Anleitung zur Erstellung der Posner Gaze Cueing Task
Willkommen zu einem weiteren Labvanced-Leitfaden für die Erstellung von Studien! In dieser Sitzung werden wir eine der beliebten neuropsychologischen Bewertungsaufgaben von Posner erstellen, auch bekannt als Posners Paradigma. Ursprünglich von Michael Posner formuliert, wird diese Studie häufig verwendet, um die Aufmerksamkeitsleistung eines Individuums zu untersuchen und Hirnverletzungsstörungen sowie Defizite der räumlichen Aufmerksamkeit zu bewerten.
Im Allgemeinen verlangen die Aufgaben der Studie von den Teilnehmern, dass sie auf den zentralen Punkt in der Mitte des Computerbildschirms fixieren, der durch einen Punkt oder ein Kreuz markiert ist. Konventionell werden zwei Kästchen entweder auf der linken oder der rechten Seite des Bildschirms dargestellt, gefolgt von einem kurzen Hinweis, der eines der Kästchen aufblitzen lässt. Nach diesem kurzen Hinweis erscheint das Ziel (normalerweise eine einfache Form) in einem der Kästchen, und der Antwortende muss erkennen, ob das Ziel links oder rechts erscheint und die entsprechende Taste so schnell und genau wie möglich drücken. Zwischen jedem Versuch gibt es einen Leerbildschirm von 2500 bis 5000 ms, und der gesamte Prozess wird eine vorab festgelegte Anzahl von Versuchen wiederholt, die vom Forscher bestimmt wurde. Kritischerweise wird ein Ziel, das auf der gleichen Seite des kurz angedeuteten Ortes erscheint, als gültiger Hinweis betrachtet (z.B. ein Blitz an der Stelle, an der ein Ziel erscheinen soll), was zu besserer Leistung (schnellerer Reaktionszeit und Genauigkeit) führt. Andernfalls wird das Ziel, das auf der gegenüberliegenden Seite erscheint, als ungültiger Hinweis betrachtet (z.B. ein Ort, an dem nach einem kurzen Hinweis nichts Relevantes passiert), was zu schlechterer Leistung führt.
Die Möglichkeit besserer Leistungen mit gültigen Hinweisen, auch bekannt als der Cueing-Effekt, ist mit einem Aufmerksamkeits-Scheinwerfer verbunden. Im Wesentlichen schlug Posner vor, dass, wenn ein Individuum einen Hinweis sieht, seine visuelle Aufmerksamkeit auf diesen Hinweis gerichtet ist, was die visuelle Verarbeitung am angedeuteten (oder beachteten) Ort beeinflusst. Da menschliche Aufmerksamkeit ein begrenzter Prozess ist (d.h. wir können nicht alles gleichzeitig in unserer visuellen Szene beachten), erklärt dies auch die verringerte Leistung, wenn das Ziel vom angedeuteten (oder beachteten) Ort entfernt erscheint. Daher reagieren die Personen bei gültigen Hinweisen schneller, weil ihre Aufmerksamkeit bereits auf den angedeuteten Ort gerichtet ist. Im Gegensatz dazu führen ungültige Hinweise zu langsamerer Leistung, da ihre Aufmerksamkeit vom Ziel abgelenkt ist und zurück zum Zielort verschoben werden muss.
Darüber hinaus haben zusätzliche Studien in diesem Bereich ebenfalls gezeigt, dass eine Art von Hinweis die Aufmerksamkeitsorientierung beeinflussen kann. Zum Beispiel, wenn die Forscher ein schematisches Gesicht mit dem Blick nach links oder rechts auf dem Bildschirm präsentierten, beeinflusste dies den Cueing-Effekt weiter, was scheinbar darauf hindeutet, dass Menschen „fest verdrahtet“ sind, automatisch den Blick oder die Augeninformationen anderer zu folgen.
Es gibt viele weitere Variationen der Posner-Aufgabe, die Folgendes offenbarten:
- Unsere Aufmerksamkeitsverschiebungen zu einem Ziel erfolgen, bevor wir unsere Augen bewegen
- Räumliche Aufmerksamkeit ist nicht vollständig von der bewussten visuellen Eingabe abhängig
- Kinder mit ADHS haben eine niedrigere Leistung sowohl unter gültigen als auch unter ungültigen Bedingungen als das typische Kind
- Patienten mit Parkinson neigen dazu, eine niedrigere Leistung zu zeigen, da ihre Orientierungsfähigkeit in Richtungen beeinträchtigt ist
- Der Cueing-Effekt ist altersabhängig, da ältere Antwortende eine niedrigere Leistung zeigen im Vergleich zu jüngeren Antwortenden.
Über diese Ergebnisse und andere Hinweisvariationen wird sich der aktuelle Leitfaden auf den Aufbau des grundlegenden Posners Paradigmas mit Blick-Hinweisen konzentrieren, indem Buchstaben-Zielfiguren auf beiden Seiten der Anzeige präsentiert werden, gefolgt von dem schematischen Gesicht in der zentralen Anzeige. Um systematisch von Anfang bis Ende vorzugehen, umfasst dieser Leitfaden die Schritte in 5 Teilen:
- Variablenbestimmung (IVs & DVs)
- Frame-Einrichtung
- Stimuli-Einrichtung
- Ereignis-Einrichtung
- Block-Einrichtung
Darüber hinaus werden wir die folgenden herunterladbaren Stimuli verwenden, die schematische Gesichter mit den Blickrichtungen rechts, links und neutral enthalten, um das experimentelle Paradigma zu konstruieren.
Linker Blick
Rechter Blick
Neutraler Blick
In der Anzeige-Sequenz, die die Teilnehmer sehen werden (siehe Abbildung 1 unten), wird der Versuch bestehen aus:
- 900 ms Fixationskreuz
- 900 ms neutraler Blick
- 200 ms rechten oder linken Blick
- Präsentation des Zielbuchstabens (B oder Y) bis zur Reaktionstaste
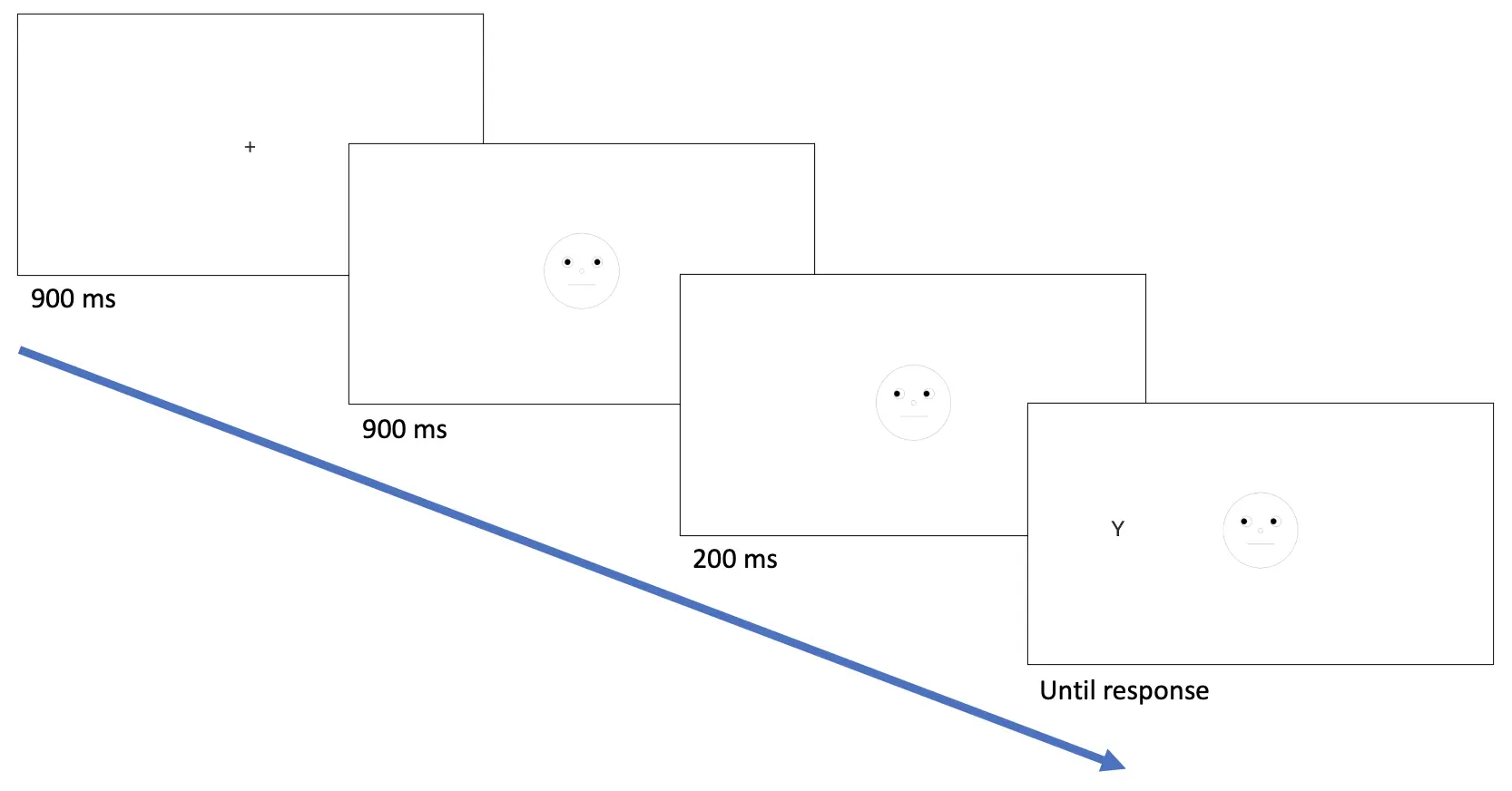 Abbildung 1. Anzeige eines Beispielversuchs. In diesem Beispiel eines gültigen Versuchs ist das Ziel Y kongruent auf der linken Seite präsentiert, angedeutet durch den Blick. Nach dem Zielbuchstaben ist das Drücken der Y-Taste mit einer korrekten Antwort verbunden und das Drücken der B-Taste mit einer falschen Antwort verbunden.
Abbildung 1. Anzeige eines Beispielversuchs. In diesem Beispiel eines gültigen Versuchs ist das Ziel Y kongruent auf der linken Seite präsentiert, angedeutet durch den Blick. Nach dem Zielbuchstaben ist das Drücken der Y-Taste mit einer korrekten Antwort verbunden und das Drücken der B-Taste mit einer falschen Antwort verbunden.
Je nach Ziel werden wir die Studie so gestalten, dass der Antwortende den Zielbuchstaben (B oder Y) unterscheiden und die entsprechende Taste auf der Tastatur (B-Taste oder Y-Taste) drücken muss. Kritisch wird die Hälfte der Versuche das Ziel am angedeuteten Ort präsentieren (d.h. der Buchstabe erscheint auf der gleichen Seite des Blick-Hinweises), was sowohl links (Ziel erscheint links, gefolgt vom linken Blick-Hinweis) als auch rechts (Ziel erscheint rechts, gefolgt vom rechten Blick-Hinweis) auftreten kann.
Mit diesem Kontext und dieser Einführung lassen Sie uns mit der Erstellung der ersten Aufgabe beginnen, indem wir die wichtigen Variablen für diese Studienkonstruktion bestimmen.
Teil I: Variablenbestimmung mit Lavanced Factor Tree
Im Einklang mit den anderen Studienleitfäden ist die Bestimmung der Variablen und deren Stufen (oder Kategorien) der wichtige erste Schritt zur Planung der Bedingungen und der anschließenden Versuchsanordnung. Um zu beginnen, verweisen Sie auf den Factor Tree auf der linken Seite der Labvanced-Anzeige, um die Faktoren (oder unabhängigen Variablen) und die entsprechenden Stufen zu bestimmen. Für die Posner Gaze Cueing Task werden die Faktoren und deren Stufen wie folgt aussehen:
Versuchsgruppe → Hauptversuche
- Faktor 1 - Blick
- Stufe 1 - Gültig (Zielbuchstabe erscheint am Blick-Ort)
- Stufe 2 - Ungültig (Zielbuchstabe erscheint am gegenüberliegenden Blick-Ort)
- Faktor 1 - Blick
- Faktor 2 - Buchstabe
- Stufe 1 - Y (korrekte Antwort = Y-Tastendruck)
- Stufe 2 - B (korrekte Antwort = B-Tastendruck)
- Faktor 2 - Buchstabe
- Faktor 3 - Ort
- Stufe 1 - Links (Ziel erscheint links vom Blick unabhängig von Faktor Blick)
- Stufe 2 - Rechts (Ziel erscheint rechts vom Blick unabhängig von Faktor Blick)
- Faktor 3 - Ort
Es ist erwähnenswert, dass Faktor 1 die Hauptunabhängige Variable für die Forschungsuntersuchung ist und Faktor 2 & 3 nur für die Studienkonstruktion spezifiziert werden. Die Bestimmung des Zielbuchstabens hilft später bei der Konstruktion der Ereignisse, um Labvanced zu erlauben, die Tastenanschläge zu bewerten und korrekte (oder inkorrekte) Antworten aufzuzeichnen. Was den Standortfaktor betrifft, so dient dieser dazu, eine gleichmäßige Präsentationsrate sowohl für die linke als auch für die rechte Seite des Blicks für beide Zielbuchstaben sicherzustellen, um die Validität der Untersuchung aufrechtzuerhalten. Später könnte ein Forscher die Faktoren 2 & 3 während des Datenkompilierungsprozesses zusammenführen, um die Bewertung des Blick-Hinweis-Effekts anhand der Reaktionszeiten und Genauigkeiten vorzubereiten.
