
10 Exemples Populaires d'Expériences Linguistiques dans Labvanced
Les chercheurs en langage et en discours utilisent des plateformes d'expérimentation en ligne comme Labvanced pour mener leurs différentes études, car c'est un moyen de rassembler rapidement à la fois des participants et des données.
En réalisant des expériences dans un laboratoire linguistique virtuel, en publiant des études en ligne et en les partageant sur le web, les linguistes et les psychologues cognitifs non seulement complètent leur recherche plus rapidement, mais créent également leur expérience rapidement et sans code.
Ci-dessous, nous metttons en avant 10 expériences linguistiques populaires qui peuvent être réalisées dans Labvanced pour étudier la perception de la parole et la compréhension du langage, chacune démontrant une capacité ou une fonctionnalité différente de la plateforme.
1. Tâche de l'Effet Stroop Multimodal
La Tâche de l'Effet Stroop Multimodal est une tâche classique qui défie les associations cognitives des participants.
Dans l'étude, des mots comme ‘bleu’ ou ‘vert’ sont affichés un par un avec une couleur de texte variable, ne correspondant parfois qu'à ce que le mot écrit indique. Cette incongruence met le participant au défi. Essayez-la ici !
L'étude incite le participant à se concentrer sur la couleur du texte et à ignorer le sens du texte. Pendant l'expérience, il y a aussi des mots auditifs distrayants prononcés, une voix qui dit une des 4 couleurs présentées.
Dans la session d'entraînement, le participant s'exerce à se concentrer sur la couleur du texte et à cliquer sur le bouton correspondant. Les deux autres dimensions (mot parlé et texte écrit) sont congruentes et reflètent la couleur cible.
