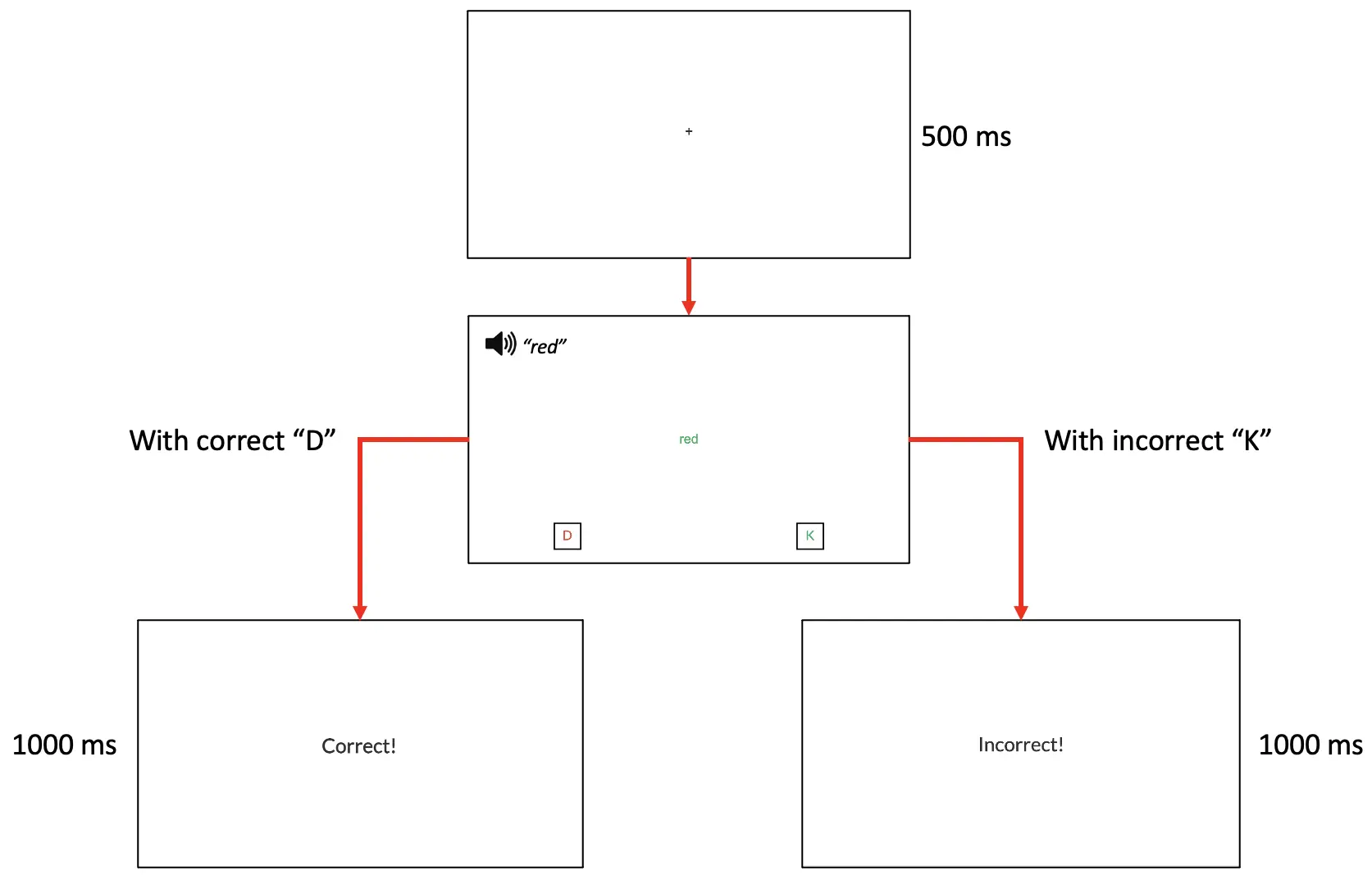 Abbildung 3. Anzeige eines Beispielversuchs. In diesem Beispiel, das eine Textunterscheidung erfordert, während die Farbe und der Ton ignoriert werden, ist der Tastendruck „D“ mit der richtigen Antwort verbunden, die roten Text anzeigt, und der Tastendruck „K“ ist mit der falschen Antwort verbunden, die grünen Text anzeigt.
Abbildung 3. Anzeige eines Beispielversuchs. In diesem Beispiel, das eine Textunterscheidung erfordert, während die Farbe und der Ton ignoriert werden, ist der Tastendruck „D“ mit der richtigen Antwort verbunden, die roten Text anzeigt, und der Tastendruck „K“ ist mit der falschen Antwort verbunden, die grünen Text anzeigt.
Der Aufbau dieser Frames beginnt, indem Sie auf die Canvas-Schaltfläche am unteren Ende der Labvanced-Anzeige klicken (siehe Abbildung 4A). Durch das viermalige Klicken werden 4 neue Frames angezeigt, und es wird sofort ermöglicht, jeden Frame zu benennen (z.B. Fixierung, Ziel, korrekt, falsch), um die Organisation aufrechtzuerhalten (siehe Abbildung 4B). Bevor Sie fortfahren, wäre es wichtig, auf den Standardversuch zu klicken, um sicherzustellen, dass diese Zeile markiert ist (siehe Abbildung 4C). Dieser Teil dient als Standardvorlage für alle untenstehenden Bedingungen. Änderungen beim Erstellen des Frames wirken sich daher folglich auf alle Bedingungen aus, sodass dies eine bequeme Möglichkeit ist, alle Versuche festzulegen, die dem gleichen experimentellen Verlauf folgen. Zum Beispiel, während der Standardversuch markiert ist, wird das Hinzufügen der Anzeige des Fixationskreuzes für eine bestimmte Anzahl von Dauer die gleiche Präsentation auf alle 48 Versuche unten in den Trials und Conditions anwenden.
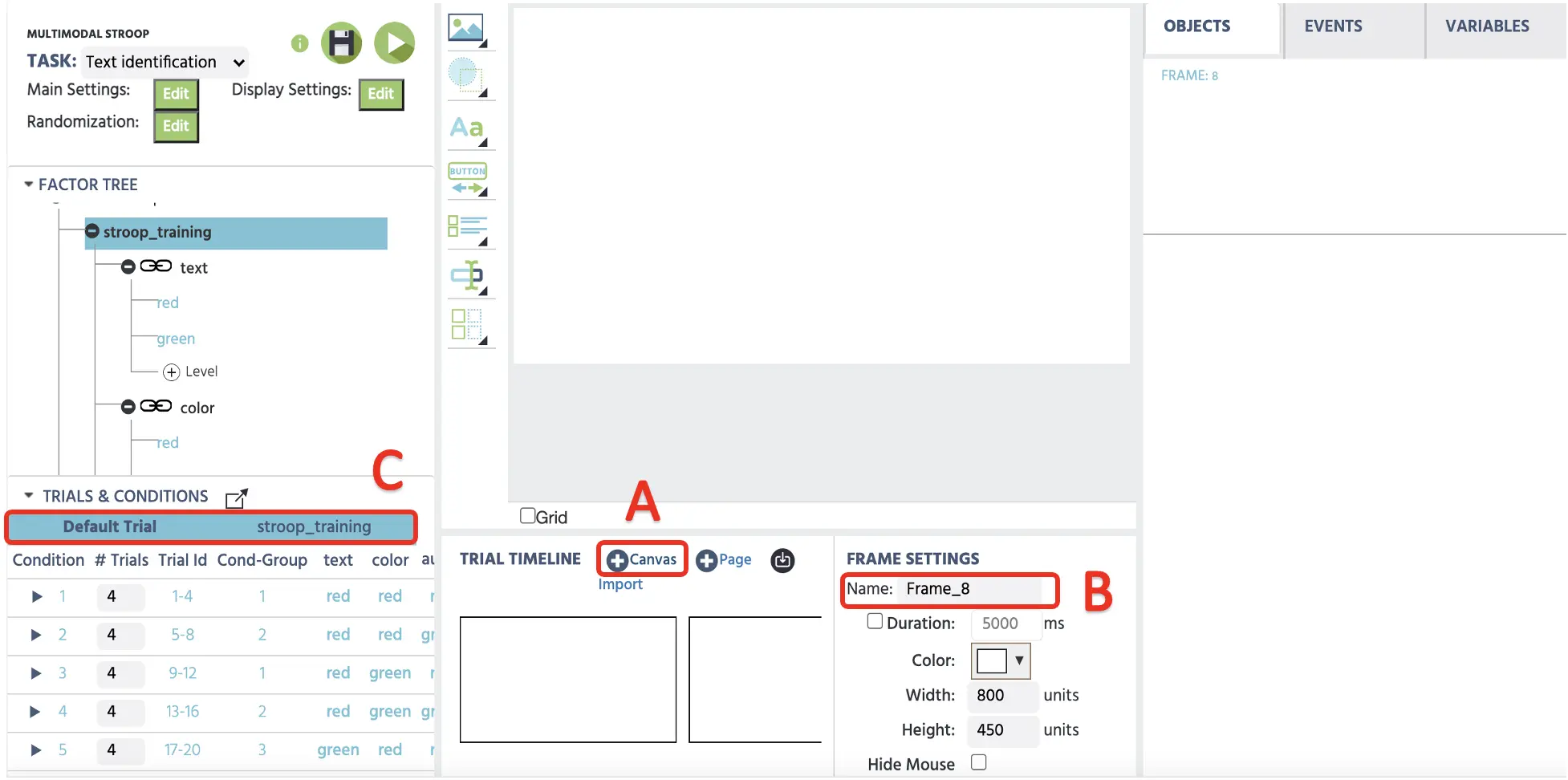 Abbildung 4. Anzeige eines Beispielversuchs mit Canvas-Frame-Erstellung (A), Frame-Namensänderungsoption (B) und Hervorhebung des Standardversuchs (C).