Die vollständige Anzeige dieses Setups im Factor Tree ist auch unten dargestellt (siehe Abbildung 2A). Mit diesem 2 X 2 X 2 orthogonalen Setup wird Labvanced 8 verschiedene Bedingungen erstellen (siehe Abbildung 1B), mit jeder Faktorenkombination. Wie dargestellt, führt dies zu allen möglichen Kombinationen von Blick X Ziel X Ort. Außerdem können wir die Anzahl der Versuche pro Bedingung bestimmen, und wir werden 4 Versuche pro Bedingung festlegen – insgesamt 32 Versuche.
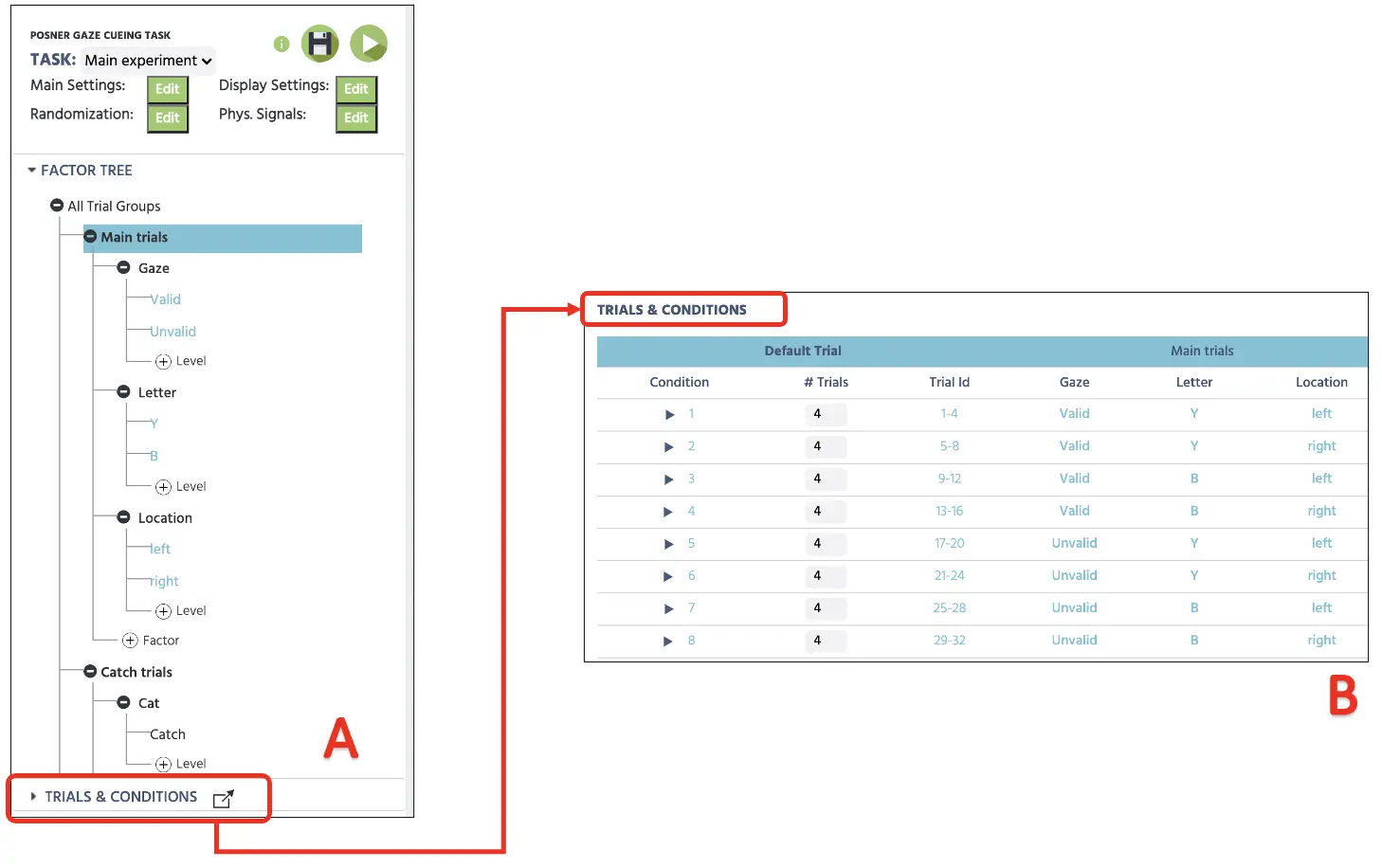 Abbildung 2. Anfängliches Canvas-Setup, das die Bestimmung von Faktoren mit Stufen im Factor Tree (A) und nachfolgende Kombinationen mit 4 Versuchen in jeder Bedingung (B) darstellt.
Abbildung 2. Anfängliches Canvas-Setup, das die Bestimmung von Faktoren mit Stufen im Factor Tree (A) und nachfolgende Kombinationen mit 4 Versuchen in jeder Bedingung (B) darstellt.
Darüber hinaus wäre es wichtig, auch Fangversuche für diese Studie einzurichten, bei denen kein Zielbuchstabe angezeigt wird. Dies ist eine wichtige Manipulation, um die Aufmerksamkeit des Teilnehmers zu berücksichtigen und sicherzustellen, dass die Antwort nicht auf den willkürlichen Tastenschlägen (oder „Tastenmaschinerie“) beruht. Wir werden 5 Fangversuche erstellen, die während der Hauptversuche dazwischen geschaltet werden, bei denen die Teilnehmer ihre Antwort ohne Präsentation eines Zielbuchstabens zurückhalten müssen. Um dies zu implementieren, werden wir innerhalb des gleichen Factor Tree eine neue Versuchsgruppe erstellen und sie Fangversuche nennen. Dann können wir sowohl den Faktor als auch die Stufe als Fang benennen und 4 Versuche festlegen; siehe Abbildung 3 unten). Wiederum werden diese 4 Fangversuche zufällig unter den anderen Hauptversuchen präsentiert, was insgesamt 36 Versuche in diesem Setup ergibt.
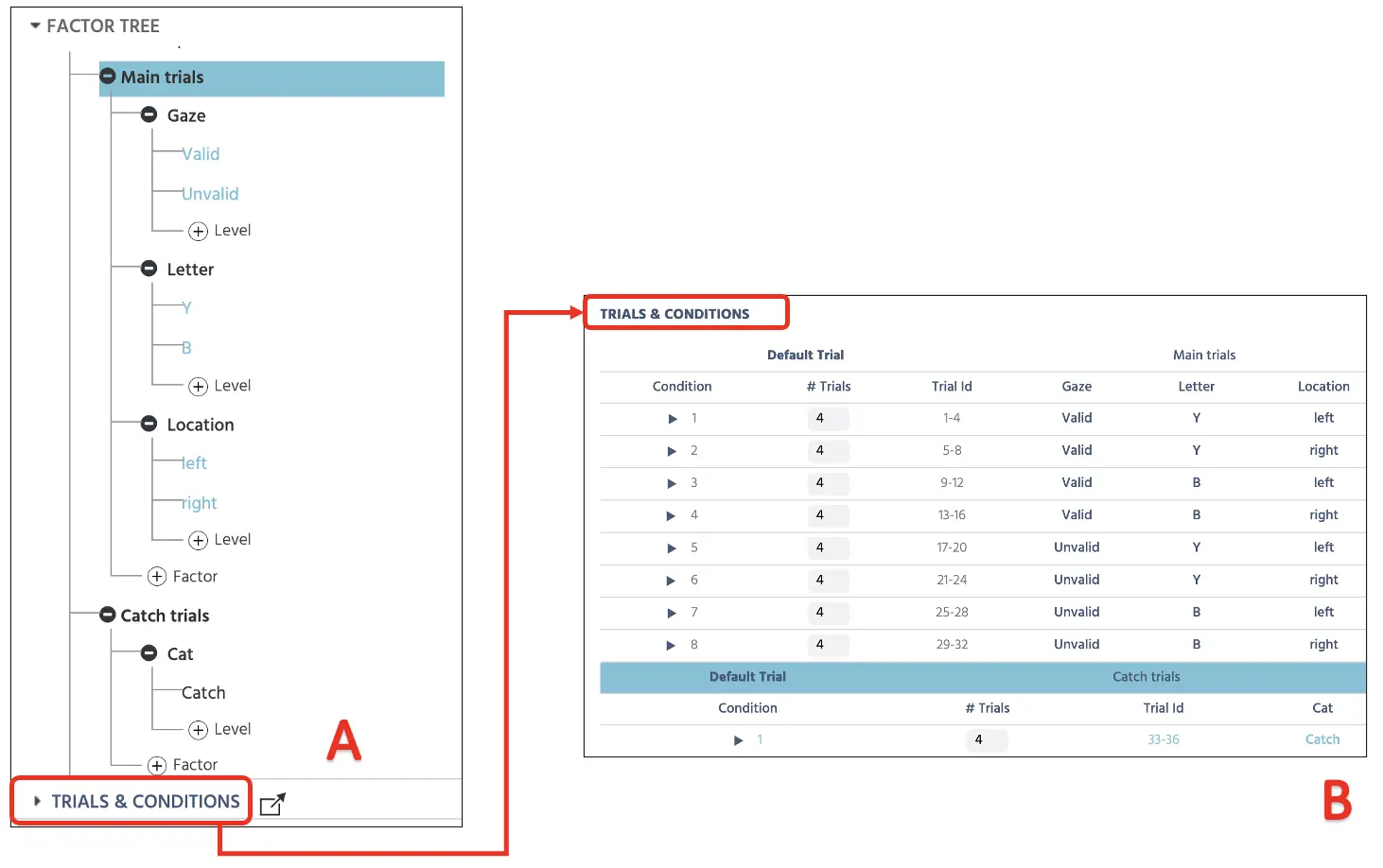 Abbildung 3. Canvas-Setup, das das Setup der Fangversuche darstellt (A) und die vier Versuche innerhalb der Versuche & Bedingungen (B).
Abbildung 3. Canvas-Setup, das das Setup der Fangversuche darstellt (A) und die vier Versuche innerhalb der Versuche & Bedingungen (B).
Für die Zufälligkeit der Versuche wird Labvanced automatisch die Präsentation der Versuche abhängig von den Zufallseinstellungen variieren (siehe Abbildung 4). Die Standardeinstellung bleibt als erste **Zufalls-**Option, die eine zufällige Versuchssequenz generiert; dies könnte aber zuvor mit verschiedenen Optionen ( Festgelegt durch Design oder Manuell) festgelegt werden. Für jetzt wird die aktuelle Studie ohne Einschränkungen mit Zufall fortfahren, und dies wird die Präsentation der Versuche unter den Haupt- und Fangversuchen zufällig variieren. Für weitere Informationen zu den Zufallseinstellungen nutzen Sie bitte diesen Link für weitere Informationen.
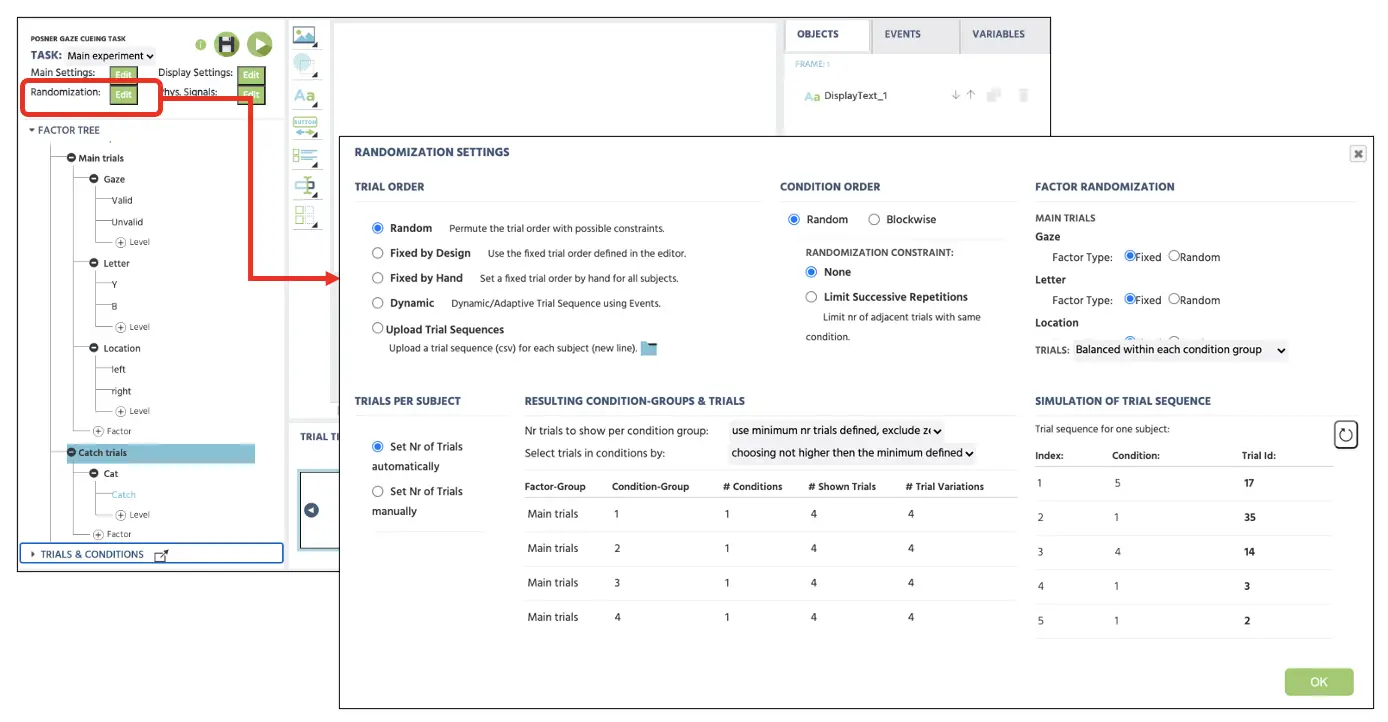 Abbildung 4. Anzeige der Zufallseinstellung mit ausgewählter Zufallsoption zur zufälligen Präsentation der Versuche ohne Einschränkungen.