Dans l'exemple ci-dessous dans la session d'entraînement, la réponse correcte est ‘F’ car la couleur du texte est bleue. Mais le participant est également renforcé car le mot écrit est également bleu et l'audio diffusé dit automatiquement ‘bleu.’
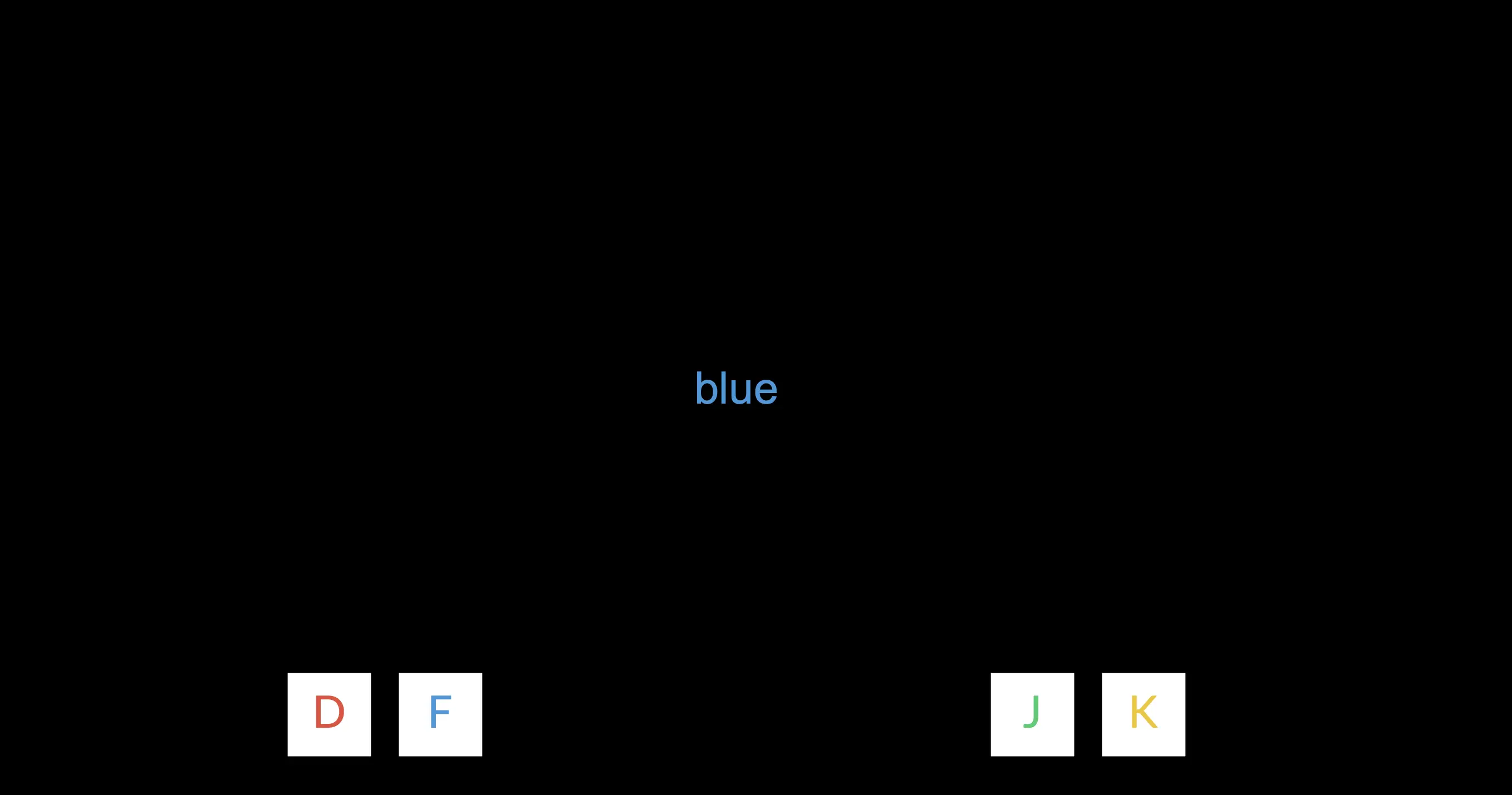
Dans l'expérience, les choses deviennent plus difficiles alors que les trois dimensions sont incongruentes.
Dans l'exemple ci-dessous, la réponse correcte est ‘D’ car la couleur est rouge, mais le mot écrit dit ‘jaune’ et la voix audio demande ‘bleu.’
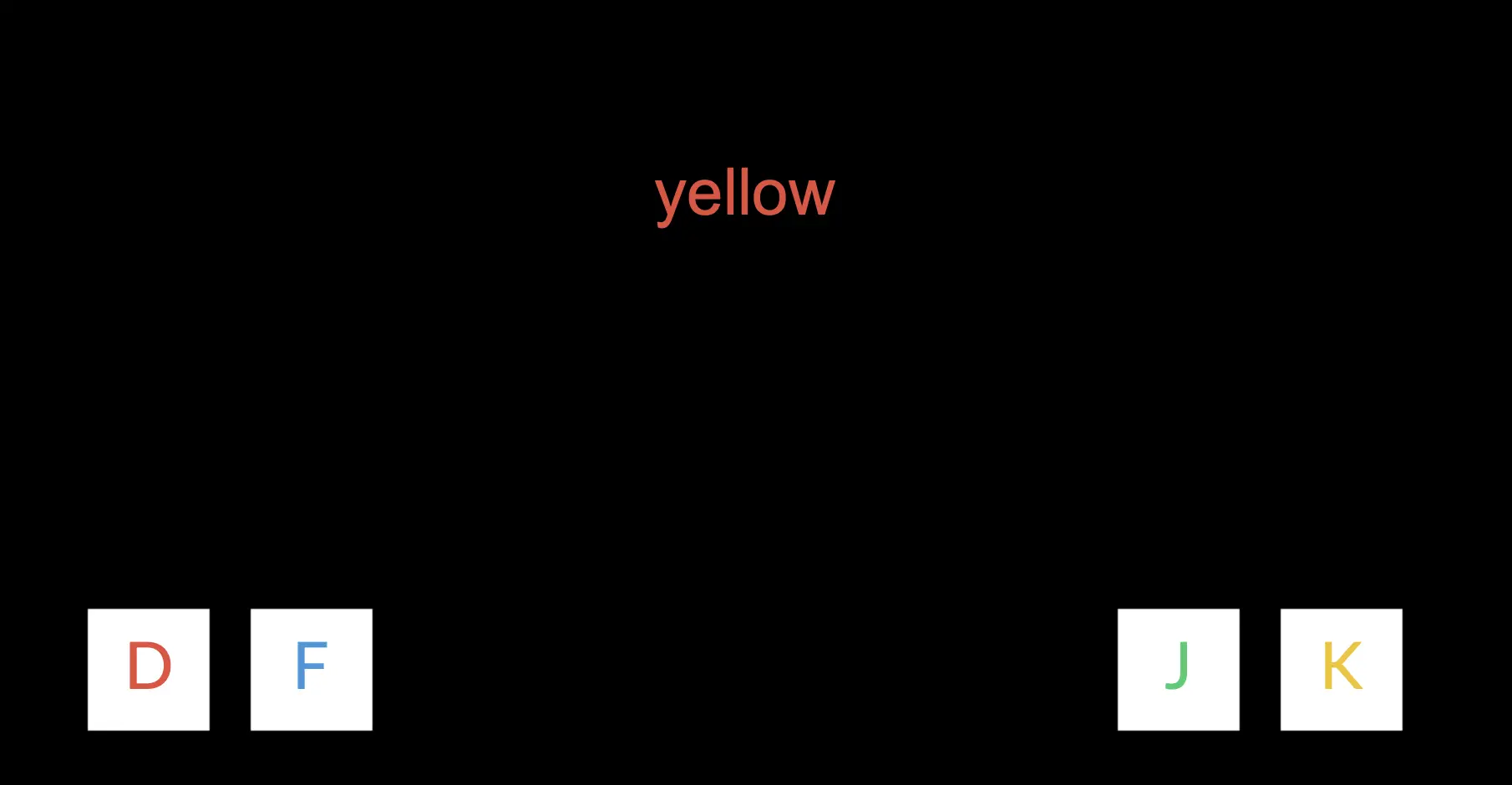
Ainsi, le participant est mis au défi de se concentrer et de limiter les diverses associations cognitives afin de choisir la réponse correcte et d'ignorer les indices de langue écrite et parlée.
📌 Mise en avant de la publication : L'influence de la dominance linguistique entre les tâches linguistiques et non linguistiques
Dans cette étude, réalisée dans Labvanced, les chercheurs ont créé et mis en œuvre une série de tâches linguistiques et non linguistiques afin de déterminer comment la dominance linguistique influence les effets d'interférence et de facilitation dans les tâches linguistiques et non linguistiques ainsi que la relation entre la performance sur les tâches linguistiques et non linguistiques. Par exemple, la tâche d'interférence mot-image (PWI) ainsi que la tâche de Stroop spatial non linguistique ont été administrées à cette fin. Les chercheurs suggèrent que la dominance linguistique module la performance sur les tâches linguistiques et non linguistiques.