Abbildung 4. Anzeige eines Beispielversuchs mit Canvas-Frame-Erstellung (A), Frame-Namensänderungsoption (B) und Hervorhebung des Standardversuchs (C).
Um das Fixationskreuz im ersten Frame zu erstellen, können wir auf Text anzeigen klicken (siehe Abbildung 5A), um das Textfeld in das Canvas zu implementieren. Hier können wir das + im Feld mit einer Schriftgröße von 36 eingeben und es in der Mitte der Anzeige positionieren. Für die präzise zentral Positionierung könnten wir auch die spezifischen X- & Y-Frame-Koordinaten in den Objekteigenschaften rechts eingeben. Wenn wir das Bild mit dem Fixationskreuz oder anderen Stimuli hochladen möchten, kann die Medien-Option (siehe Abbildung 5B) verwendet werden, um Bilder, Videos, Audios usw. zu präsentieren.
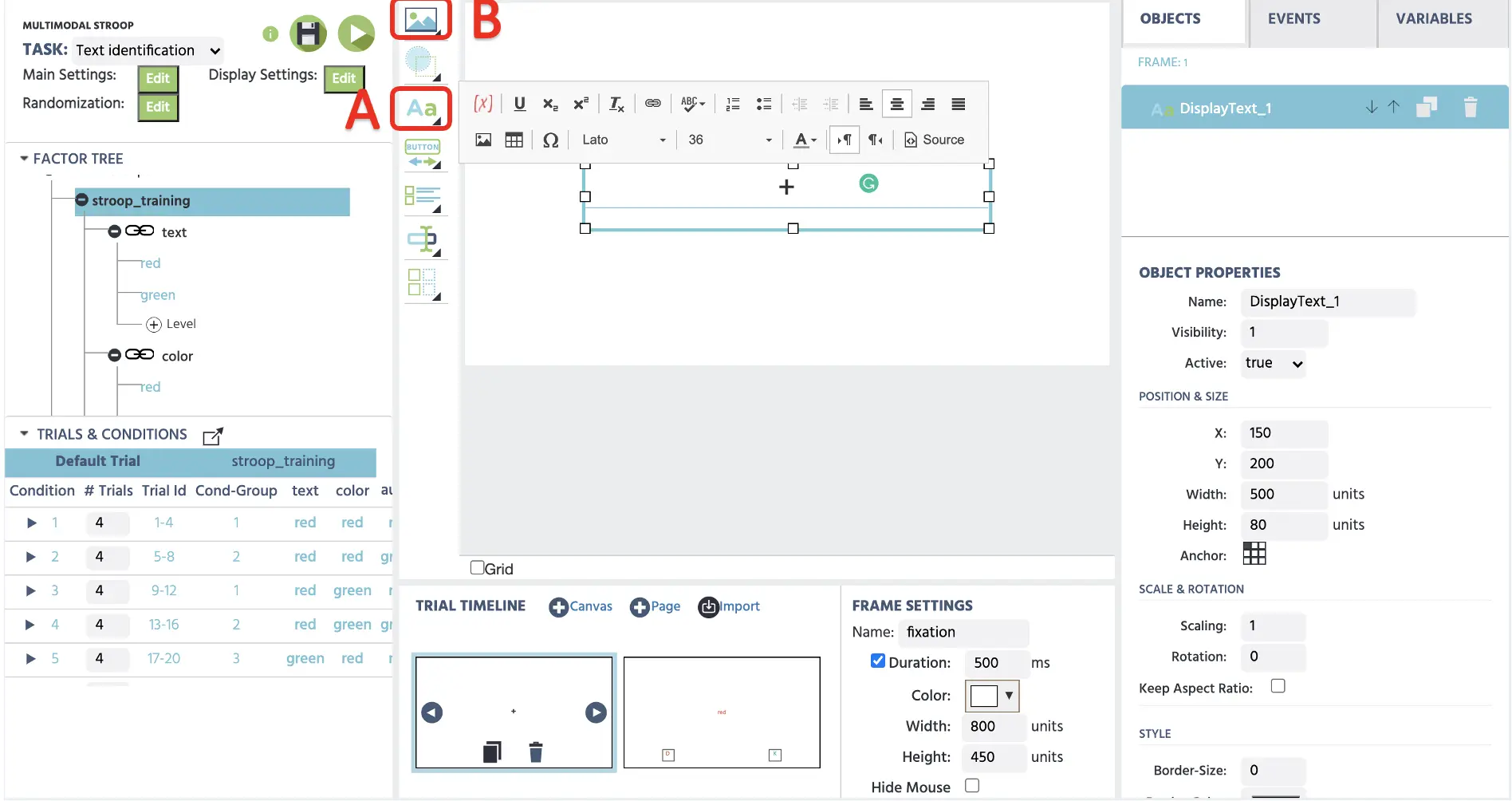 Abbildung 5. Anzeige der Erstellung des Fixationsrahmens mit der Text anzeigen-Option (A). Bilder, Videos und Audios können über die Medienoption präsentiert werden (B).
Abbildung 5. Anzeige der Erstellung des Fixationsrahmens mit der Text anzeigen-Option (A). Bilder, Videos und Audios können über die Medienoption präsentiert werden (B).
Die Erstellung der Rückmeldemeldungen (Frame 3: Korrekt; Frame 4: Falsch) beinhaltet denselben Prozess wie das Fixationskreuz, wobei die Nachrichten in das Textfeld eingegeben und die Positionierungsoption in der Mitte der Anzeige geändert werden kann (siehe Abbildung 6). Mit den Frames 1, 3, 4 sind wir nun bereit, mit der Zielerstellung im Frame 2 zu beginnen.
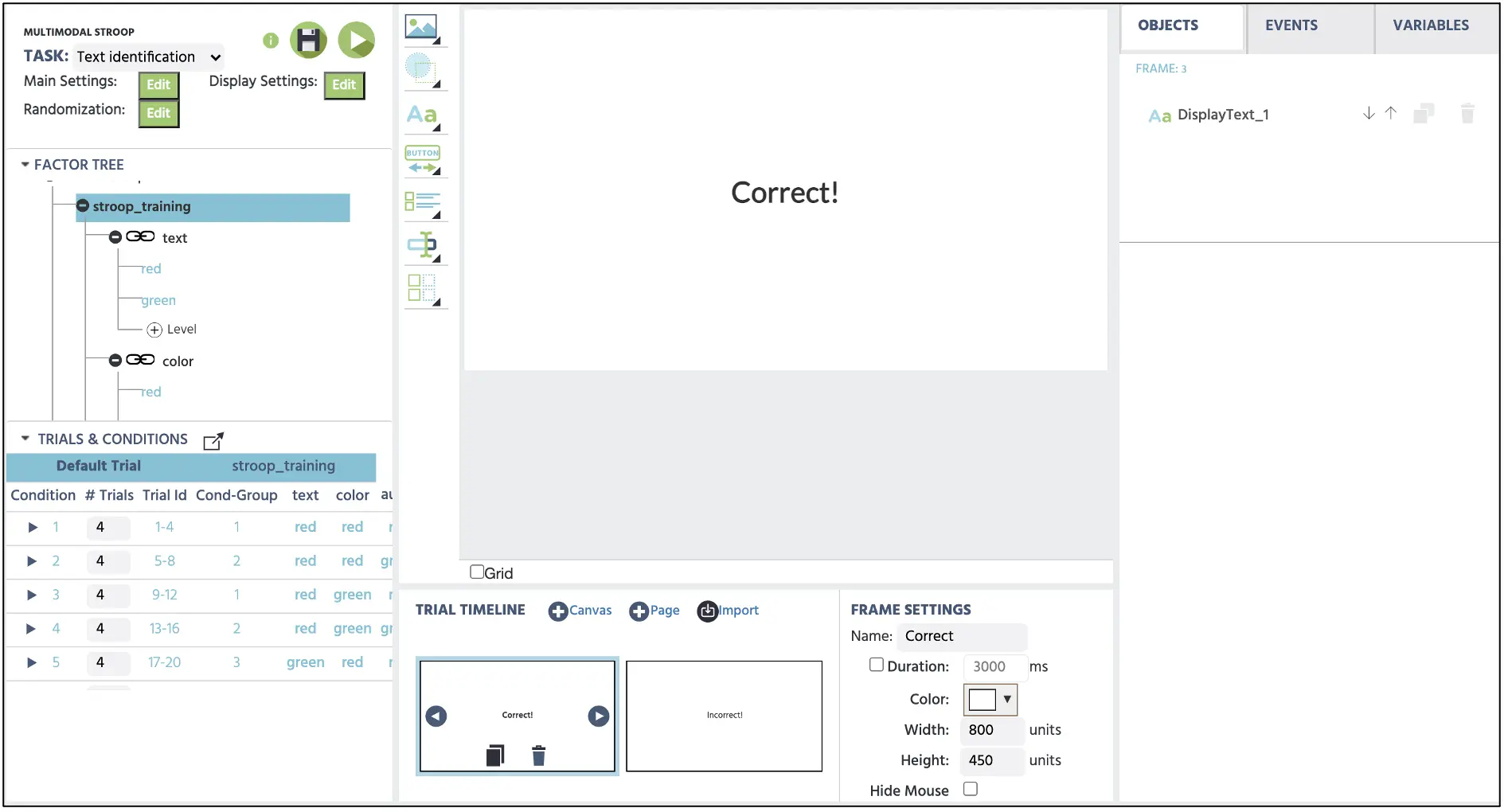 Abbildung 6. Beispielanzeige des korrekten Feedbacks im Frame 3.
Abbildung 6. Beispielanzeige des korrekten Feedbacks im Frame 3.
Teil III: Stimuli-Einrichtung
Um Frame 2: Zielpräsentation für sowohl visuelle (Text und Farbe) als auch auditive Stimuli zu erstellen, beginnen wir mit dem Klicken auf die Medien-Option (siehe Abbildung 5 oben) und Auswahl von Bild. Dies wird die Bild-Eigenschaft im Canvas Display öffnen, wo wir die Objekteigenschaften auf der rechten Seite verwenden können, um die Position, Größe und insbesondere das Bild, das wir aus dem Labvanced-Dateispeicher präsentieren möchten, anzupassen. Wenn der Forscher nicht alle experimentellen Stimuli importiert hat, öffnet das Klicken auf das Dateisymbol (siehe Abbildung 7) das Speicherfenster, in dem sie die Stimuli von Interesse hochladen und auswählen können.