Abbildung 4. Anzeige der Zufallseinstellung mit ausgewählter Zufallsoption zur zufälligen Präsentation der Versuche ohne Einschränkungen.
Teil II: Frame-Einrichtung
Der zweite Teil dieses Leitfadens wird Frames (Stimuli-Präsentation) erstellen, die die Teilnehmer während ihrer Teilnahme sehen werden. Wiederum wird die aktuelle Posner Gaze Cueing Task dem oben genannten allgemeinen Verfahren folgen (siehe Abbildung 1). Wie dargestellt, beginnt ein Versuch mit einem Fixationskreuz (Frame 1) für 900 ms, gefolgt von der Präsentation des neutralen Blicks (Frame 2) für 900 ms. Danach geht es weiter zum rechts oder links orientierten Blick, der für 200 ms angezeigt wird, und schließlich wird der Zielbuchstabe angezeigt, der bis zur Reaktionstaste bleibt. Hier werden die Teilnehmer „Y“ oder „B“ drücken, abhängig vom angezeigten Zielbuchstaben.
Der Aufbau dieser Frames beginnt, indem Sie auf die Canvas-Schaltfläche unten in der Labvanced-Anzeige klicken (siehe Abbildung 5A). Durch viermaliges Klicken werden 4 neue Frames angezeigt, und es wäre ideal, jeden Frame sofort zu benennen (z.B. Fixation, neutral, Blick, Ziel), um die Organisationsstruktur der Studie aufrechtzuerhalten (siehe Abbildung 5B). Bevor Sie fortfahren, ist es wichtig, auf den Standardversuch zu klicken, um sicherzustellen, dass diese Zeile hervorgehoben ist (siehe Abbildung 5C). Dieser Teil dient als Standardvorlage für alle nachfolgenden Bedingungen. Solange sie hervorgehoben ist, wirken sich Änderungen in den 4 Frames auf alle Bedingungen aus (d.h. das Hinzufügen eines Fixationskreuzes im 1. Frame wirkt sich auf alle 36 Versuche aus), sodass dies praktisch ist, um unnötige und sich wiederholende Setups zu vermeiden.
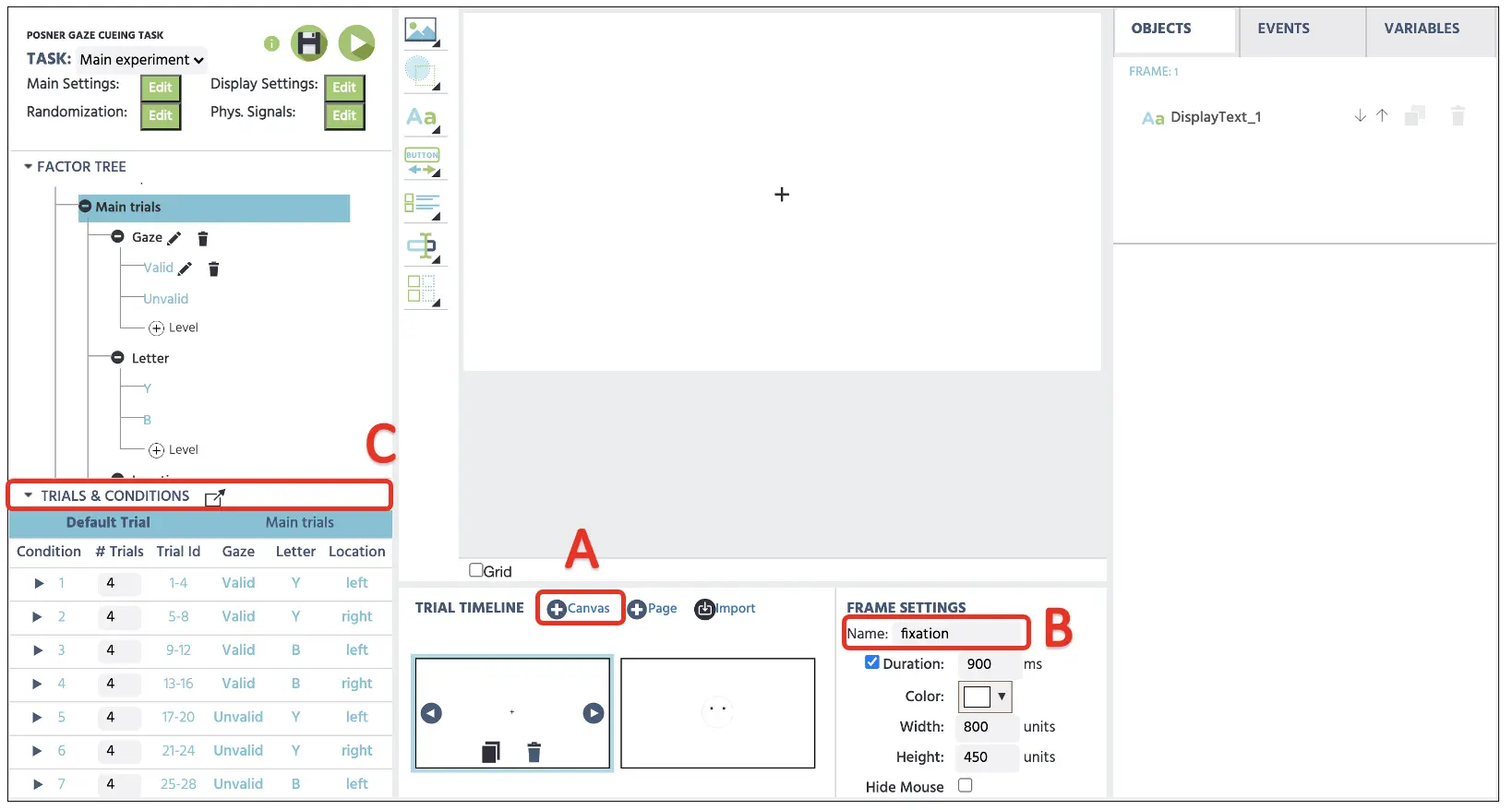 Abbildung 5. Anzeige des Beispielversuchs mit Canvas-Frame-Erstellung (A), Frame-Änderungsoption (B) und Hervorhebung des Standardversuchs (C).
Abbildung 5. Anzeige des Beispielversuchs mit Canvas-Frame-Erstellung (A), Frame-Änderungsoption (B) und Hervorhebung des Standardversuchs (C).
Teil III: Stimuli-Einrichtung (Fixationskreuz, Blickanzeige und Zielpräsentation)
Frame 1
Mit den vier Frames, die wir im vorherigen Teil vorbereitet haben, werden wir nun die einzelnen Stimuli in jedem Frame festlegen, beginnend mit dem Fixationskreuz im 1. Frame. Dazu können wir mit einem Klick auf Text anzeigen (siehe Abbildung 6A) das Textfeld in die Canvas einfügen. Hier können wir das + im Feld mit einer Schriftgröße von 36 eintippen und es in der Mitte der Anzeige positionieren. Wir könnten auch die spezifischen X- & Y-Koordinaten im Objekteigenschaften auf der rechten Seite für die genaue zentrale Position eingeben. Wenn wir das Bild hochladen möchten, das das Fixationskreuz oder andere Stimuli enthält, kann die Medien-Option (siehe Abbildung 6B) Bilder, Videos, Audios usw. präsentieren. Wir werden einfach das Kreuz im Anzeige-Text eintippen, aber wir werden schließlich die Medienoption nutzen, um die Blickbilder zu präsentieren. Schließlich werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen. Obwohl diese vier Versuche getrennt gruppiert sind, werden sie zufällig zusammen mit den Hauptversuchen präsentiert.
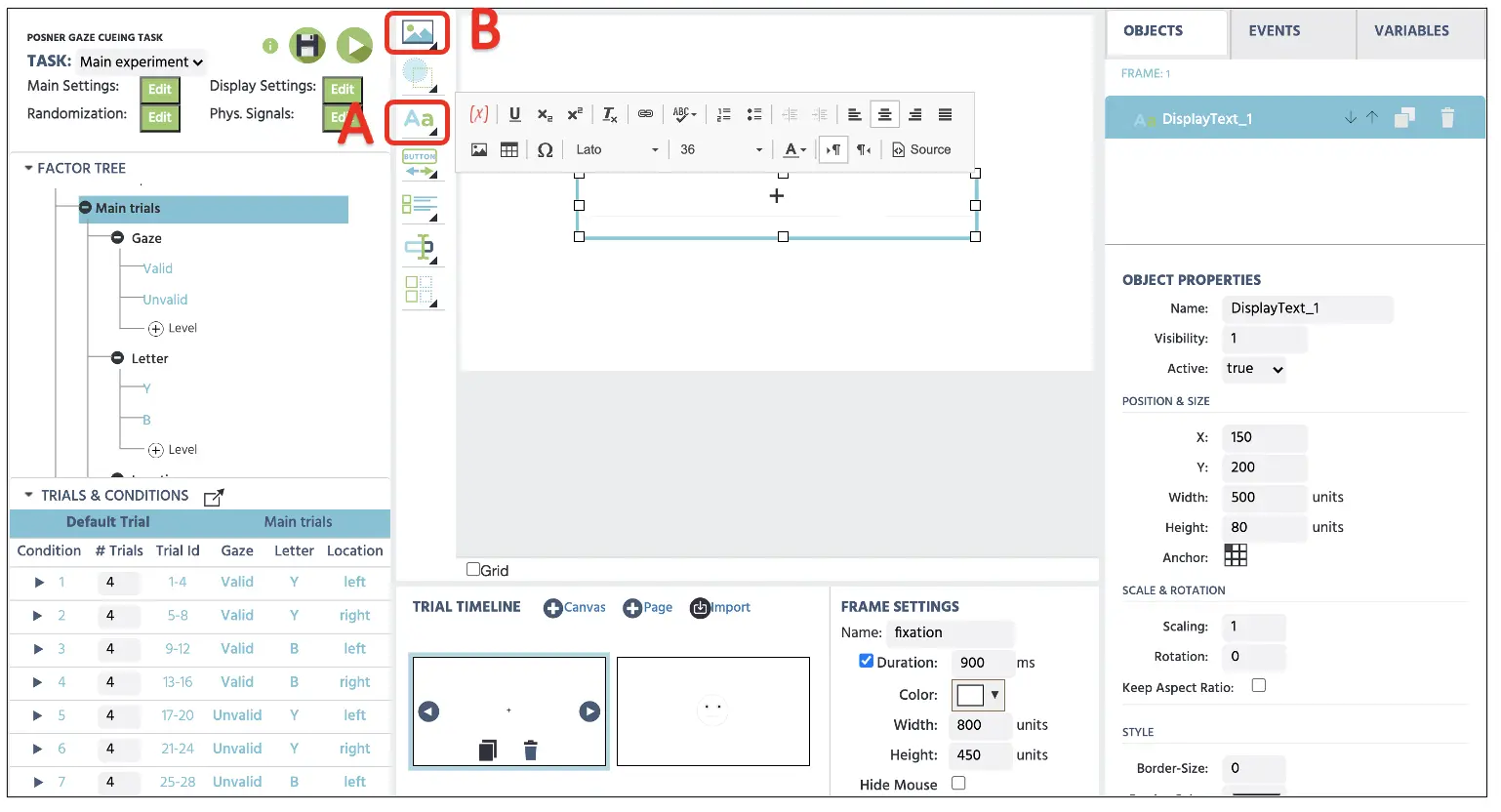 Abbildung 6. Anzeige der Erstellung des Fixationsframes mit der Option Text anzeigen (A). Bilder, Videos und Audios können über die Medienoption angezeigt werden (B).
Abbildung 6. Anzeige der Erstellung des Fixationsframes mit der Option Text anzeigen (A). Bilder, Videos und Audios können über die Medienoption angezeigt werden (B).
Frame 2
Bevor wir fortfahren, stellen Sie sicher, dass wir den Standardversuch ausgewählt haben (siehe Abbildung 5 oben), damit die Präsentation des neutralen Blicks während der 36 Versuche implementiert wird. Um den 2. Frame mit dem neutralen Blick zu erstellen, klicken Sie auf die Medien-Option (siehe Abbildung 5 oben) und wählen Sie Bild. Dies öffnet die Bild-Eigenschaften im Canvas-Display, welche wir mit den Objekteigenschaften auf der rechten Seite verwenden können, um Position, Größe und das Bild auszuwählen, das wir aus dem Labvanced-Dateispeicher anzeigen möchten. Lassen Sie uns auf das Dateisymbol klicken (siehe Abbildung 7), um den Dateispeicher zu durchsuchen und alle Blickbilder zu importieren.