Référence : Gálvez-McDonough, A. F., Blumenfeld, H. K., Barragán-Diaz, A., Anthony, J. J. R., & Riès, S. K. (2024). Influence de la dominance linguistique sur la résolution de l'interférence crosslinguistique et non linguistique chez les bilingues. Bilinguisme : Langue et Cognition, 1-14.
2. Complétez la Phrase
Cette étude, publiée par le Département de Linguistique de l'UCLA, vise à tester comment les locuteurs natifs américains adultes d'anglais terminent des phrases.
Les participants doivent écouter des fragments de phrases, puis fournir une réponse où leur voix est enregistrée en utilisant le microphone de leur ordinateur, complétant le fragment de phrase en une phrase complète.
Les participants sont invités à fournir une réponse en utilisant la première chose qui leur vient à l'esprit et sans hésitation.
- Le participant teste la fonction d'enregistrement de Labvanced pour s'assurer que son enregistrement fonctionne.
- Le participant passe à l'écran suivant et clique sur ‘Play’ pour entendre le fragment de phrase.
- Ensuite, le participant est invité à penser à un moyen de compléter la phrase en commençant par le fragment qu'il vient d'entendre.
- Le participant clique sur le bouton d'enregistrement et dit la phrase entière à voix haute.
L'étude vise à accroître les connaissances scientifiques sur la parole et le langage humain. Les chercheurs déclarent que les idées recueillies auront des implications positives pour plusieurs domaines, notamment : la mise en œuvre de la technologie informatique, l'enseignement des langues et le traitement de la pathologie de la parole.