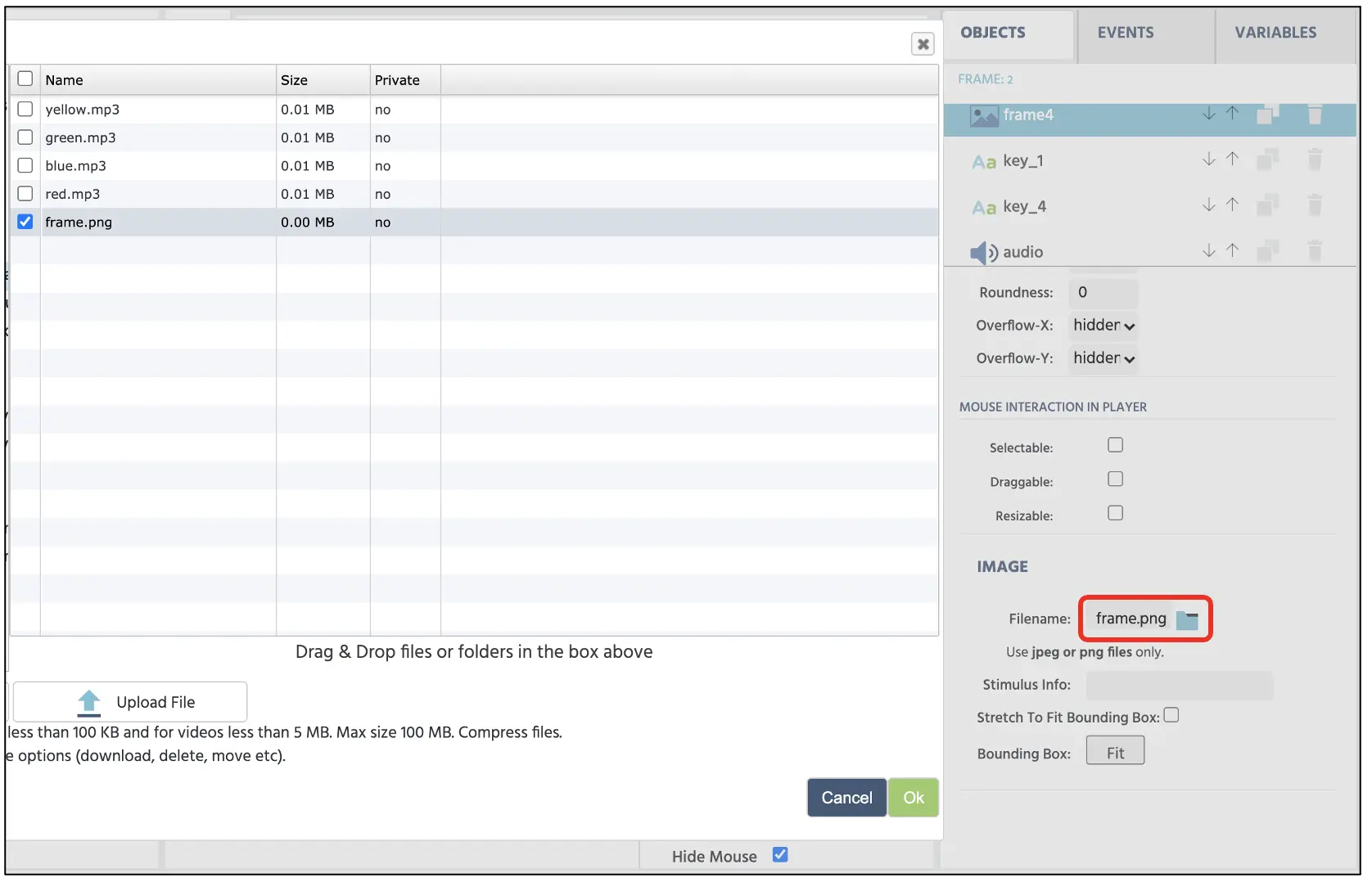 Abbildung 7. Anzeige des Dateispeichers, auf den über das Dateisymbol im roten Feld zugegriffen wird.
Abbildung 7. Anzeige des Dateispeichers, auf den über das Dateisymbol im roten Feld zugegriffen wird.
Anschließend besteht die Einrichtung der Stimuli aus den folgenden Präsentationen:
- 2 Bilder - Frames (Bild aus dem Dateispeicher)
- 3 Texte - 2 Antworttasten (D & K) und der zielt gefärbte Text
- 1 Audio - auditive Präsentation (Audio-Dateien aus dem Dateispeicher)
Wichtig ist, dass wir sicherstellen wollen, dass das richtige Audio und die Bilder mit einer bestimmten Farbe in jedem Versuch angezeigt werden. Dies kann unter Verwendung der Trials und Conditions referenziert werden, die wir bereits in Teil I erstellt haben. Zum Beispiel möchten wir in der ersten Bedingung sicherstellen, dass der Text „rot“ in roter Farbe zusammen mit der Audiopräsentation des roten Sprachsounds angezeigt wird (siehe Abbildung 8). In der zweiten Bedingung wollen wir jedoch denselben Text und dieselbe Farbe beibehalten, aber das Audio auf einen grünen Sprachsound ändern. Indem wir uns auf diese Trials & Conditions-Struktur beziehen, kann ein Forscher diesen Leitfaden verwenden, um das Setup der Stimuli zu leiten und sicherzustellen, dass alle möglichen Bedingungen in ihrer Studie berücksichtigt werden.
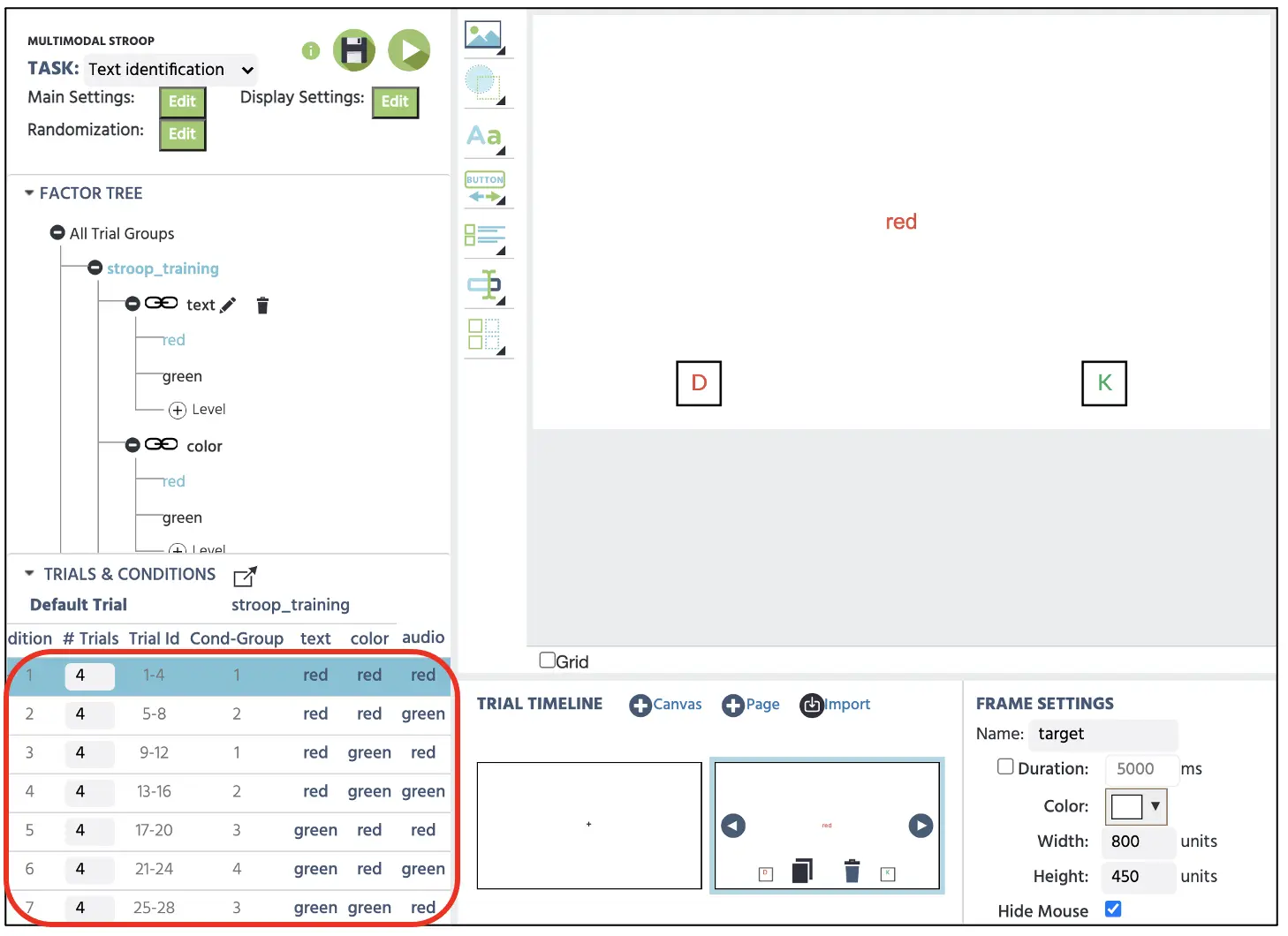 Abbildung 8. Anzeige des Canvas-Displays der Frame 2 Stimuli-Präsentation. In Übereinstimmung mit der ersten Bedingung im roten Feld präsentiert dieser Versuch den Speicher, auf den über das Dateisymbol im roten Feld zugegriffen wird.