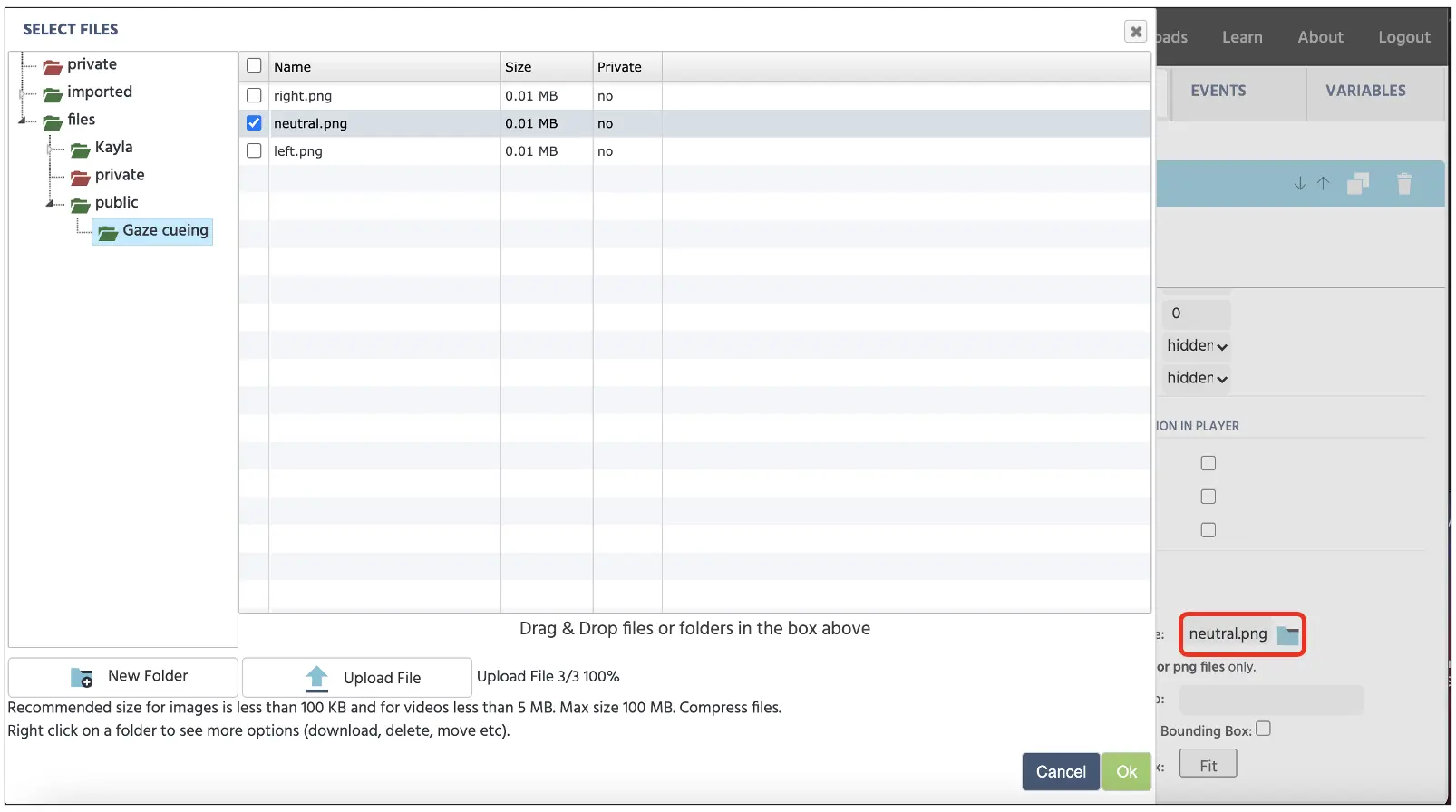 Abbildung 7. Anzeige des Dateispeichers, der über das Dateisymbol im roten Feld aufgerufen wird.
Abbildung 7. Anzeige des Dateispeichers, der über das Dateisymbol im roten Feld aufgerufen wird.
Nachdem wir den neutralen Blick aus dem Speicher ausgewählt haben, wird die Canvas das Bild entsprechend der Ausrichtung und Größe anzeigen, die durch die Objekteigenschaften auf der rechten Seite des Displays festgelegt ist (siehe Abbildung 8 unten). Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen.
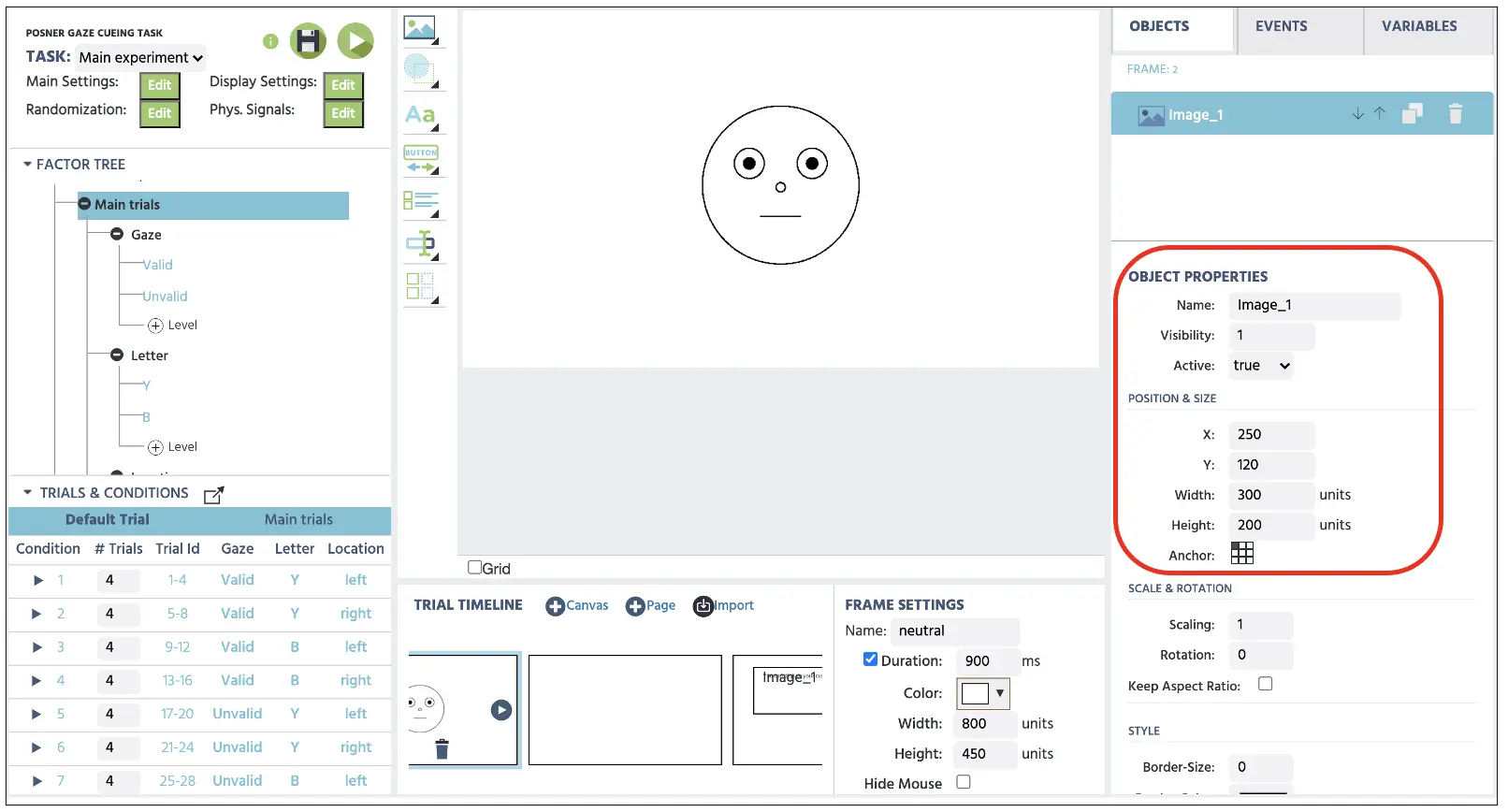 Abbildung 8. Anzeige des neutralen Blickbildes mit den Objekteigenschaften im roten Feld.
Abbildung 8. Anzeige des neutralen Blickbildes mit den Objekteigenschaften im roten Feld.
Frame 3
Das Setup des 3. Frames folgt dem gleichen Verfahren wie die Anweisungen für den 2. Frame oben. Allerdings werden wir den Standardversuch nicht auswählen und jede Bedingung auswählen, um sie als Leitlinie zur Anzeige einer spezifischen Blickrichtung (linker oder rechter Blick) zu verwenden. Wenn wir uns die Bedingung 1 ansehen (stellen Sie sicher, dass Bedingung 1 ausgewählt ist), präsentieren wir vier Versuche von gültigen Versuchen, die das Ziel „Y“ auf der linken Seite des Blicks anzeigen. Nachdem wir die gleiche Medienoption verwendet haben und den Dateispeicher geöffnet haben, stellen Sie sicher, dass wir den linken Blick (left.webp) auswählen, um ihn im Canvas anzuzeigen (siehe Abbildung 9) unten. Dies wird dann auf alle vier Versuche in dieser ersten Bedingung angewendet. Stellen Sie sicher, dass das Bild die gleichen Optionen hat wie der neutrale Blick, indem Sie die Objekteigenschaften überprüfen. Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen.
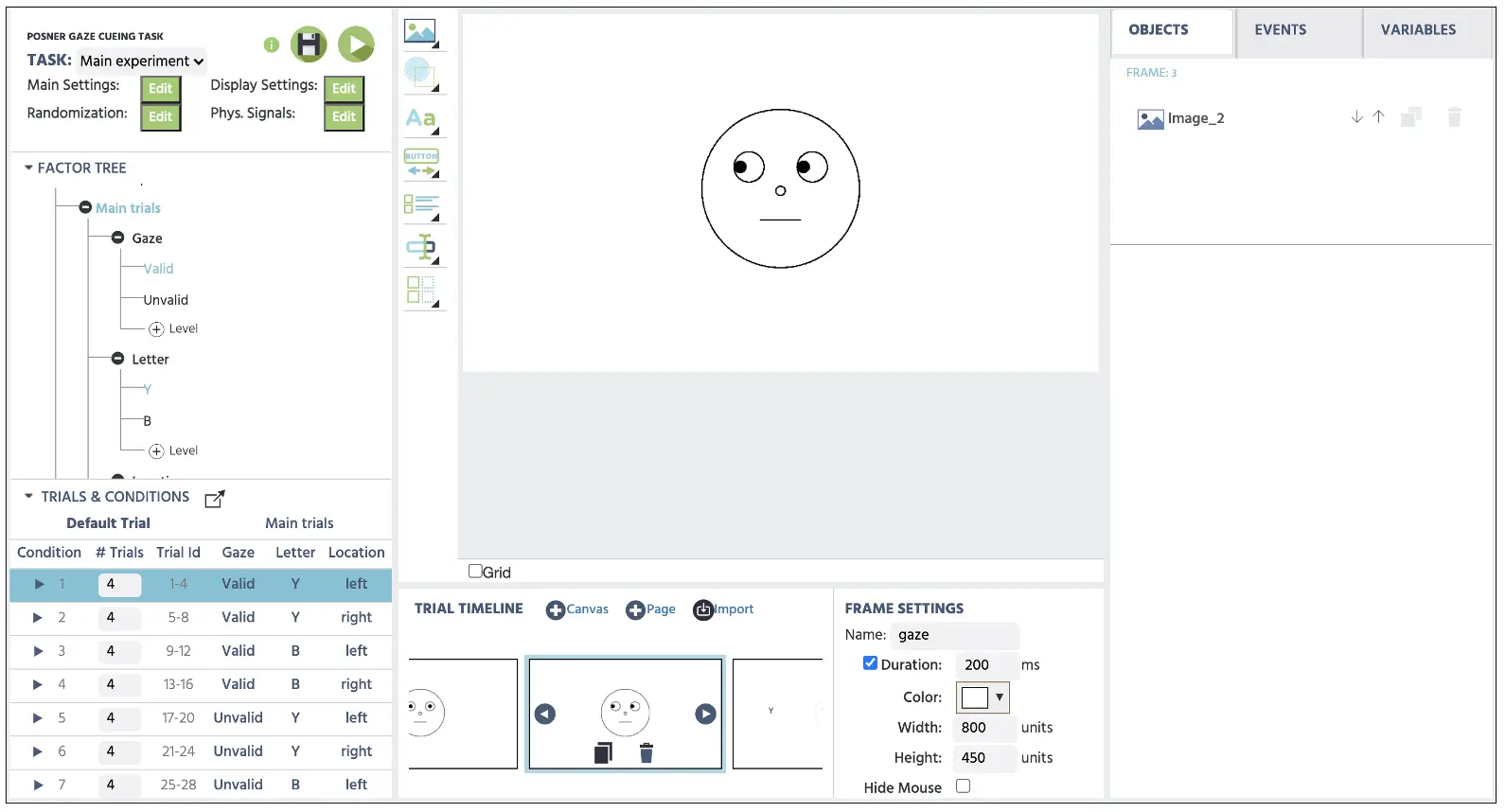 Abbildung 9. Anzeige des 3. Frames mit dem linken Blickbild, nachdem die Auswahl der ersten Bedingung erfolgt ist.
Abbildung 9. Anzeige des 3. Frames mit dem linken Blickbild, nachdem die Auswahl der ersten Bedingung erfolgt ist.