📌 Mise en avant de la publication : Tâche de complétion de phrase basée sur un labyrinthe
Une autre approche des tâches de complétion de phrase est de sélectionner ou d'entrer un mot, plutôt que de compléter la phrase en parlant (comme dans l'étude ci-dessus). Dans l'étude décrite ci-dessous, réalisée dans Labvanced par Li et al., 2023, les chercheurs ont administré une tâche de complétion de phrase basée sur un labyrinthe. Les participants devaient sélectionner une description pour une cible donnée en sélectionnant successivement deux parties de leurs expressions à partir d'une liste d'options :
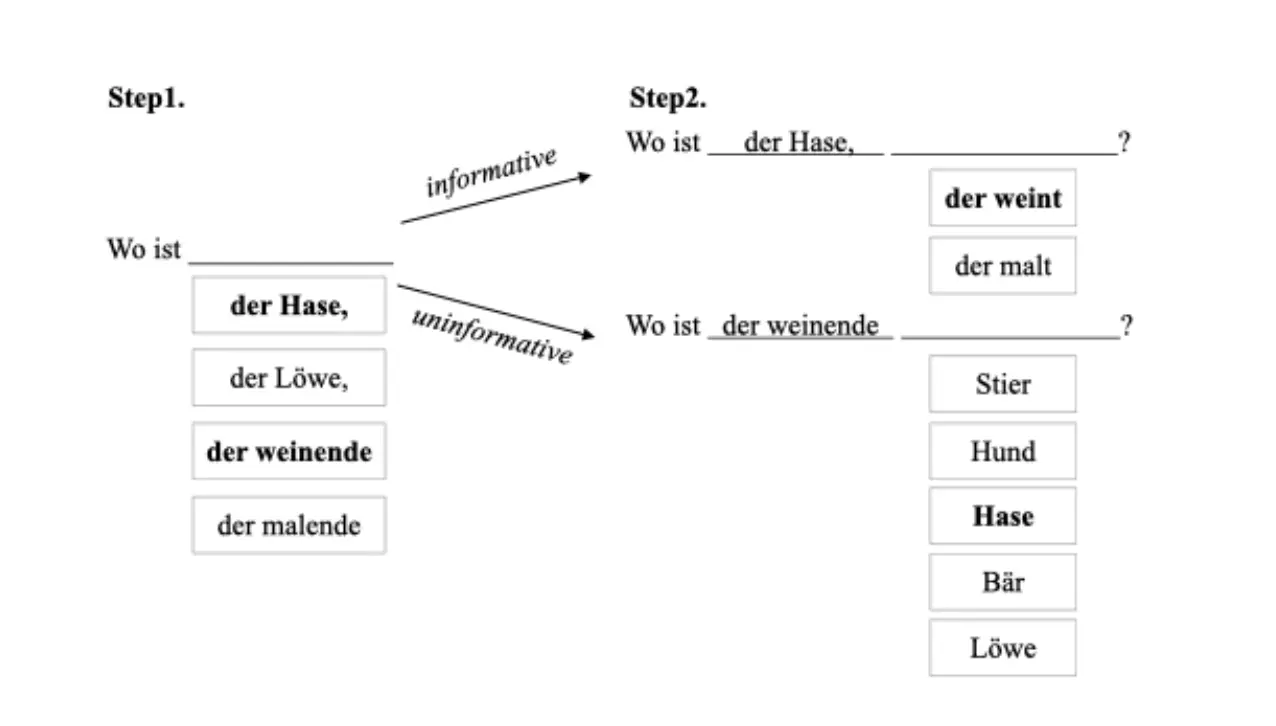
Référence : Li, M., Venhuizen, N. J., Jachmann, T. K., Drenhaus, H., & Crocker, M. W. (2023). L'informativité module-t-elle les préférences de linéarisation dans la production de références?. Dans Procédures de la Réunion Annuelle de la Société de Science Cognitive (Vol. 45, No. 45). CC BY 4.0
3. Dimensions & Sons
Dans cette expérience de discours et de langage de l'Institut Max Planck pour l'Esthétique Empirique à Francfort, les chercheurs se sont donnés pour mission d'étudier comment les vocalisations sont perçues.
Les participants commencent par remplir un simple questionnaire sur eux-mêmes. Ensuite, ils reçoivent l'instruction d'écouter des sons et des vocalisations. Après avoir perçu les stimuli audio, les participants sont invités à évaluer le son sur 2 échelles.
Cette expérience démontre comment incorporer un questionnaire au début de l'étude puis utiliser de l'audio pour étudier la perception humaine du son des vocalisations.