Abbildung 8. Anzeige des Canvas-Displays der Frame 2 Stimuli-Präsentation. In Übereinstimmung mit der ersten Bedingung im roten Feld präsentiert dieser Versuch den Speicher, auf den über das Dateisymbol im roten Feld zugegriffen wird.
Der nächste Teil wird das Einrichten des Ereignissystems mit dem Abschluss des Frame-Setups bei jeder Stimuli-Präsentation betreffen. Hier werden wir programmieren, um der logischen Reihenfolge zu folgen, wie die Frames mit den jeweiligen Stimuli für eine bestimmte Dauer präsentiert werden sollen und wichtige Informationen wie Reaktionszeiten (ms) und korrekte Antworten aufzeichnen.
Teil IV: Ereignis-Einrichtung
Bevor wir das Ereignissystem erstellen, lassen Sie uns zwei neue Variablen (Reaktionszeit und korrekte Antwort) erstellen, die als abhängige Variablenmessungen dienen werden. Um neue Variablen zu erstellen, können wir auf die Variablen oben rechts klicken und Variable hinzufügen (siehe Abbildung 9) auswählen. Im neuen Variablenfenster gehen wir die folgenden Schritte für Namen und Typen durch. Diese Variablen speichern wichtige Verhaltensmessungen darüber, wie schnell der Teilnehmer das Ziel unterscheidet und ihre jeweilige Genauigkeitsleistung. Somit werden die zwei neuen Variablen sein:
- Reaktionszeit - gemessen in Millisekunden ab dem Frame-Onset
- Korrekt - Genauigkeit der Antwort (1=korrekt; 0=falsch)
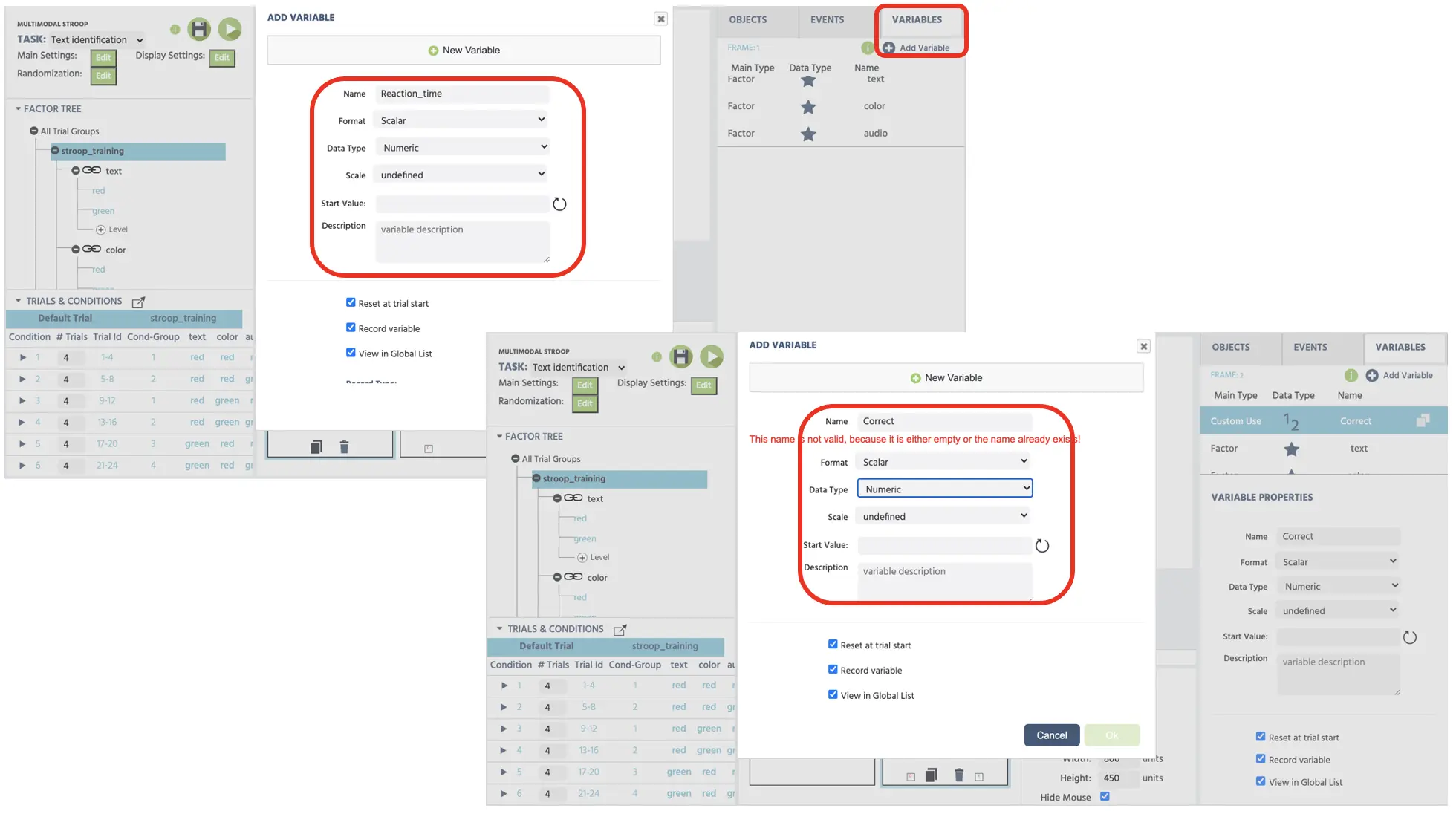 Abbildung 9. Anzeige der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp eingestellt.
Abbildung 9. Anzeige der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp eingestellt.
Folgend der allgemeinen Frame-Sequenz aus Teil II (siehe Abbildung 3 oben) wird dieser Abschnitt in 4 Unterabschnitte aufgeteilt, die die Erstellung von Ereignissen für jeden Frame erklären.
Frame 1 Ereignisse: Fixationskreuz
In diesem Frame möchten wir das Fixationskreuz in der Mitte der Anzeige für 500 ms präsentieren. Daher ist die logische Reihenfolge, die wir anwenden werden:
- Sobald der Frame startet
- Warten Sie 500 ms
- Und springen Sie dann zum nächsten Frame
Um dies in Ereignisse umzusetzen, klicken Sie oben rechts auf die Ereignisse neben den Variablen und wählen Sie Frame-Ereignis (nur in diesem Frame). Im ersten Fenster-Dialog können wir die Ereignisse als „Start“ benennen und auf weiter klicken, um zur Trigger-Option überzugehen. Hier ist der Trigger-Typ Versuch und Frame Trigger → Frame Start (entsprechend der 1. logischen Reihenfolge oben). Mit diesem Trigger möchten wir die 500 ms Frame-Verzögerungsaktion (2. logische Reihenfolge) einleiten; daher kann dies mit Aktion hinzufügen → Verzögerte Aktion (Zeit-Callback) und Einstellen von 500 ms im Verzögerungsfeld (siehe Abbildung 10) festgelegt werden. Um endlich die letzte logische Reihenfolge auszuführen, klicken Sie auf Aktion hinzufügen im Aktionssequenz-Feld und wählen Sie Sprungaktion → Springen zu → Wählen Sie den nächsten Frame aus (siehe Abbildung). Labvanced wird immer dieser logischen Sequenz für die Präsentation des Fixationskreuzes in allen Versuchen mit diesem Setup folgen.
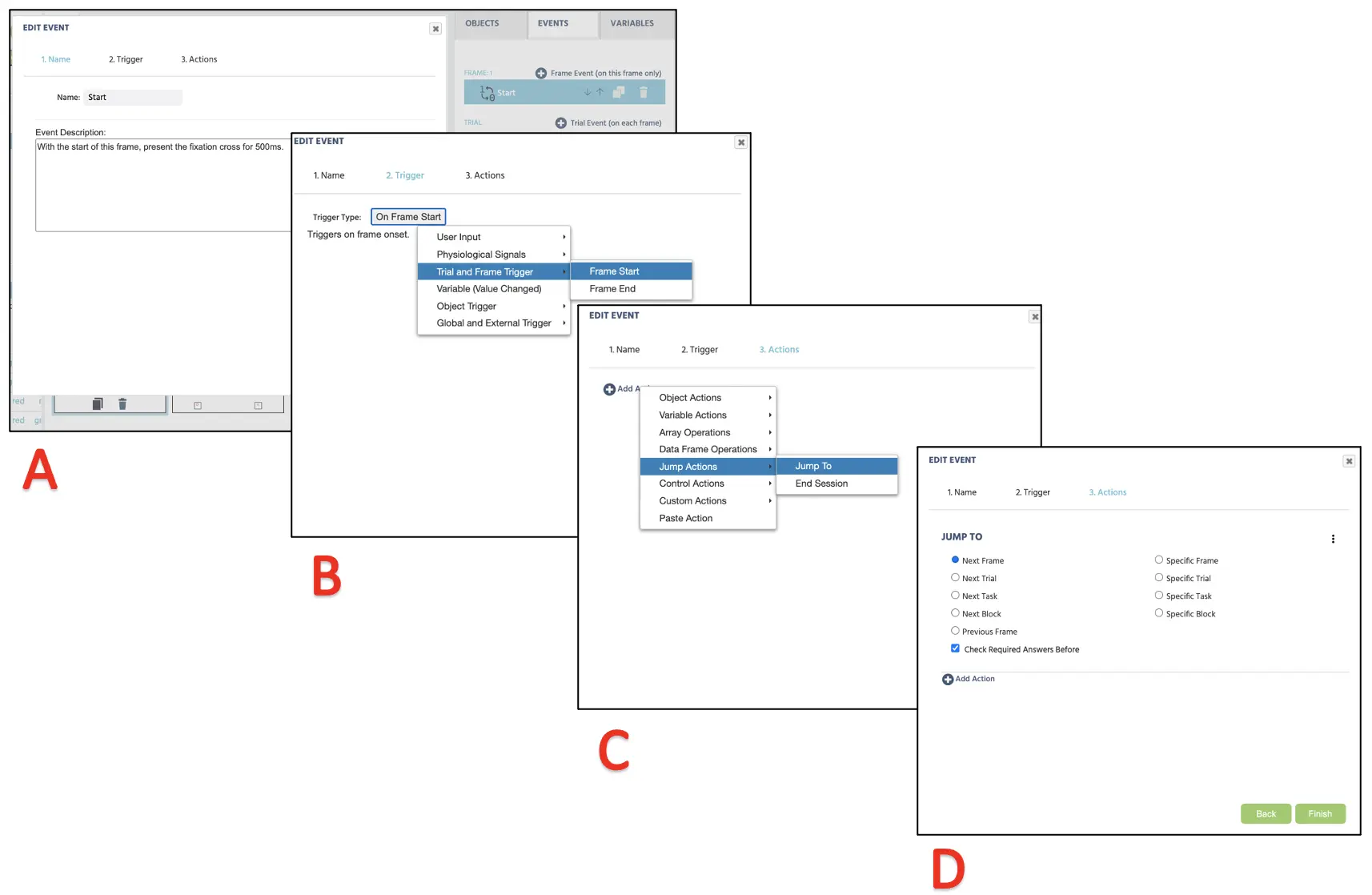 Abbildung 10. Anzeige der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) entsprechend der Ereignisbenennung (A), Trigger (B), Handlungsermittlung (C) und Ausführung der gewünschten Handlung.