Frame 4
In diesem Frame werden wir dasselbe Blickbild aus dem dritten Frame mit denselben Objekteigenschaften anzeigen. Dies wird mit der Anzeige des Zielbuchstabens kombiniert, der mit jeder Bedingung assoziiert ist. Wiederum, indem wir uns die Bedingung 1 ansehen (stellen Sie sicher, dass Bedingung 1 ausgewählt ist), präsentieren wir vier gültige Versuche, die das Ziel „Y“ auf der linken Seite des Blicks anzeigen. Hierbei wird der Zielbuchstabe neben dem Blick angezeigt und genau das Fixationskreuz-Darstellung widerspiegeln, indem wir auf Text anzeigen klicken und den Buchstaben „Y“ eintippen. Wiederum, indem wir auf die Versuche & Bedingungen verweisen, stellen Sie sicher, dass das Ziel auf der linken Seite des Blicks angezeigt wird. Da dies ein gültiger Versuch ist, sollte der Blick auf den gleichen Zielort gerichtet sein (siehe Abbildung 10 unten). Wiederum wird die Stimuli-Einrichtung auf alle vier Versuche in jeder Bedingung angewendet, und wir können weiterhin auf die Versuche & Bedingungen verweisen, um den Rest der Bedingungen festzulegen. Mit diesem Abschluss haben wir nun alle Stimuli in diesem Abschnitt angezeigt und werden nun zu Teil 4 übergehen, um die logische Sequenz zu programmieren, die Labvance in jedem Frame initiieren wird. Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen, aber wir werden keine Zielbuchstaben anzeigen, da die Teilnehmer in dieser Zeit ihre Antwort zurückhalten müssen.
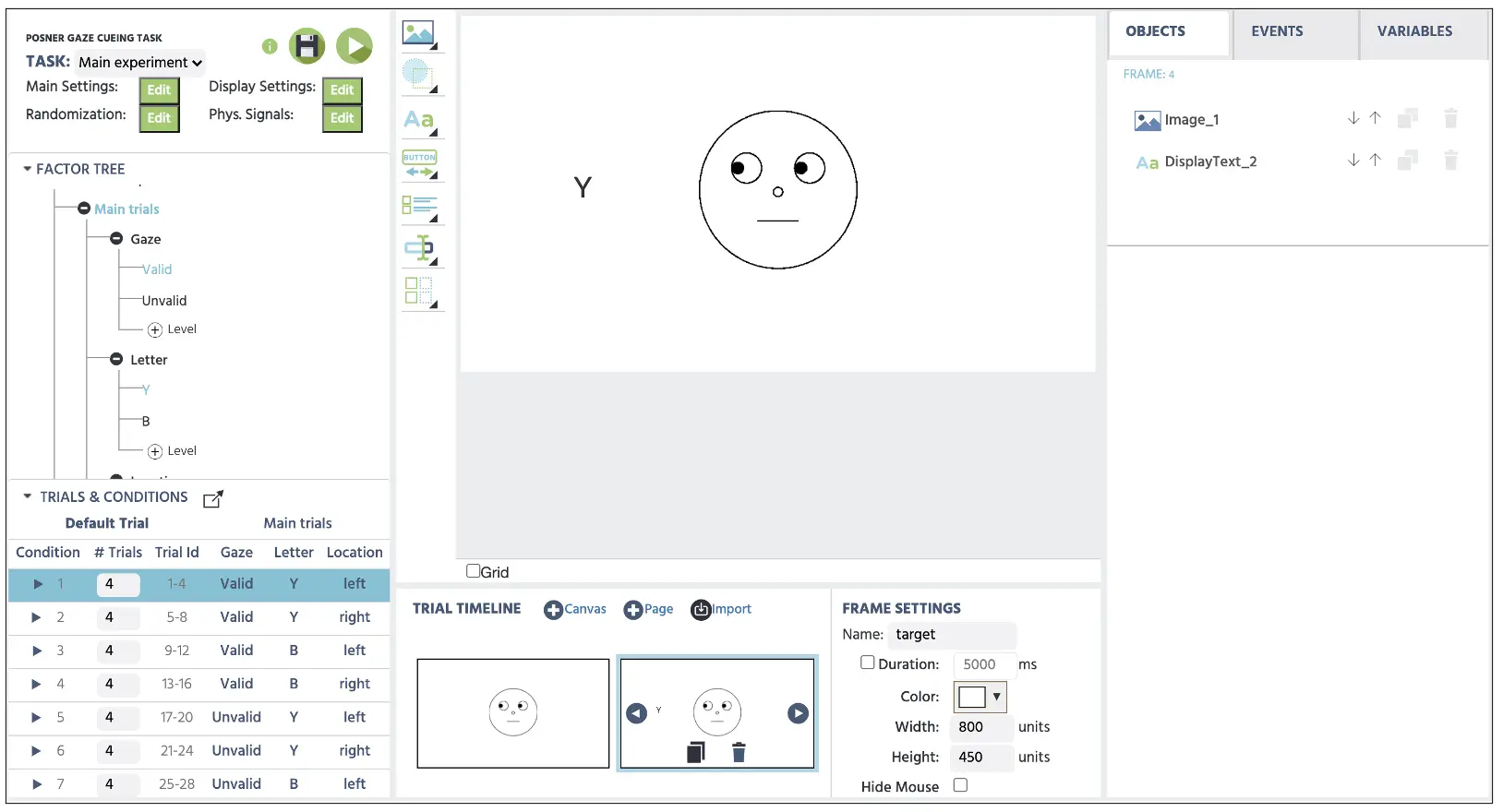 Abbildung 10. Anzeige des 4. Frames mit dem linken Blickbild und der Zielbuchstabenanzeige, die der Auswahl der ersten Bedingung folgt.
Abbildung 10. Anzeige des 4. Frames mit dem linken Blickbild und der Zielbuchstabenanzeige, die der Auswahl der ersten Bedingung folgt.
Teil IV: Ereignis-Einrichtung (Programmierung der Anzeigedauer, Bewertung der Antwort und Aufzeichnung der Variablen)
Bevor wir fortfahren, werden wir zwei neue Variablen (Reaktionszeit und korrekte Antwort) erstellen, die als abhängige Variablenmessungen dienen werden. Um neue Variablen zu erstellen, klicken wir auf die Variablen in der oberen rechten Anzeige und wählen Sie Variable hinzufügen. Aus dem neuen Variablenfenster werden wir mit folgenden Schritten für die im Folgenden angegebenen Namen und Typen fortfahren (auch in Abbildung 11 unten). Diese Variablen speichern wichtige Verhaltensmessungen, wie schnell der Teilnehmer den Zielbuchstaben abgegrenzt hat und dessen jeweilige Genauigkeitsleistung.
- Reaktionszeit - gemessen in Millisekunden ab Frame-Beginn
- Korrekt - Antwortgenauigkeit (1=korrekt; 0=inkorrekt)
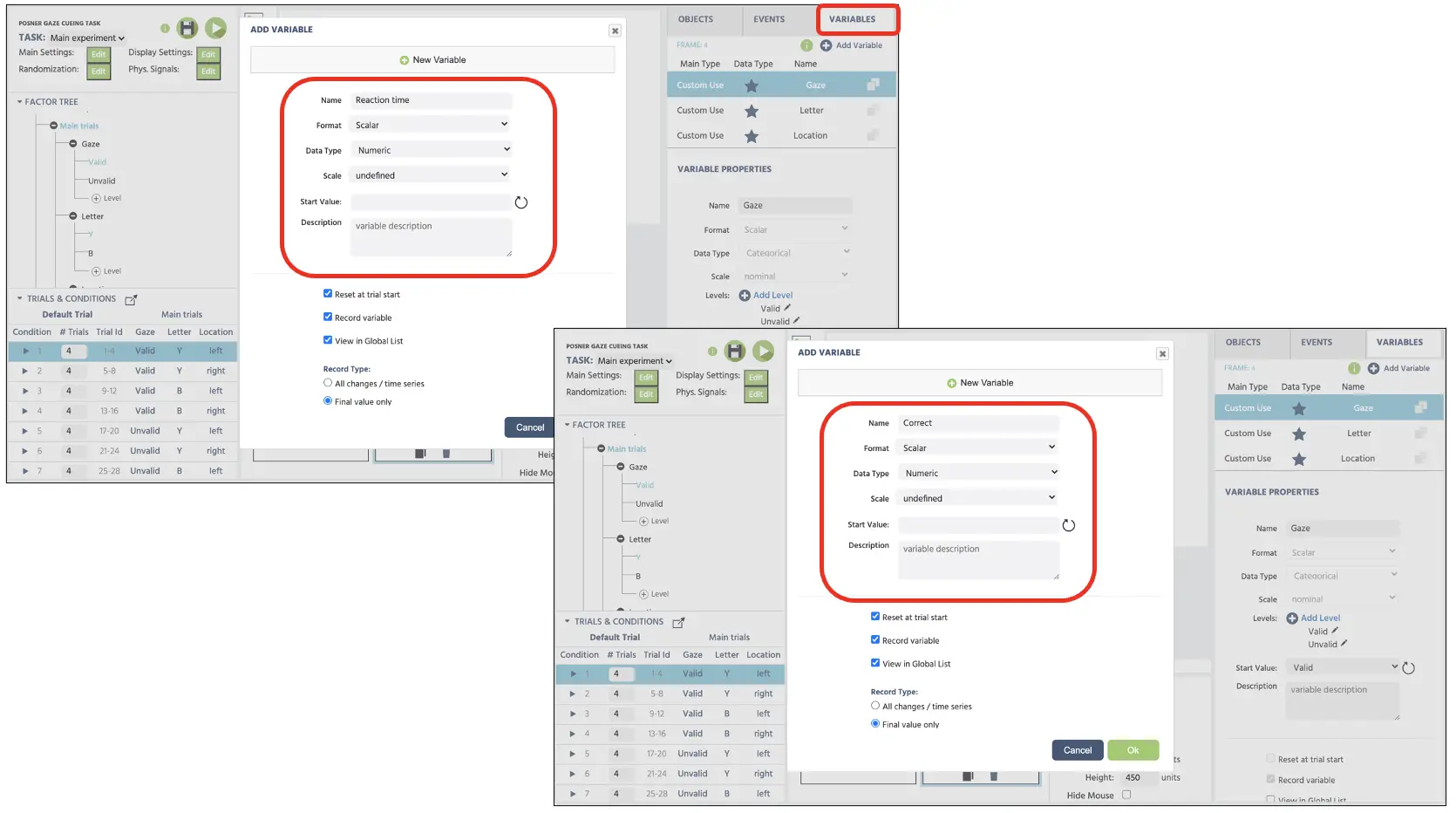 Abbildung 11. Anzeige der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp eingestellt.
Abbildung 11. Anzeige der Erstellung neuer Variablen (Reaktionszeit & korrekt). Beide Variablen sind mit dem numerischen Datentyp eingestellt.
Im Anschluss an die allgemeine Frame-Sequenz aus Teil II (siehe Abbildung 1 oben) werden wir die Ereignisstruktur separat pro Frame erstellen, beginnend mit der Programmierung der Fixationskreuzdarstellung für 900 ms.
Frame 1 Ereignis: Fixationskreuzdarstellung
In diesem Frame möchten wir das Fixationskreuz für 900 ms in der Mitte der Anzeige präsentieren. Daher besteht die logische Sequenz in diesem Frame aus:
- Sobald der Frame beginnt
- 900 ms warten
- Und dann zum nächsten Frame springen
Um dieses Ereignis zu erstellen, klicken Sie auf die Ereignisse in der oberen rechten Ecke neben den Variablen und wählen Sie Frame-Ereignis (nur in diesem Frame). In der ersten Dialogfenster können wir das Ereignis als „Start“ benennen (Abbildung 12A) und auf „Weiter“ klicken, um zur Auslöseroption zu gelangen. Hier ist der Auslöser-Typ Versuchs- und Frame-Auslöser → Frame-Start (welcher der 1. logischen Sequenz oben folgt; siehe auch Abbildung 12B). Mit diesem Auslöser möchten wir die 900 ms Frame-Verzögerungsaktion initiieren (2. logische Sequenz); daher kann dies mit Aktion hinzufügen → Verzögerte Aktion (Zeitaufruf) festgelegt werden, und 900 ms im Verzögerungsfeld festgelegt werden (siehe Abbildung 12C). Schließlich klicken Sie für die letzte logische Sequenz auf Aktion hinzufügen im Aktionssequenzfeld und setzen Sie fort mit Sprungaktion → Springe zu → wähle den nächsten Frame (siehe Abbildung 12D). Labvanced wird immer dieser logischen Sequenz für die Präsentation des Fixationskreuzes für alle Versuche mit diesem Setup folgen. Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen.