📌 Mise en avant de la publication : Interjections affectives et vocalisations à travers les langues
Dans cette recherche, qui a utilisé Labvanced, l'objectif était d'étudier, à travers les langues, la nature des signatures vocales dans les interjections émotionnelles et les vocalisations non linguistiques qui expriment la douleur, le dégoût et la joie à travers les langues. Les chercheurs ont analysé les voyelles et les interjections de plus de 130 langues et ont trouvé plusieurs résultats intéressants.
Pour les vocalisations non linguistiques, toutes les émotions semblent avoir des signatures vocaliques distinctes : la douleur évoque des voyelles ouvertes telles que [a], la joie évoque des voyelles antérieures telles que [i], et le dégoût évoque des voyelles centrales de type schwa. Pour les interjections, les interjections de douleur présentent des voyelles de type a et des diphtongues tombantes larges, tandis que les interjections de joie et de dégoût ne s'étendent géographiquement que pour des régularités vocaliques. Ces résultats suggèrent que la douleur est la seule expérience affective qui montre une signature préservée pour les vocalisations non linguistiques et les interjections à travers les langues.
Référence : Ponsonnet, M., Coupé, C., Pellegrino, F., Garcia Arasco, A., & Pisanski, K. (2024). Signatures vocaliques dans les interjections émotionnelles et les vocalisations non linguistiques exprimant la douleur, le dégoût et la joie à travers les langues. The Journal of the Acoustical Society of America, 156(5), 3118-3139.

4. Étude de Prononciation Espagnole
L'Étude de Prononciation Espagnole est l'une des nombreuses expériences de l'Université de Toronto publiées dans Labvanced. L'expérience est en espagnol, mais peut également être administrée en portugais, et teste la compréhension et les capacités linguistiques du participant à travers des tâches de parole et d'écoute.
Dans cette étude, le participant passe en revue des informations sur la procédure expérimentale. Ensuite, il y a 2 courtes tâches à réaliser, chacune durant environ 10 minutes. La première tâche concerne la parole et la lecture et la deuxième tâche concerne l'écoute.
À la fin, il y a un questionnaire afin que le participant puisse fournir des informations de base sur lui-même, ainsi que toute information pertinente concernant ses antécédents d'apprentissage des langues.
Labvanced est utilisé pour de nombreuses études d'apprentissage des langues et bilatérales. Les chercheurs peuvent concevoir leur expérience dans n'importe quelle langue, choisir de limiter une étude uniquement à des locuteurs spécifiques, et partager l'étude à l'international afin que des locuteurs de différentes langues puissent participer du monde entier ou garder l'étude locale pour examiner l'apprentissage des langues dans un groupe spécifique, telles que des étudiants dans une université apprenant une seconde langue.
📌 Mise en avant de la publication : Prosodie de l'espagnol de Montevideo
Dans cette étude, les chercheurs ont utilisé Labvanced afin de créer le premier profil de l'espagnol de Montevideo (EM), une variété rioplatense parlée en Uruguay qui a des racines dans l'espagnol castillan et l'italien, ainsi que des influences d'autres langues, y compris le guarani, le quechua et le portugais. Cette recherche visait à fournir la première description prosodique complète de l'espagnol de Montevideo (EM) en analysant son intonation, son rythme et son tempo. Les chercheurs ont utilisé Labvanced pour enregistrer les participants dans différentes tâches de production afin de capturer une large gamme de discours naturaliste.
Référence : Machado, V., & Escobar, L. (2023). La prosodie de l'espagnol de Montevideo : une description intonative, rythmique et de tempo. Canadian Journal of Linguistics.
5. Voix et Bien-être
Dans cette étude, la relation entre la perception du son et les sentiments est évaluée. Les participants sont invités à écouter 21 sons humains du monde entier. Après avoir entendu ce clip, le participant doit évaluer comment le son l’a fait se sentir à l'aide de l'échelle de Likert à 5 points.