Abbildung 10. Anzeige der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) entsprechend der Ereignisbenennung (A), Trigger (B), Handlungsermittlung (C) und Ausführung der gewünschten Handlung.
Frame 2 Ereignisse: Zielpräsentation und Aufzeichnung der Reaktionen
In diesem Frame möchten wir das Zielwort mit einem auditiven Sound zu Beginn des Frames präsentieren und es so lange beibehalten, bis ein Tastendruck erfolgt. Daher ist die logische Reihenfolge, die wir anwenden werden:
- Sobald der Frame startet
- Spiel die Audio entsprechend diesem Versuch
- Wenn die Tastenreaktion korrekt ist → Aufzeichnung Korrekt = 1 → Springen zu dem richtigen Feedback (Frame 3)
- Wenn die Tastenreaktion falsch ist → Aufzeichnung Korrekt = 0 → Springen zu dem falschen Feedback (Frame 4)
Lassen Sie uns zunächst mit dem Abspielen des Audios beginnen, aber sicherstellen, dass der Standardversuch markiert ist, sodass diese Ereignisse für jeden Versuch angewendet werden. Dieser Prozess wird dem des Fixationskreuzes oben entsprechen, da die Logik gleich bleibt: Sobald der Frame startet, mache X. Wir beginnen mit dem Klicken auf die Ereignisse und wählen Frame-Ereignis (nur in diesem Frame). Im ersten Fenster-Dialog können wir die Ereignisse als „Audio abspielen“ benennen und auf weiter klicken, um zur Trigger-Option überzugehen. Hier ist der Trigger-Typ Versuch und Frame Trigger → Frame Start (entsprechend der 1. logischen Reihenfolge). Danach fahren wir fort mit den Objektaktionen → Audio-/Videoobjekt steuern → Wählen Sie das vorhandene Audioobjekt im Canvas aus, um zu starten (siehe Abbildung 11). Mit diesem Setup folgt Labvanced immer der logischen Reihenfolge für die Audio-Präsentation in jedem Versuch im Frame 2. Lassen Sie uns nun die verbleibenden Teile der Einrichtung der Tastenreaktionsbedingungen besprechen.
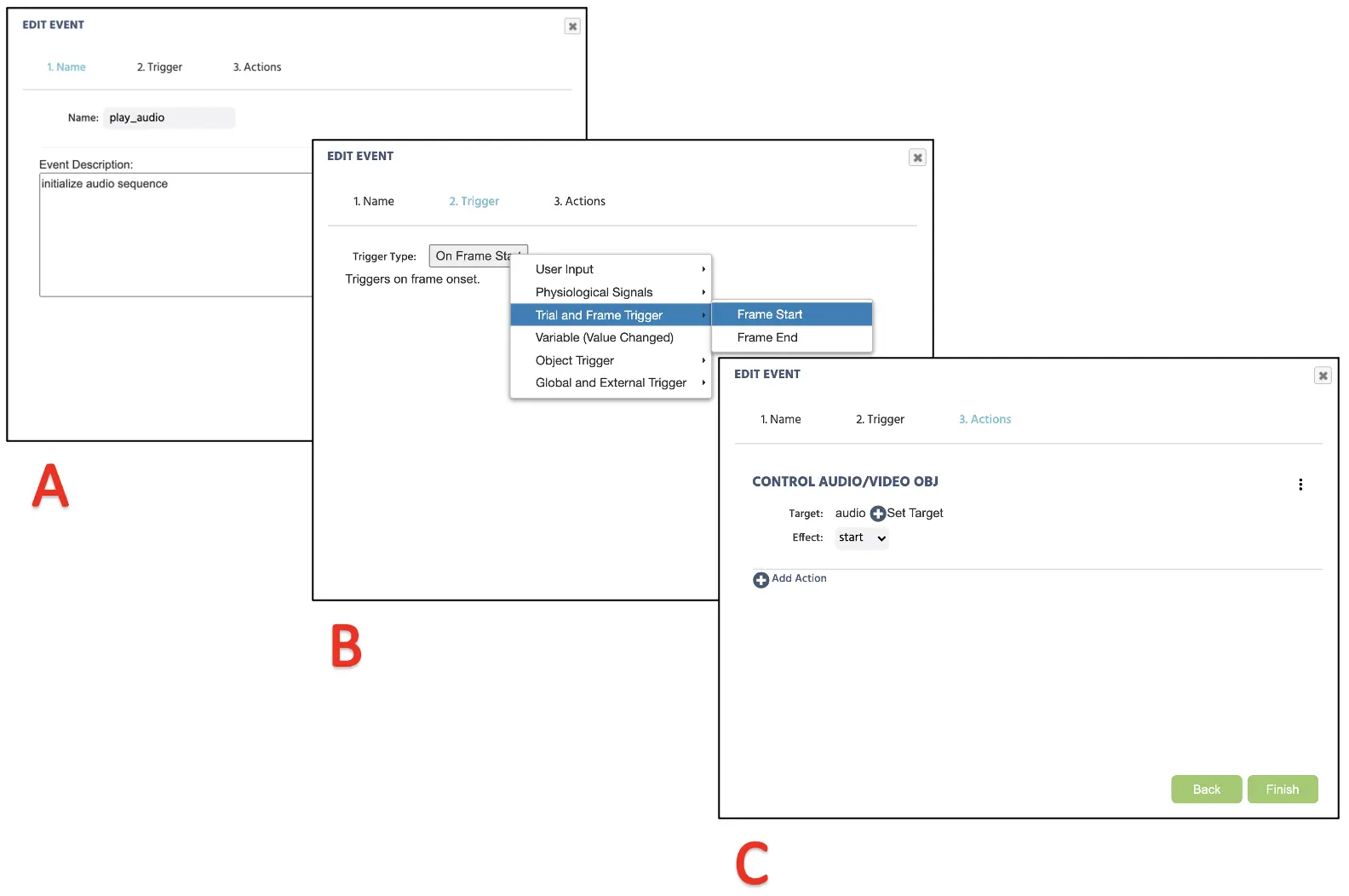 Abbildung 11. Anzeige der Ereigniserstellung für Audio (Frame 2) Präsentation entsprechend der Ereignisbenennung (A), Trigger (B), Handlungsermittlung (C) und Ausführung der gewünschten Handlung.
Abbildung 11. Anzeige der Ereigniserstellung für Audio (Frame 2) Präsentation entsprechend der Ereignisbenennung (A), Trigger (B), Handlungsermittlung (C) und Ausführung der gewünschten Handlung.
Wie bereits erwähnt, erfordert dieser Block, dass die Teilnehmer auf den Text achten und diesen mit dem entsprechenden Tastendruck unterscheiden, während die Farbe und der präsentierte Sound ignoriert werden. Praktischerweise können wir die Textspalte in den Trials & Conditions verwenden, um festzustellen, ob der Tastendruck des Teilnehmers der zugehörigen Bedingung entspricht. Dies würde die bedingte Argumentation ermöglichen und die Korrekt-Variable mit der jeweiligen korrekten / falschen Messung aufzeichnen. Um dieses Ereignis zu erstellen, beginnen wir erneut damit, auf Ereignisse zu klicken und Frame-Ereignis (nur in diesem Frame) auszuwählen. Da dieses Ereignis demonstrativ für den Tastendruck eines Teilnehmers ist, wäre der Trigger der Benutzereingabe → Tastatureingabe-Trigger. Hier können wir zwei mögliche Tastendrücke festlegen (siehe Abbildung 12), die „D“ und „K.“ sind. Nach dem Klicken auf weiter wird die Aktionsfolge mit Kontrollaktionen → Erforderlichkeitsaktionen (Wenn…dann) fortgesetzt.