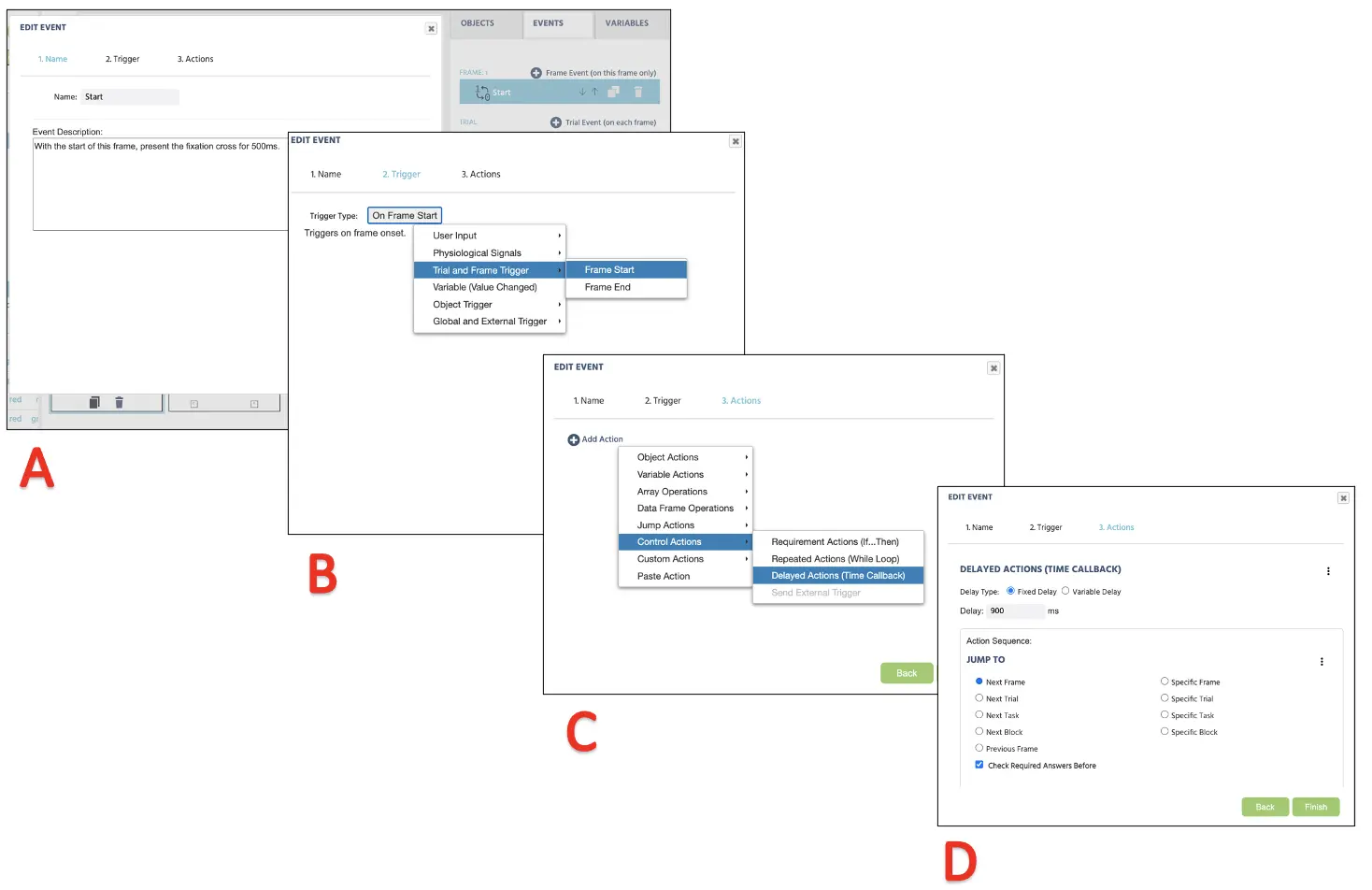 Abbildung 12. Anzeige der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) nach Benennung des Ereignisses (A), Auslöser (B), Festlegung der Aktion (C) und Aktion (D) Ausführung.
Abbildung 12. Anzeige der Ereigniserstellung für die Präsentation des Fixationskreuzes (Frame 1) nach Benennung des Ereignisses (A), Auslöser (B), Festlegung der Aktion (C) und Aktion (D) Ausführung.
Frame 2 Ereignis: Neutrale Blickdarstellung
In diesem Frame möchten wir den neutralen Blick für 900 ms präsentieren. Das Setup wird mit dem Fixationskreuz oben übereinstimmen mit der folgenden logischen Sequenz:
- Sobald der Frame beginnt, der den neutralen Blick enthält
- 900 ms warten
- Und dann zum nächsten Frame springen
Das Verfahren bleibt dasselbe wie in Abbildung 12 oben. Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen.
Frame 3 Ereignis: Orientierte Blickdarstellung
In diesem Frame möchten wir den linken oder rechten orientierten Blick für 200 ms präsentieren. Das Setup wird dem Fixationskreuz- und neutralen Blick-Setup oben ähneln mit der folgenden logischen Sequenz:
- Sobald der Frame beginnt, der den orientierten Blick und den Zielbuchstaben enthält
- 200 ms warten
- Und dann zum nächsten Frame springen
Abgesehen von der kürzeren Dauer der 200 ms-Anzeige bleibt der Rest des Verfahrens identisch mit Abbildung 12 oben. Wiederum werden wir die oben genannten Schritte auch für die zweite Gruppe von Fangversuchen wiederholen.
Frame 4 Ereignis Teil 1: Präsentation des Zielbuchstabens und Bewertung des Tastendrucks (Hauptversuche)
- In diesem letzten Frame möchten wir den Zielbuchstaben präsentieren und das Programm die Tasteneingabe des Teilnehmers bewerten und deren Richtigkeit bestimmen. Daher ist die logische Sequenz, die wir anstreben, folgendermaßen: Sobald der Frame mit dem orientierten Blick und dem Zielbuchstaben beginnt
- Warten auf die Tasteneingabe (ausgelöst durch „Y“ oder „B“ Tastendrücke)
- Vergleichen Sie den Tastendruck mit dem Zielbuchstaben in dieser Bedingung unter Bezugnahme auf die Variablen „Buchstabe“ (d.h. wenn in Bedingung 1 der Buchstabe Y ist, prüfen Sie, ob er mit der Tasteneingabe übereinstimmt).
- Wenn der Buchstabe und der Tastendruck übereinstimmen, weisen Sie Korrekt == 1 zu, was eine korrekte Antwort anzeigt
- Andernfalls weisen Sie Korrekt == 0 zu, was eine falsche Antwort anzeigt
- Und dann springe zu Nächster Versuch
Wie bereits erwähnt, verlangt die Hauptaufgabe von den Teilnehmern, auf den präsentierten Buchstaben zu achten und mit dem gleichen Buchstaben-Tastendruck zu diskriminieren. Anschließend werden wir das Labvanced-Programm auffordern, sich auf den Buchstabenfaktor unter Versuche & Bedingungen zu beziehen und zu bewerten, ob die Tasteneingabe des Teilnehmers mit dem Buchstaben in dieser Bedingung übereinstimmt. Um dieses Ereignis zu erstellen, beginnen wir damit, die Ereignisse auszuwählen und Frame-Ereignis (nur in diesem Frame) auszuwählen. Hier können wir das Ereignis als „Reaktion“ benennen. Da dieses Ereignis die Tasteneingabe des Teilnehmers zur Anzeige bringt, wäre der Auslöser Benutzereingabe → Tastenauslöser. Hier können wir zwei zulässige Tastendrücke festlegen (siehe Abbildung 13 unten), nämlich „Y“ und „B.“ Nach dem Klicken auf „Weiter“ werden wir die Aktionssequenz mit Kontrollaktionen → Anforderung Aktionen (Wenn...dann) fortsetzen.
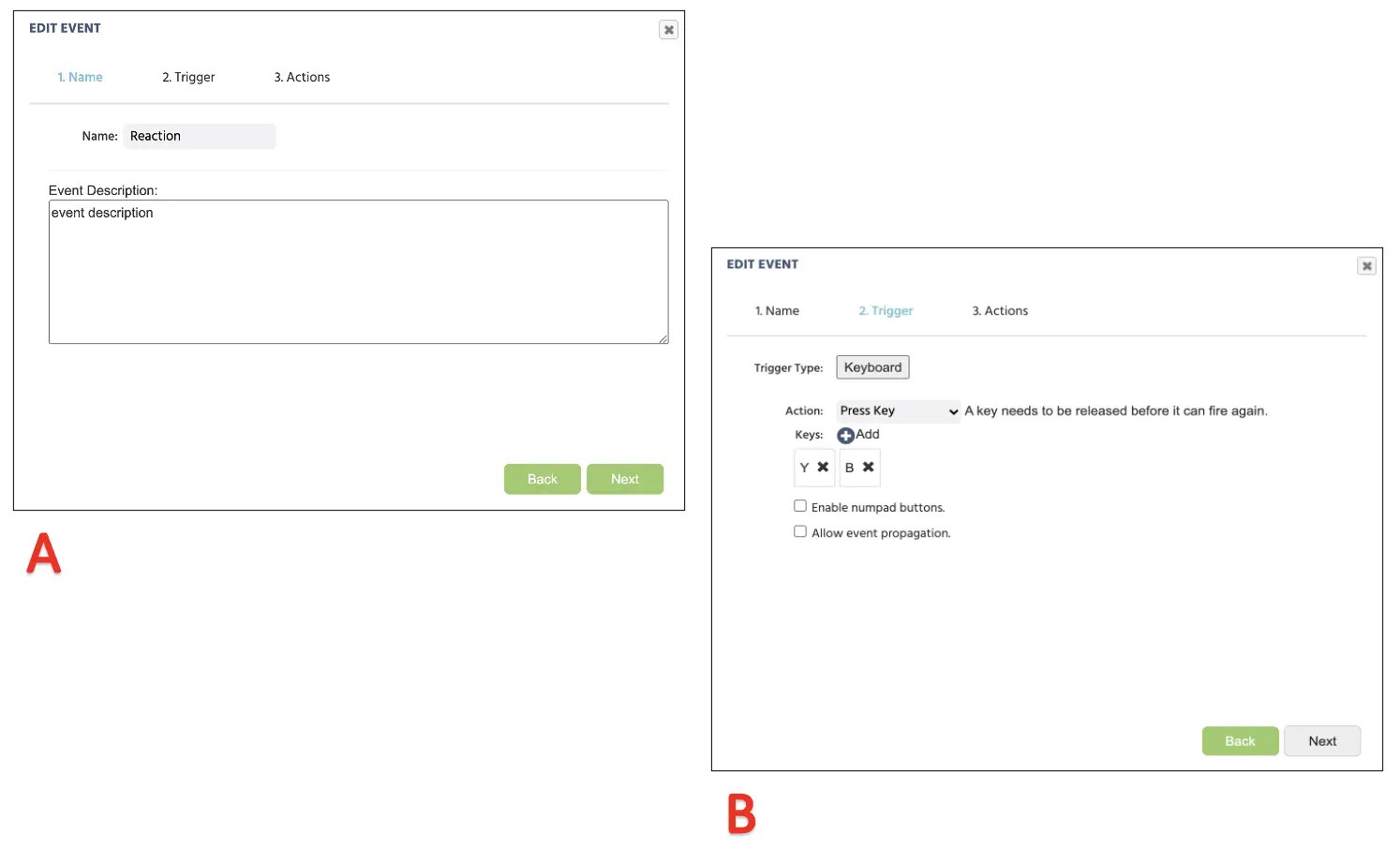 Abbildung 13. Anzeige der Ereigniserstellung zur Zuweisung der Tasteneingaben, die nach der Benennung des Ereignisses (A), dem zugewiesenen Auslösertyp (B) erfolgen.
Abbildung 13. Anzeige der Ereigniserstellung zur Zuweisung der Tasteneingaben, die nach der Benennung des Ereignisses (A), dem zugewiesenen Auslösertyp (B) erfolgen.
An diesem Punkt trennt das bedingte Argument, das durch die Anforderungsaktionen festgelegt wurde, sich in zwei Teile: Wenn und Dann. Wir werden zunächst den Wenn-Teil erstellen, der Bedingungen festlegt, denen das Programm folgen soll, bevor wir mit dem Dann-Teil fortfahren.