L'écran expérimental s'ouvre avec les instructions de l'expérience. Vers la fin de l'explication, il y a un ajusteur de volume sonore où le participant peut régler et calibrer l'audio à un niveau confortable :
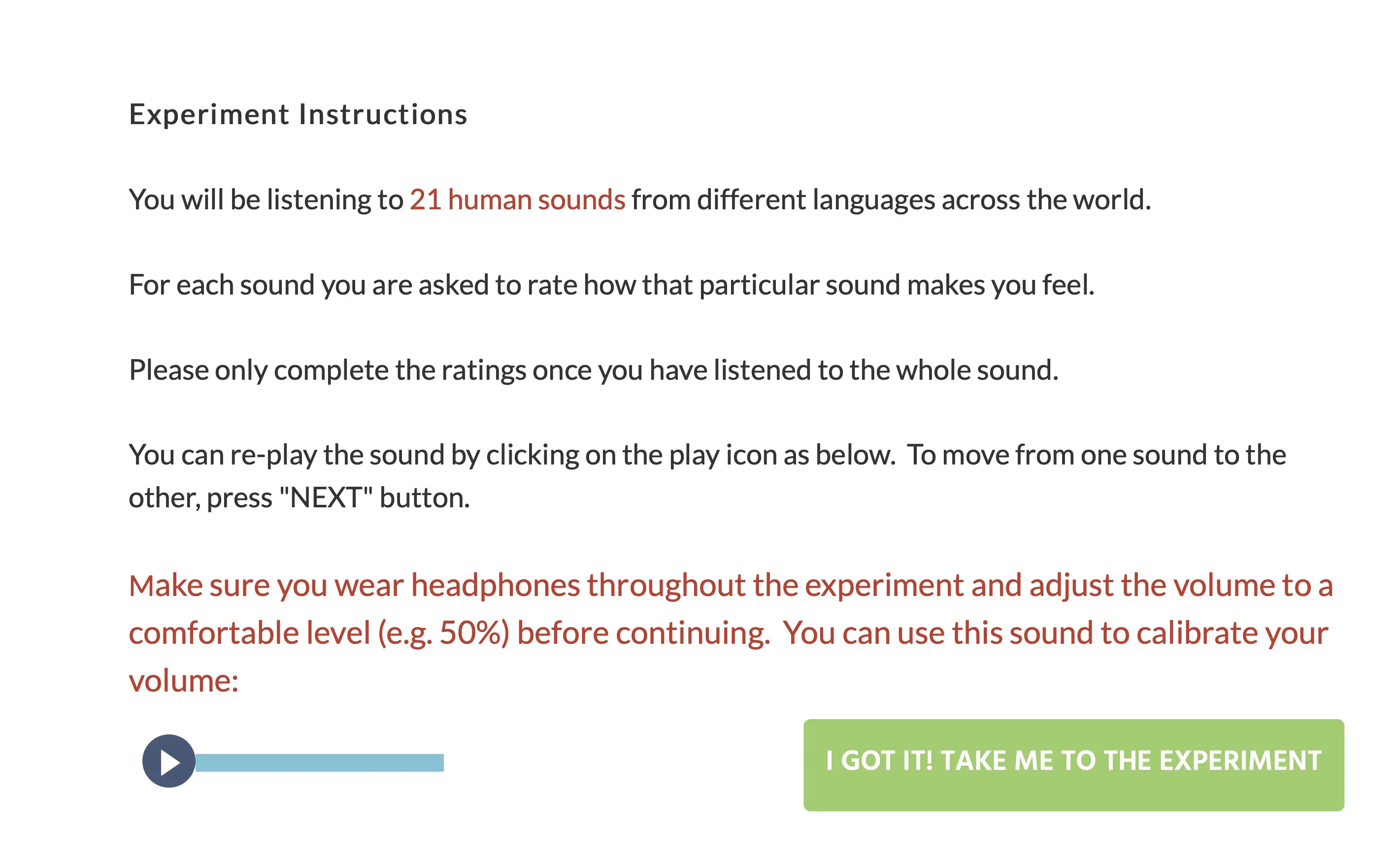
Après avoir calibré et ajusté le son, l'expérience commence.