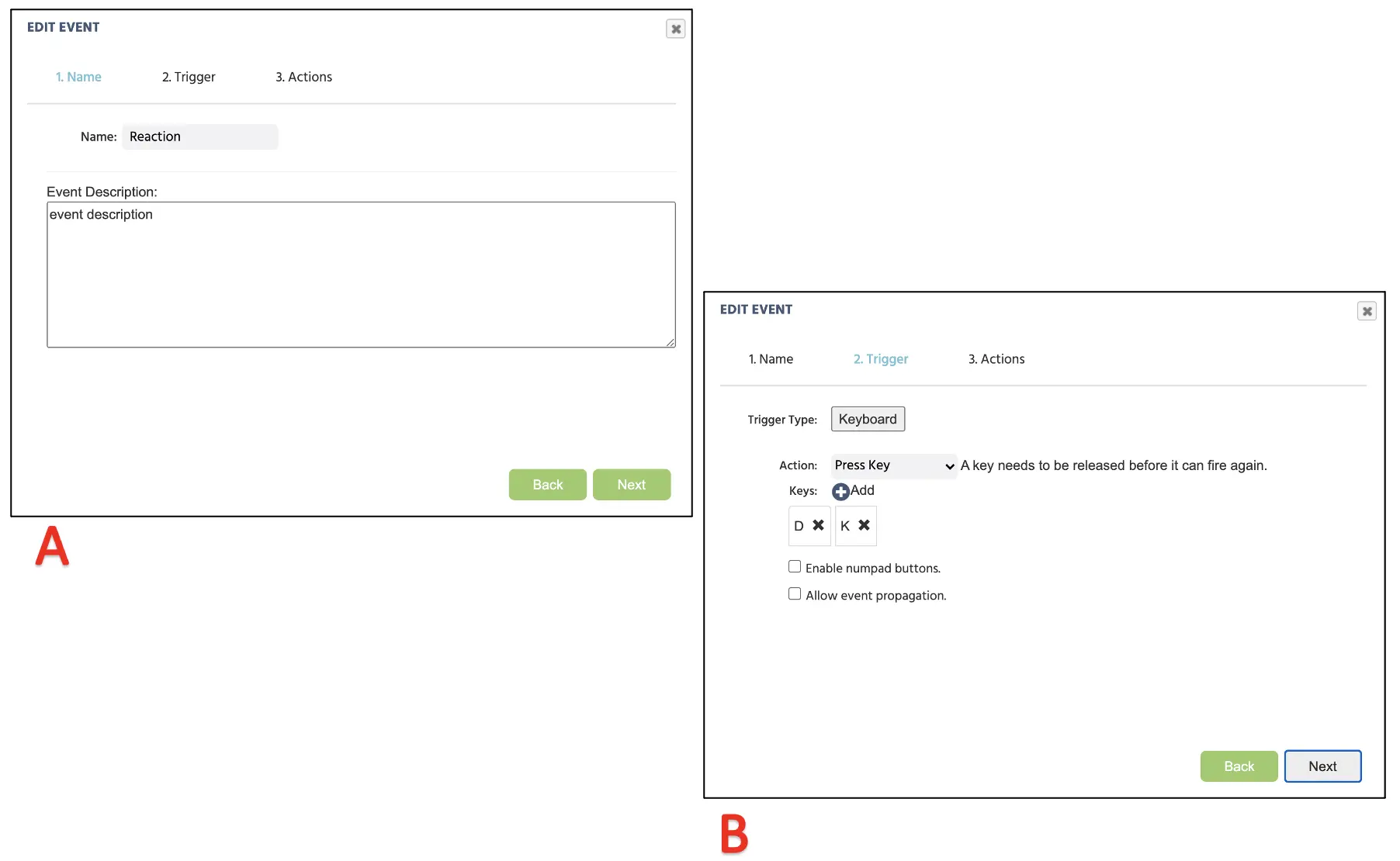 Abbildung 12. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken entsprechend der Ereignisbenennung (A), Trigger-Zuweisung mit zulässigen Tastendruckantworten (B).
Abbildung 12. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken entsprechend der Ereignisbenennung (A), Trigger-Zuweisung mit zulässigen Tastendruckantworten (B).
Im Wenn-Teil dieses Dialogs möchten wir die Bedingung festlegen, um das Ziel mit dem Tastendruck zu verknüpfen. Hier können wir die linke Seite als Textvariable festlegen (siehe Abbildung 13) und die rechte Seite, indem wir eine „rote“ Zeichenfolge einfügen. Direkt darunter benötigen wir ein weiteres Set von Bedingungen und setzen die linke Seite Trigger(Tastatur) → ID der Taste. Auf der rechten Seite können wir den Buchstaben „D“ (stellen Sie sicher, dass dieser groß geschrieben ist) eingeben.
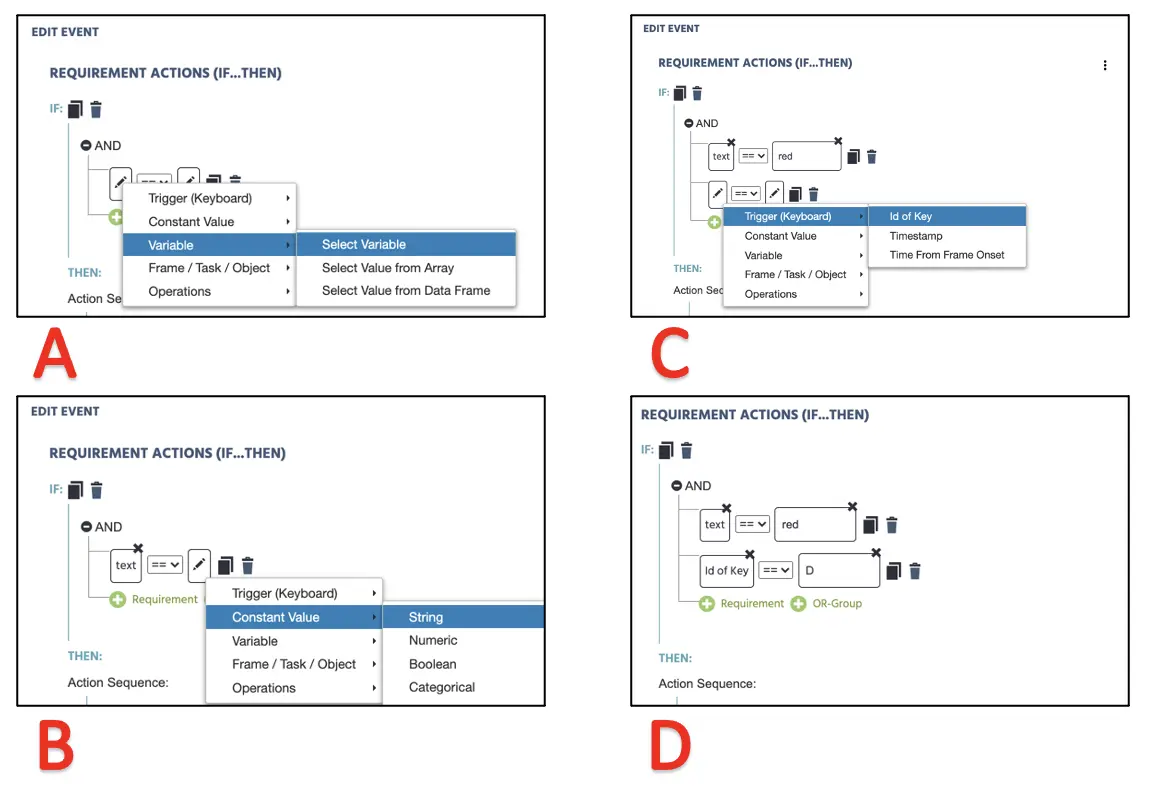 Abbildung 13. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken nach Variablenbestimmung (A), zugehörige Bedingung (B) und Bewertung der Tastendruckantwort (C & D).
Abbildung 13. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken nach Variablenbestimmung (A), zugehörige Bedingung (B) und Bewertung der Tastendruckantwort (C & D).
Im Dann-Teil unten möchten wir festlegen, welche Aktion das Programm basierend auf der oben festgelegten IF-Bedingung ausführen sollte. Da die „D“-Taste die richtige Antwort ist, wenn der Text „rot“ vorhanden ist, möchten wir dies als korrekt in der Korrekt-Variablen festlegen und die richtige Rückmeldemeldung präsentieren. Dazu können wir Variable setzen/aufzeichnen: Korrekt auf der linken Seite und die ganze Zahl 1 auf der rechten Seite einfügen (siehe Abbildung 14). Direkt darunter klicken Sie auf Aktion hinzufügen, um Sprungaktion hinzuzufügen (ähnlich wie im Fixationsrahmen), aber diesmal möchten wir Spezifischen Frame (Korrekt) auswählen, um die Rückmeldemeldung „Korrekt“ darzustellen. Damit haben wir die bedingte Sequenz eingerichtet, um das Labvanced-Programm aufzufordern, die Teilnehmerantwort als korrekt aufzuzeichnen, wenn der D-Tastendruck erfolgt ist, während die Anzeige des „roten“ Textes präsentiert wird.
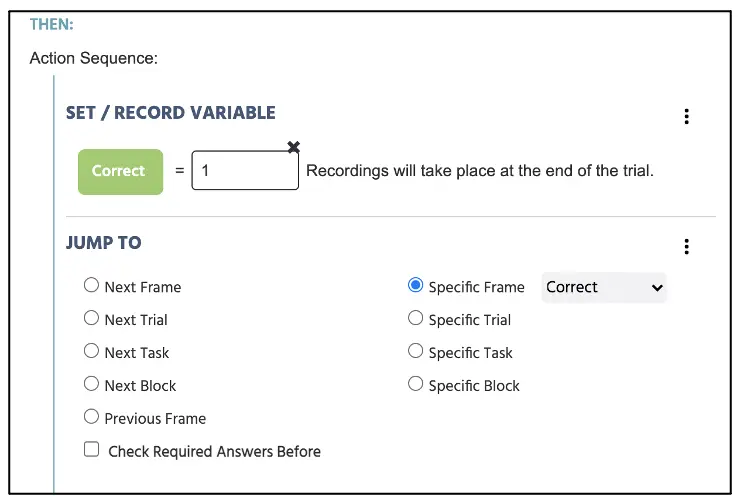 Abbildung 14. Anzeige der Ereigniserstellung basierend auf Abbildung 13. Das Setzen/Aufzeichnen bestimmt die Korrekt-Variable mit 1 = korrekt (0, wenn nicht) wenn die Bedingungen mit dem Setup in Abbildung 13 erfüllt sind.
Abbildung 14. Anzeige der Ereigniserstellung basierend auf Abbildung 13. Das Setzen/Aufzeichnen bestimmt die Korrekt-Variable mit 1 = korrekt (0, wenn nicht) wenn die Bedingungen mit dem Setup in Abbildung 13 erfüllt sind.