Für den Wenn-Teil werden wir festlegen, ob die Tasteneingabe mit der festgelegten Buchstabendarstellung übereinstimmt, die unter den Versuchen & Bedingungen festgelegt wurde. Klicken Sie auf das linke Bleistiftsymbol, um eine Variable auszuwählen und legen Sie sie auf Buchstabe fest (Abbildung 14A). Auf der rechten Seite legen Sie den String-Wert fest und tippen „Y“ ein (Abbildung 14B). Darunter klicken Sie auf die Anforderung, um ein weiteres Set von Bedingungen zu erstellen, und setzen die neue linke Seite als Auslöser(Tastatur) → ID der Taste (Abbildung 14C). Auf der rechten Seite legen wir erneut den String-Wert fest und tippen „Y“ erneut ein (Abbildung 14D). Die Grundidee dieser Konfiguration lautet:
- WENN der Zielbuchstabe in dieser Bedingung Y ist und der Tastendruck ebenfalls Y ist, DANN führe X-Aktion aus
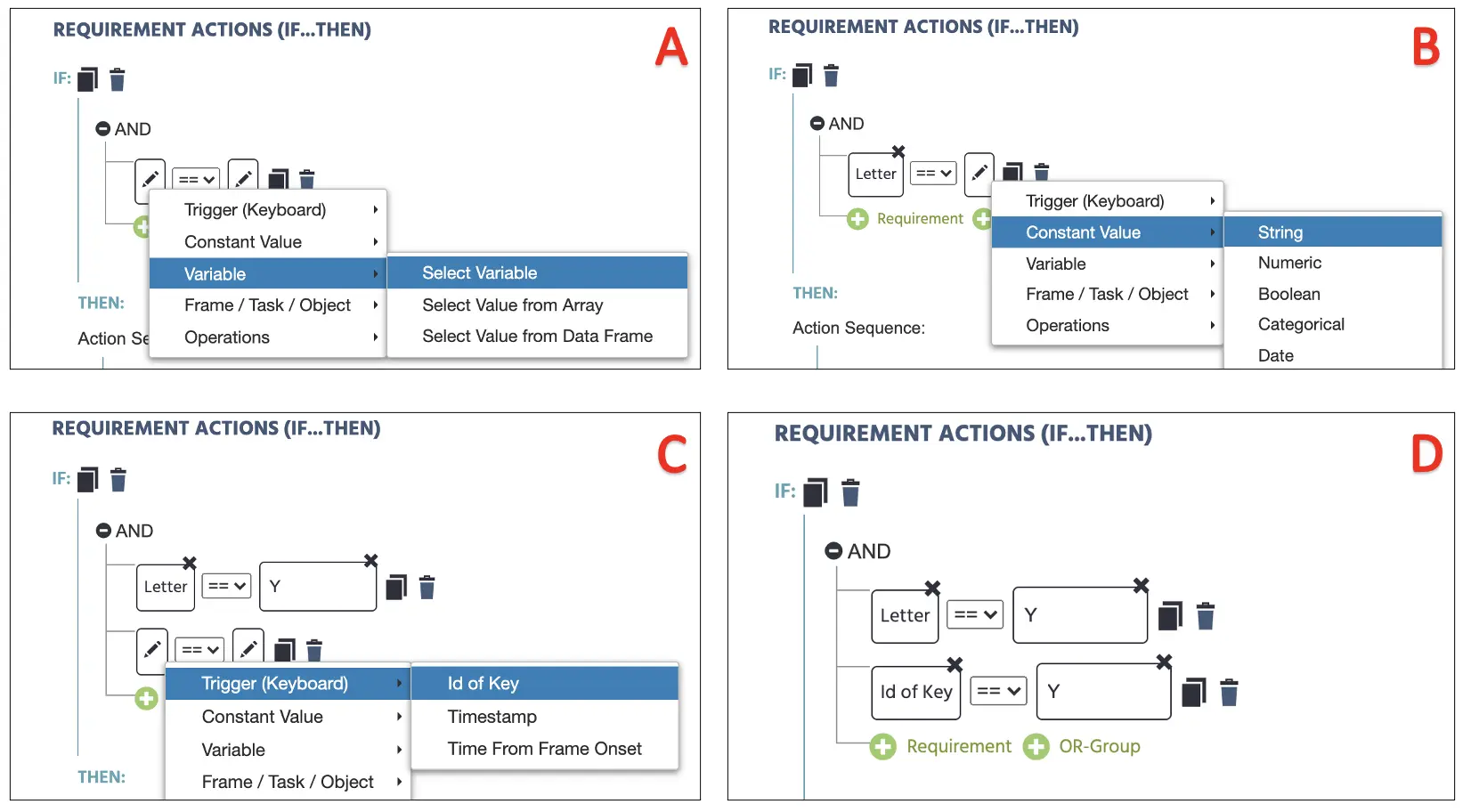 Abbildung 14. Anzeige der Ereigniserstellung zur Zuweisung von Tasteneingaben nach Variablenbestimmung (A), assoziierte Bedingungen (B) und Tastendruckbewertung (C & D).
Abbildung 14. Anzeige der Ereigniserstellung zur Zuweisung von Tasteneingaben nach Variablenbestimmung (A), assoziierte Bedingungen (B) und Tastendruckbewertung (C & D).
Im Folgenden werden wir den Dann-Teil unten festlegen, um festzulegen, welchen Maßnahmenweg das Programm folgen wird. Da der Tastendruck „Y“ die korrekte Antwort ist, wenn der Zielbuchstabe „Y“ ist, werden wir dies als korrekte Antwort aufzeichnen, indem wir dem Korrekt-Variablenwert 1 zuweisen. Dazu klicken wir auf Aktion hinzufügen → Variablenaktionen → Zuweisen/Protokollieren der Variablen. Auf der linken Seite wählen Sie die Korrekt-Variable aus, und auf der rechten Seite fügen Sie den Konstantenwert → numerischen Wert von 1 ein (siehe Abbildung 15).
 Abbildung 15. Anzeige der Ereigniserstellung nach Abbildung 14. Das Zuweisen/Protokollieren bestimmt die Korrekt-Variable mit 1 = korrekt (0 wenn nicht) wenn die Bedingungen mit der Konfiguration in Abbildung 14 erfüllt sind.
Abbildung 15. Anzeige der Ereigniserstellung nach Abbildung 14. Das Zuweisen/Protokollieren bestimmt die Korrekt-Variable mit 1 = korrekt (0 wenn nicht) wenn die Bedingungen mit der Konfiguration in Abbildung 14 erfüllt sind.
Anschließend klicken wir auf Sonst Wenn Fall hinzufügen, um die korrekte „B“-Buchstabenreaktion ebenfalls festzulegen. Das Verfahren bleibt dasselbe wie oben, außer dass wir auf der rechten Seite beide Buchstabenanzeige- und Tastendruckbedingungen „B“ eintippen. Der Dann-Teil bleibt gleich, wo wir die Korrekt-Variable mit dem numerischen Wert 1 speichern werden (siehe Abbildung 16 unten).
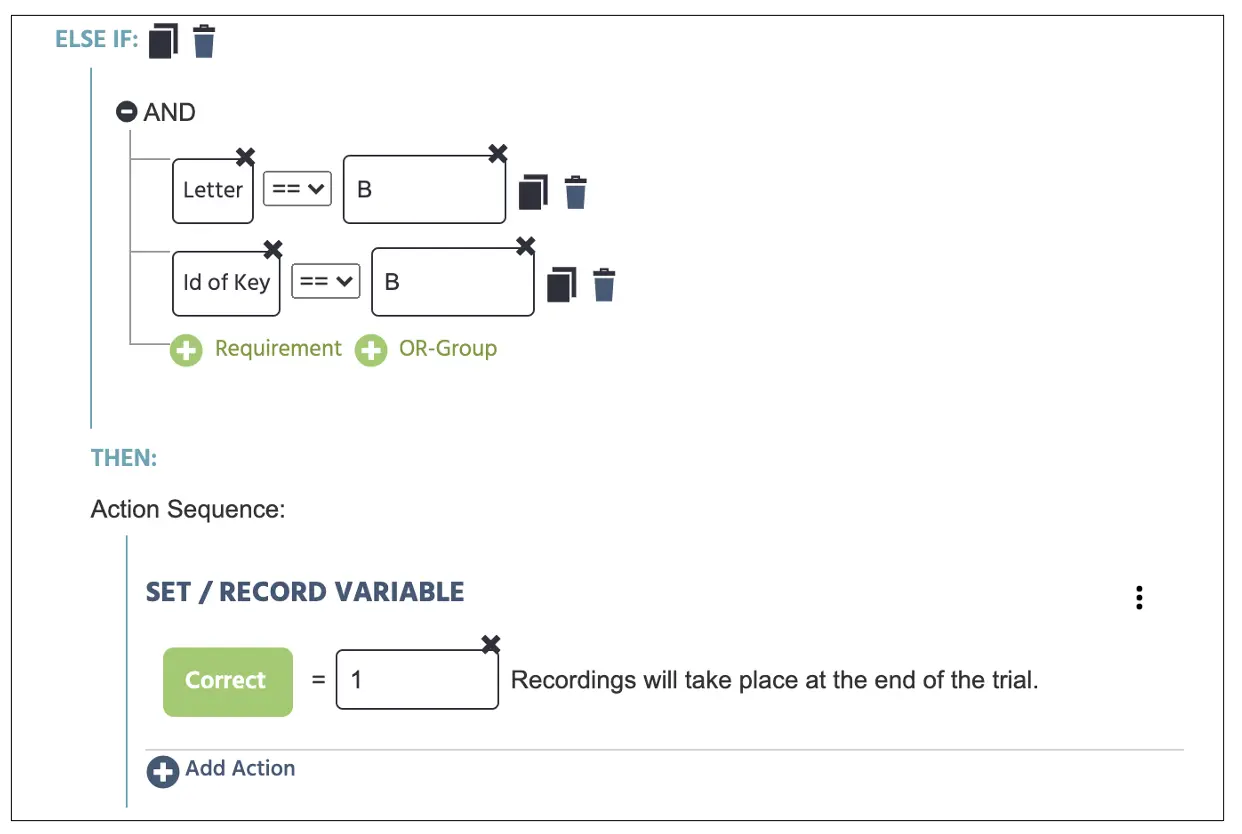 Abbildung 16. Anzeige der Ereigniserstellung zur Zuweisung der Tasteneingaben für den Sonst Wenn-Fall jenseits der Abbilder 14 & 15.
Abbildung 16. Anzeige der Ereigniserstellung zur Zuweisung der Tasteneingaben für den Sonst Wenn-Fall jenseits der Abbilder 14 & 15.
Schließlich müssen wir die letzte Bedingung festlegen, wo die Tasteneingabe die oben genannten korrekten Antwortanforderungen nicht erfüllt. Hier können wir auf den Sonst Fall hinzufügen klicken und die Korrekt-Variable auf einen numerischen Wert von 0 festlegen (siehe Abbildung 17A unten). Mit dieser finalen Konfiguration wird Labvanced jede falsche Antwort als 0 in der Korrekt-Variable in jedem gegebenen Versuch speichern. Anschließend klicken wir erneut auf Aktion hinzufügen → Variablenaktionen → Zuweisen/Protokollieren der Variable und wählen die Reaktionsvariable auf der linken Seite aus. Auf der rechten Seite fahren wir mit Frame/ Aufgabebereich/ Objekt → Frame → Zeit ab Frame-Beginn fort (siehe Abbildung 17B unten). Hiermit bitten wir das Programm nicht nur darum, die Korrekt-Antworten zu bewerten und aufzuzeichnen, sondern auch die Reaktionszeit in ms zu messen. Schließlich benötigen wir die Versuche, die nach jeder Antwort fortgesetzt werden, sodass wir Aktion hinzufügen → Sprungaktionen auswählen und Nächster Versuch auswählen. Klicken Sie auf Fertig, um die endgültige Ereigniserstellung für diese Studie abzuschließen.
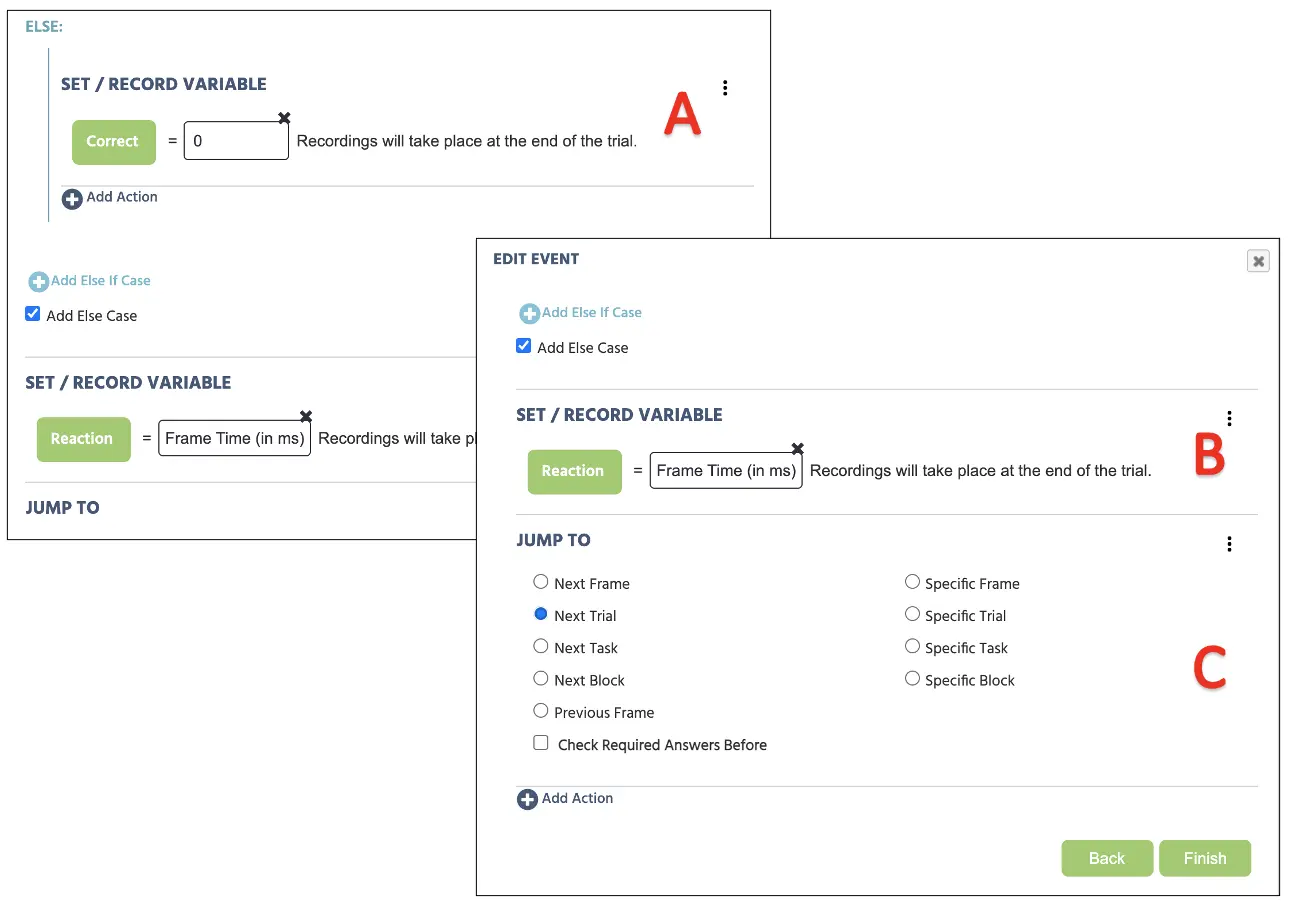 Abbildung 17. Anzeige der fortlaufenden Ereigniserstellung aus Abbildung 16 für die Zuweisung der Tasteneingaben für den Sonst Fall (A), Reaktionszeitaufzeichnung (B) und Sprungaktion zum nachfolgenden Versuch (C).