Wenn wir diesen Schritt wiederholen, müssen wir diesen Prozess für den „grünen“ Text erstellen, da dies der korrekte Tastendruck ist (siehe Abbildung 15A). Dann können wir auf Else klicken, um die endgültige Setzen/Aufzeichnen-Variable: Korrekt auf 0 mit der Sprungaktion-Sequenz zum falschen Rückmelderahmen (siehe Abbildung 15B) festzulegen. Dieses letzte Argument bezieht sich darauf, wenn die Tastendruckantwort keine der vorherigen beiden korrekten Argumente erfüllt, fordern wir das Programm auf, dies als falsch aufzuzeichnen (0).
 Abbildung 15. Anzeige der Ereigniserstellung nach Abbildung 14, wobei der Prozess für die grüne Textbedingung (A) repliziert wird und die falsche (0) Antwort festgelegt wird, wenn keine der Bedingungen in den Abbildungen 13 & 14 erfüllt sind (B).
Abbildung 15. Anzeige der Ereigniserstellung nach Abbildung 14, wobei der Prozess für die grüne Textbedingung (A) repliziert wird und die falsche (0) Antwort festgelegt wird, wenn keine der Bedingungen in den Abbildungen 13 & 14 erfüllt sind (B).
Frames 3 & 4 Ereignisse: Rückmeldungspräsentation
Die Ereignisse in den Rückmelde-Frames, die korrekten (Frame 3) und falschen (Frame 4) Nachrichten enthalten, spiegeln den gleichen Prozess wie der Fixationsrahmen wider. Welchen Tastendruck der Teilnehmer auch macht, möchten wir das Feedback für 1000 ms in der Mitte der Anzeige präsentieren und dann zum nächsten Versuch übergehen. Daher ist die logische Reihenfolge, die wir anwenden werden:
- Sobald der Frame startet
- Warten Sie 1000 ms
- Und springen Sie dann zum nächsten Versuch
Um dies in Ereignisse umzusetzen, klicken Sie auf die Ereignisse in der oberen rechten Ecke neben den Variablen und wählen Sie Frame-Ereignis (nur in diesem Frame). Im ersten Fenster-Diolog können wir die Ereignisse als „Start“ benennen und auf weiter klicken, um zur Trigger-Option überzugehen. Der Trigger-Typ ist Versuch und Frame Trigger → Frame Start (entsprechend der 1. logischen Reihenfolge oben). Mit diesem Trigger möchten wir die 1000 ms Frame-Verzögerungsaktions (2. logische Reihenfolge) einleiten; daher kann dies mit Aktion hinzufügen → Verzögerte Aktion (Zeit-Callback) und 1000 ms in das Verzögerungsfeld gesetzt werden. Schließlich klicken Sie zum Ausführen der letzten logischen Reihenfolge auf Aktion hinzufügen im Aktionssequenzfeld und fahren Sie mit Sprungaktion → Springen zu → Wählen Sie den nächsten Versuch aus fort. Mit diesem Setup wird Labvanced immer dieser logischen Sequenz für die Rückmeldungspräsentation für beide Frames 3 & 4 über alle Versuche hinweg folgen. Im Allgemeinen spiegelt dieser Schritt denselben Ablauf und dieselben Abbildungen wider, die als Referenz verwendet werden könnten.
Bisher haben wir einen Block erstellt, in dem die Hauptaufgabe des Teilnehmers darin besteht, den präsentierten Text zu unterscheiden, während er aktiv die gleichzeitige Farbe und die Audio-Präsentation ignoriert. Mit diesem festgelegten Setup können wir auch eine neue Aufgabe erstellen, um die Farbe oder das Audio mit geringfügigen Änderungen am aktuellen Aufbau zu unterscheiden. Dieses Verfahren wird in psychologischen Experimenten häufig verwendet, um die Leistung während der Zielunterscheidung zwischen verschiedenen Stimuli zu vergleichen.
Um einen neuen Block für die Farbdiskriminierung hinzuzufügen, können wir einfach die bestehende Aufgabe im Hauptstudienentwurf kopieren und den Namen in Farberkennung ändern (siehe Abbildung 16).
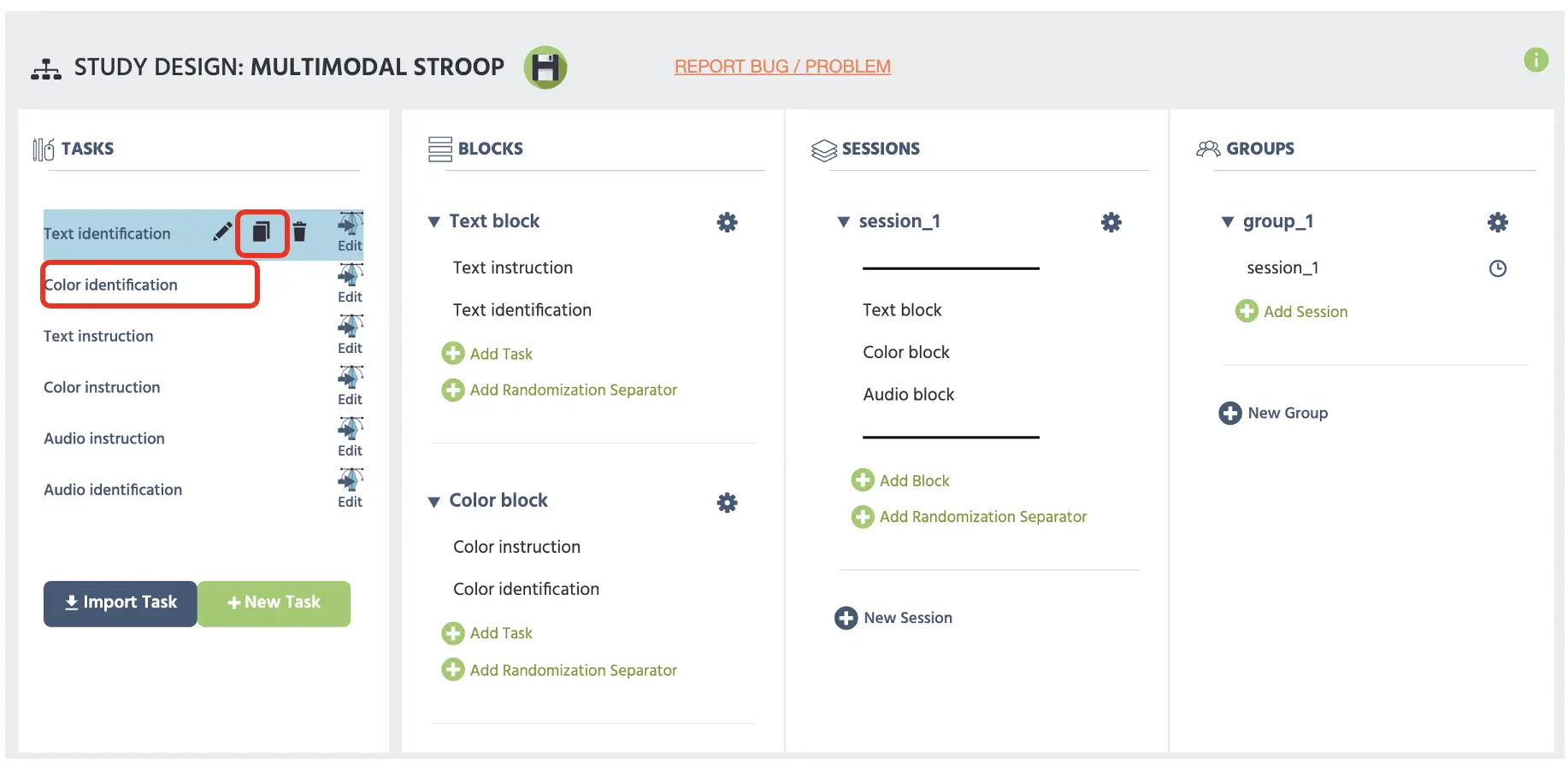 Abbildung 16. Anzeige der Hauptstudiengestaltungsseite mit dem oberen roten Feld, das die Kopieraufgabe anzeigt, die zum zweiten roten Feld mit dem bearbeiteten Aufgabenname führt.
Abbildung 16. Anzeige der Hauptstudiengestaltungsseite mit dem oberen roten Feld, das die Kopieraufgabe anzeigt, die zum zweiten roten Feld mit dem bearbeiteten Aufgabenname führt.
Es gibt nur eine Sache, die im Aufgabenbildschirm geändert werden muss, nämlich die Variablenzuweisung im Frame 2. In der Antwort-Einrichtung können wir einfach die Text-Variable in Farbe ändern, sodass das Programm den Tastendruck mit der präsentierten Farbe vergleicht, anstatt mit dem Text aus dem vorherigen Aufbau (siehe Abbildung 17). Ebenso können wir auch die Audio-Diskriminierungsaufgabe erstellen, indem wir denselben Schritt wiederholen und die Variablenzuweisung vom Text (oder der Farbe) auf Audio ändern. Wir haben drei experimentelle Aufgaben mit verschiedenen Aufgaben erstellt, die wir in Blöcke für die Gesamtstudienpräsentation organisieren können.