Abbildung 17. Anzeige der fortlaufenden Ereigniserstellung aus Abbildung 16 für die Zuweisung der Tasteneingaben für den Sonst Fall (A), Reaktionszeitaufzeichnung (B) und Sprungaktion zum nachfolgenden Versuch (C).
Frame 4 Ereignis Teil II: Keine Buchstabenpräsentation und Bewertung der Tasteneingabe (Fangversuche)
Für den letzten Frame, der die Fangversuche betrifft, präsentieren wir nicht den Zielbuchstaben, und der Blick bleibt 2000 ms. Hier würde jeder Tastendruck als falsch betrachtet, und die korrekte Antwort wäre die Zurückhaltung jeglicher Tasteneingabe für die gesamte Dauer von 2000 ms. Hier haben wir zwei Ereignisse. Das erste Ereignis bezieht sich auf das Warten von 2000 ms, und das zweite Ereignis wird jede Tasteneingabe protokollieren und den Wert 0 der Korrekt-Variable zuweisen. Daher sind die beiden logischen Sequenzen, die wir anstreben:
Erstes Ereignis: 2000ms Frame-Zeit
- Sobald der Frame mit dem orientierten Blick beginnt
- 2000 ms warten
- Springe zum nächsten Versuch
Zweites Ereignis: Tasteneingabebewertung
- WENN die Tasteneingabe „Y“ oder „B“ ist, DANN zuweisen Korrekt == 0, was eine falsche Antwort anzeigt
Um das erste Ereignis zu erstellen, klicken Sie auf die Ereignisse in der oberen rechten Ecke neben den Variablen und wählen Sie Frame-Ereignis (nur in diesem Frame). In der ersten Dialogfenster können wir das Ereignis als „Start“ benennen (siehe auch Abbildung 12A oben) und auf „Weiter“ klicken, um zur Auslöseroption zu gelangen. Hier ist der Auslösertyp Versuchs- und Frame-Auslöser → Frame Start (der 1. logischen Sequenz oben folgend; siehe auch Abbildung 12B). Mit diesem Auslöser möchten wir die 2000 ms Frame-Verzögerungsaktion initiieren (2. logische Sequenz); daher kann dies mit Aktion hinzufügen → Verzögerte Aktion (Zeitaufruf) und setzen Sie 2000 ms im Verzögerungsfeld (siehe auch Abbildung 12D oben).
Für die Erstellung des zweiten Ereignisses wird das allgemeine Verfahren der Abbildung 14 folgenden. Bei der Anforderungsaktion (Wenn...Dann)-Sektion werden wir beide Tasteneingaben als die falschen Antworten mit dem ODER-Setup zuweisen (siehe Abbildung 18). Dies ermöglicht dem Programm zu erkennen, ob „B“ ODER „Y“ Tastendrücke als Korrekt == 0 verbucht werden. Klicken Sie auf Fertig, um die endgültige Ereigniserstellung für diese Studie abzuschließen.
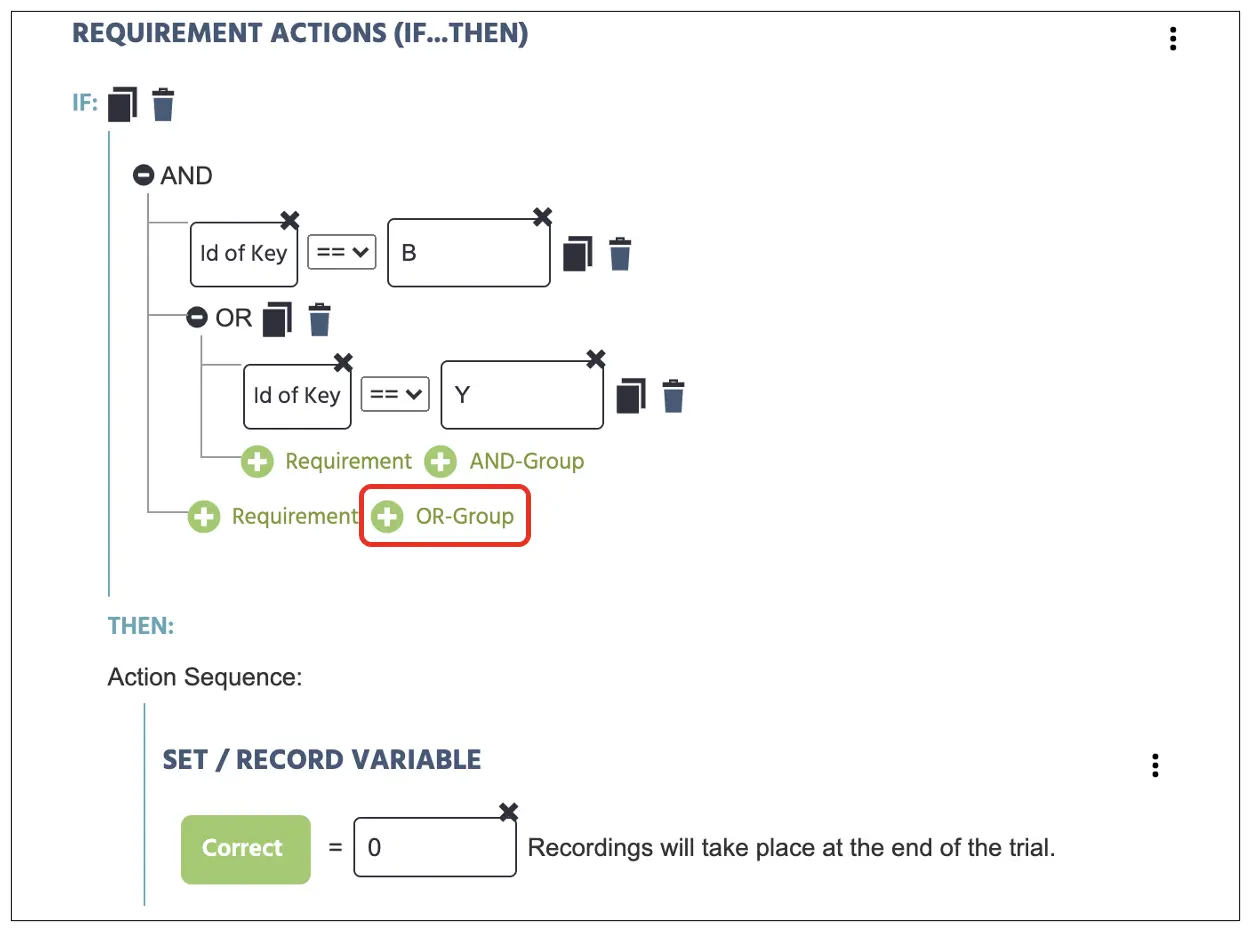 Abbildung 18. Anzeige der Ereigniserstellung für die Fangversuche, die beide Tasteneingaben als die 0 (inkorrekte) Antwort zuweisen. Beide Tasten werden in der logischen Sequenz kombiniert, indem die ODER-Option (im roten Feld angezeigt) gedrückt wird.
Abbildung 18. Anzeige der Ereigniserstellung für die Fangversuche, die beide Tasteneingaben als die 0 (inkorrekte) Antwort zuweisen. Beide Tasten werden in der logischen Sequenz kombiniert, indem die ODER-Option (im roten Feld angezeigt) gedrückt wird.
Teil V: Block-Einrichtung & Abschließende Anmerkung
Mit diesem abschließenden Setup haben wir nun ein funktionierendes Posner Gaze Cueing Paradigma, das aus 36 Versuchen in diesem Block besteht. Je nach Studie müssen Forscher möglicherweise mehrere Blöcke von 36 Versuchen den Teilnehmern präsentieren, je nach ihrer Untersuchung. Glücklicherweise ermöglicht es Labvanced, die Studie auf der Studiendesign-Seite zu organisieren, um verschiedene Blöcke zu organisieren (siehe Abbildung 19). Darüber hinaus können wir auch den Zufallsseparator implementieren, wie im Sessions-Spalte zu sehen ist (siehe Abbildung 19). Das Vorhandensein dieses Separators ermöglicht eine Gegenbalance der Blöcke innerhalb der beiden horizontalen Separatoren, die Forschern bei ihren spezifischen Manipulationen und theoretischen Untersuchungen helfen können.
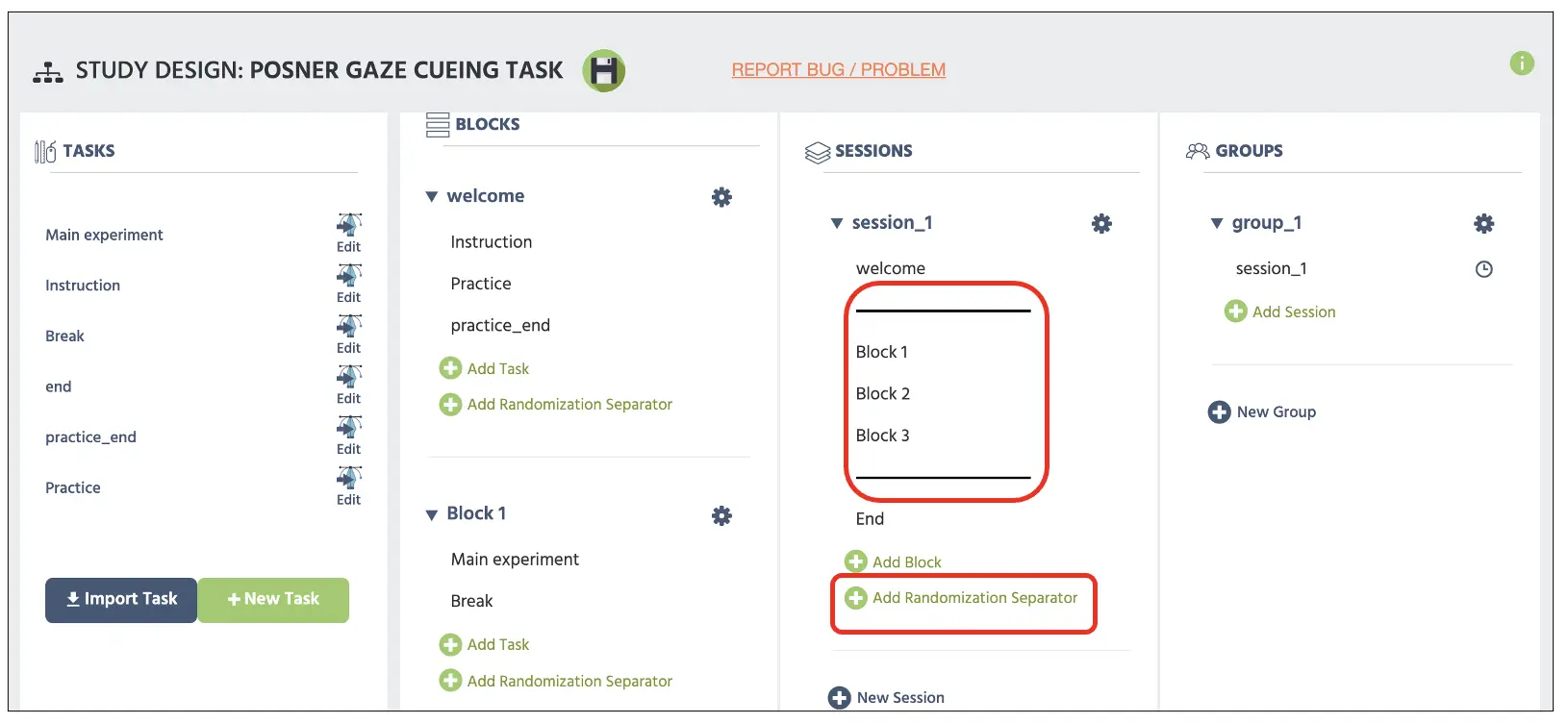 Abbildung 19. Anzeige der Haupt-Studiendesignseite, wobei das obere rote Feld zwei parallele Balken zeigt, die als Zufallsseparator dienen, der durch den Hinzufügen eines Zufallsseparators unten hinzugefügt wird.
Abbildung 19. Anzeige der Haupt-Studiendesignseite, wobei das obere rote Feld zwei parallele Balken zeigt, die als Zufallsseparator dienen, der durch den Hinzufügen eines Zufallsseparators unten hinzugefügt wird.
Das einzige, was in diesem Leitfaden noch bleibt, ist das Dokument zur Anleitung/Einwilligung, der Übungsblock, demographische Fragen und andere Protokolle, aber das variiert je nach Forscher und Institution, um diesen Leitfaden zu beenden. Für weitere Informationen zur Texterstellung konsultieren Sie bitte unsere Ressourcen Link für zusätzliche Informationen. Darüber hinaus ist die erstellte Studie auch als Vorlage in unserer Bibliothek verfügbar, indem Sie diesen Link zusammen mit anderen experimentellen Paradigmen verwenden. Damit, im Namen des Labvanced-Teams, wünsche ich Ihnen alles Gute bei all Ihren wissenschaftlichen Bestrebungen und hoffe, dass dieser Leitfaden als wichtiger Eckpfeiler für den Aufbau Ihrer Studie dient.