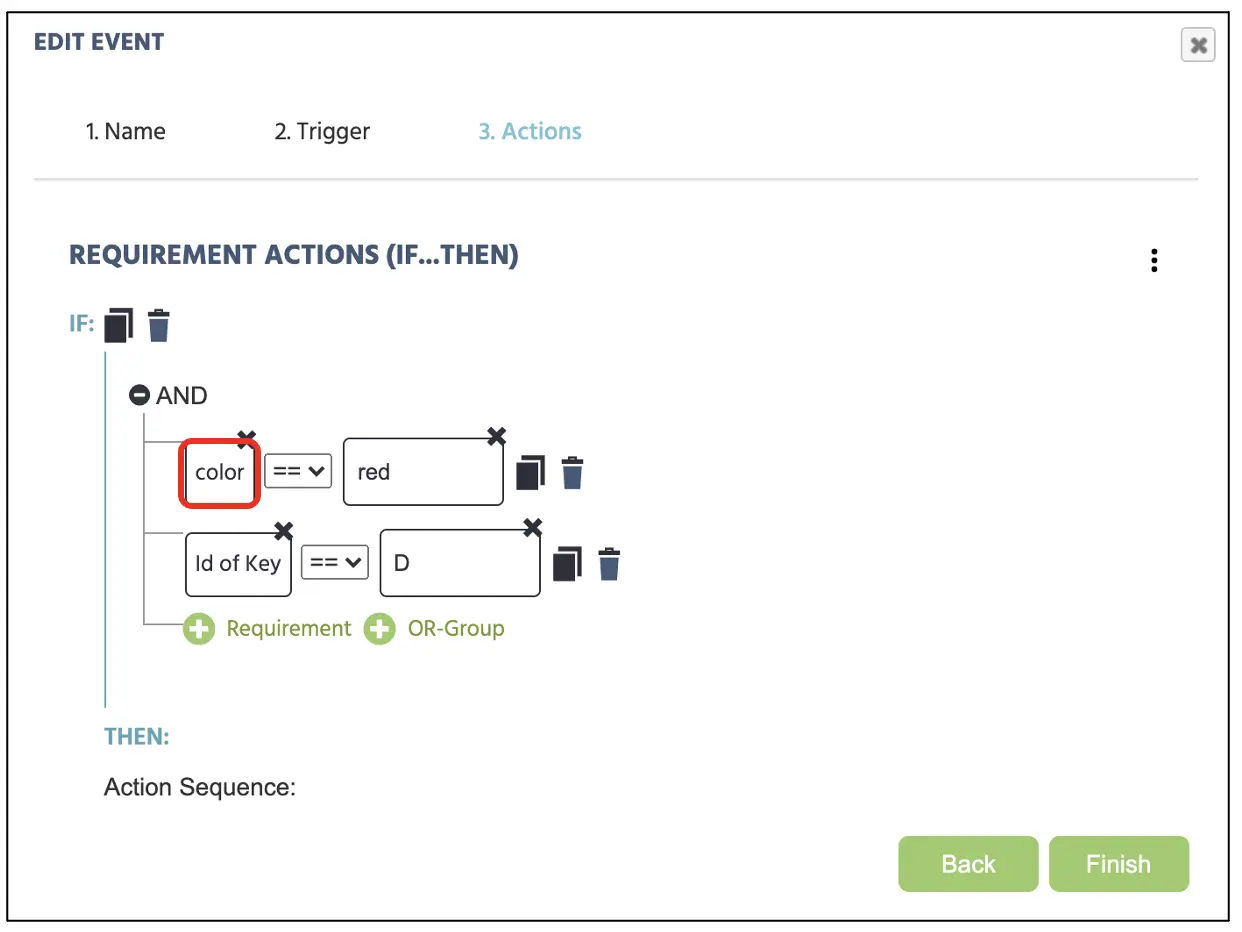 Abbildung 17. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken entsprechend der neuen Farbvariablenbestimmung. Farbe kann durch Audio ersetzt werden, um die Hauptzielunterscheidung zu ändern.
Abbildung 17. Anzeige der Ereigniserstellung für die Zuweisung von Tastendrucken entsprechend der neuen Farbvariablenbestimmung. Farbe kann durch Audio ersetzt werden, um die Hauptzielunterscheidung zu ändern.
Teil V: Block-Einrichtung
Jetzt, da wir die Experimentaufgaben eingerichtet haben, werden wir die Blöcke strukturieren und die Gegenbalancierungen so einrichten, dass jede Aufgabe den Teilnehmern zufällig präsentiert wird. Bevor wir fortfahren, wäre es ideal, bevor jeder Aufgabe Anweisungsnachrichten (siehe Abbildung 18) zu erstellen, in denen die Teilnehmer informiert werden, dass die Hauptaufgabe jetzt das Unterscheiden von Text, Farbe oder Audio je nach bevorstehender Aufgabe ist.
 Abbildung 18. Anzeigeneinführung für die Ziel- (Text-) Diskriminierungsaufgabe. Anweisungen für die Farb- und Audio-Diskriminierung könnten mit demselben Format unter Verwendung der unterstrichenen Wörter bearbeitet werden.
Abbildung 18. Anzeigeneinführung für die Ziel- (Text-) Diskriminierungsaufgabe. Anweisungen für die Farb- und Audio-Diskriminierung könnten mit demselben Format unter Verwendung der unterstrichenen Wörter bearbeitet werden.
Nachdem wir jede Anweisungsnachricht erstellt haben, können wir jetzt den Block gemäß seiner Aufgabenbeschreibung einrichten. Wichtig ist, dass die Organisation des Blocks auf diese Weise es uns ermöglicht, den Zufälligkeitsseparator zu implementieren, wie im Sitzungsbereich zu sehen (siehe Abbildung 19). Diese Struktur ermöglicht es Labvanced, die Blockpräsentation gegen zu balancieren, sodass Forscher die Leistungsunterschiede über alle Blocksequenzkombinationen vergleichen können.
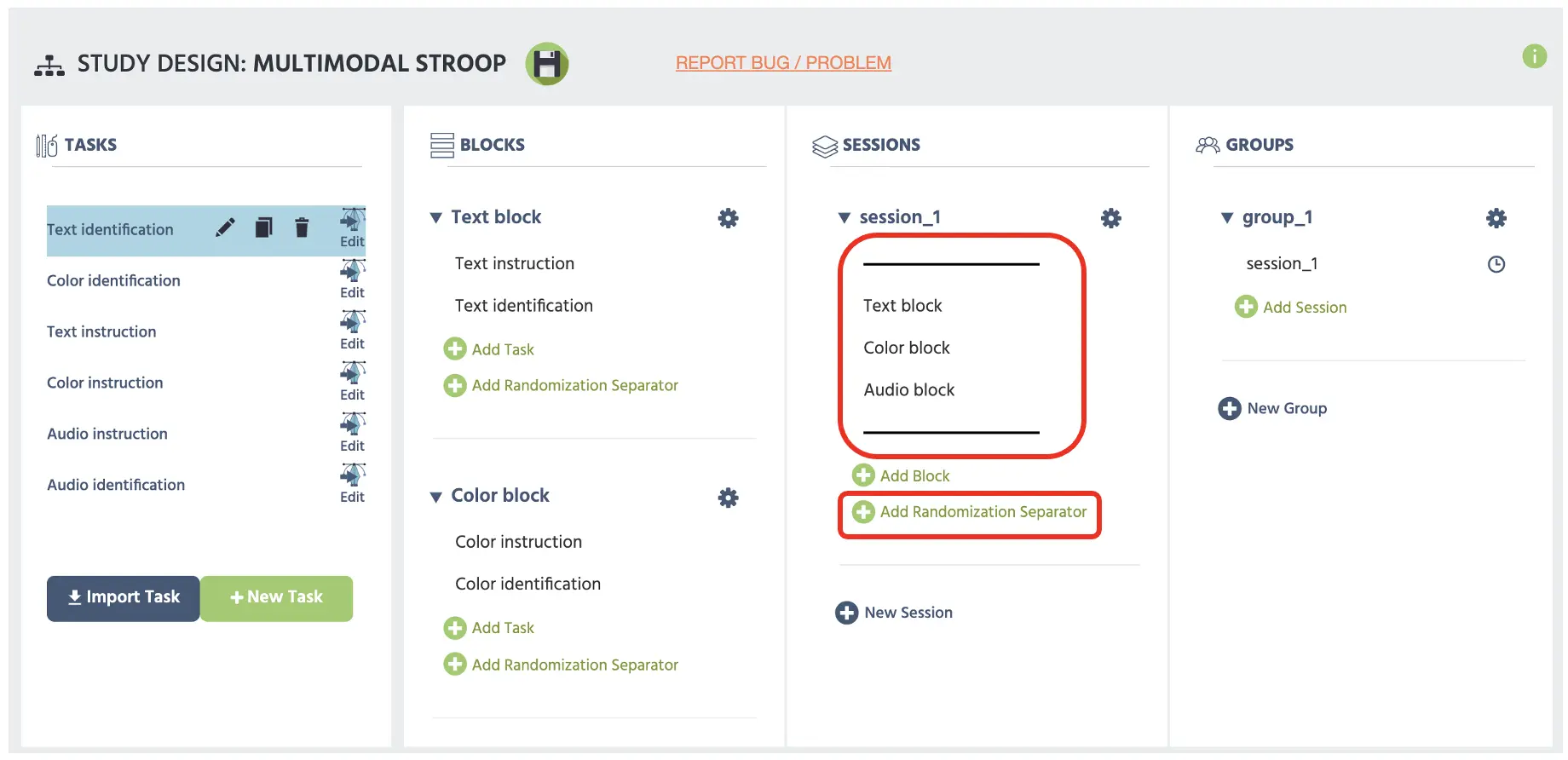 Abbildung 19. Anzeige der Hauptstudiengestaltungsseite mit dem oberen roten Feld, das zwei parallele Balken anzeigt, die als Zufallstrenner dienen, die über die Schaltfläche Zufälligen Separator hinzufügen hinzugefügt wurden.
Abbildung 19. Anzeige der Hauptstudiengestaltungsseite mit dem oberen roten Feld, das zwei parallele Balken anzeigt, die als Zufallstrenner dienen, die über die Schaltfläche Zufälligen Separator hinzufügen hinzugefügt wurden.
Das Einzige, was in diesem Leitfaden noch übrig bleibt, sind das Einverständnisformular, das Anweisungsdokument, demografische Fragen und andere Protokolle, die jedoch je nach Forscher und Institution variieren, sodass dieser Leitfaden hier endet. Für weitere Informationen zur Texterstellung bietet dieser Link zusätzliche Informationen. Damit wünschen wir Ihnen viel Erfolg bei Ihren wissenschaftlichen Bestrebungen und hoffen, dass dieser Leitfaden als wichtiger Grundstein für den Aufbau Ihrer Studie dient.