Le participant entend un son qui joue et dure environ 30 secondes :
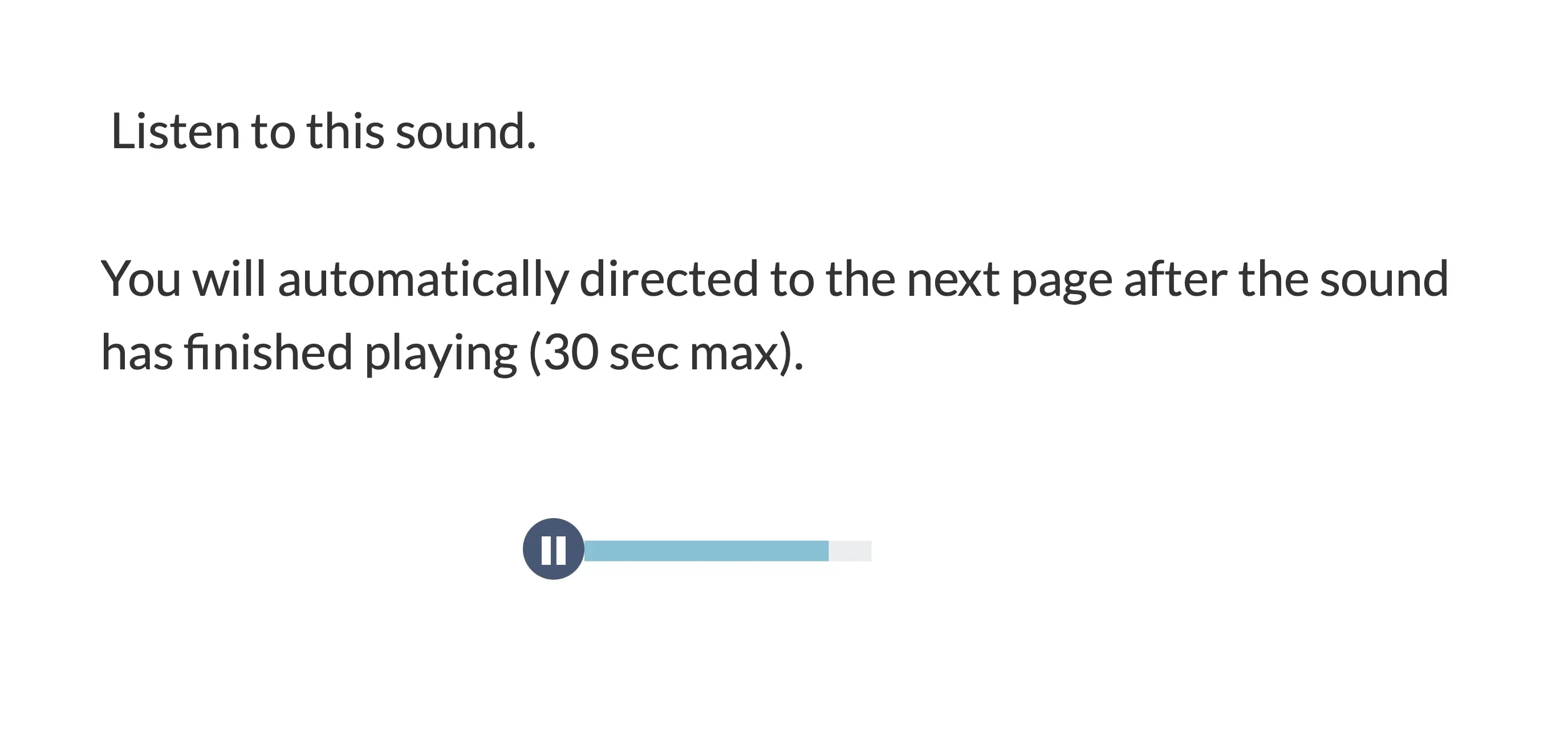
Ensuite, après que le son a été joué, le participant est invité à indiquer sur une échelle de Likert à 5 points dans quelle mesure certaines émotions et sentiments (comme la confiance, la tristesse ou l'alerte) ont été invoqués par l'audio :
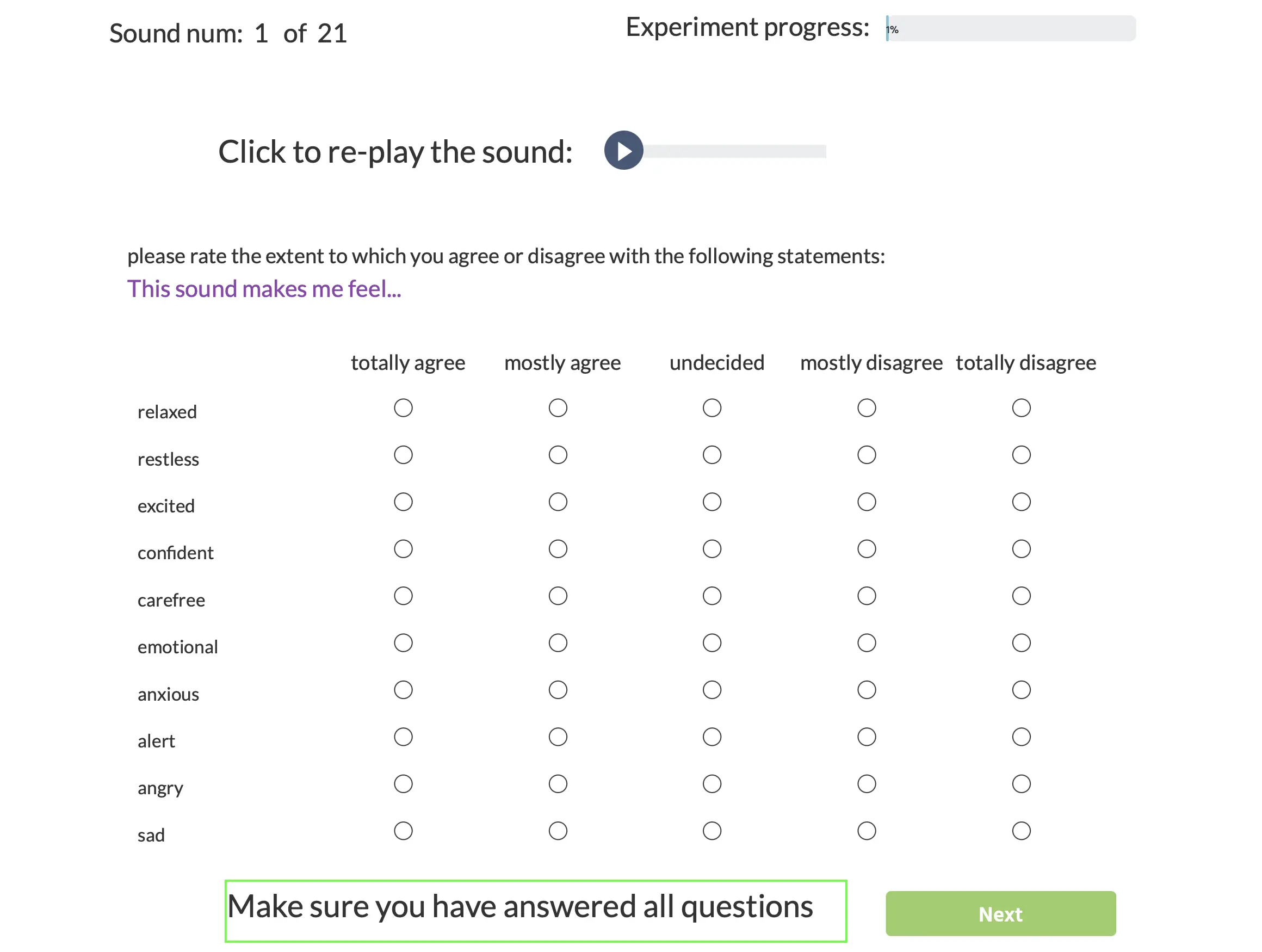
Cette expérience est un excellent exemple de la façon de présenter des enregistrements audio puis un questionnaire afin que le participant puisse fournir une réponse au son, à la langue ou à la vocalisation qu'il a perçue.
📌 Mise en avant de la publication : Préférences pour la voix chantée
L'objectif de l'étude était de prédire ce qui motive les préférences des participants lorsqu'ils 'aiment' un vocaliste en évaluant les caractéristiques perceptuelles et acoustiques, un sujet important dans le domaine de la psychologie de la préférence musicale.
Expérience Labvanced :
- Des évaluations perceptuelles ont été développées pour cette expérience sur des échelles bipolaires allant de 1 à 7 avec des mots d'ancrage contrastés à chaque pôle demandant aux participants d'évaluer les éléments suivants : précision de la hauteur, volume, tempo, articulation, souffle, résonance, timbre, attaque/onset vocal, vibrato. Quarante-deux participants ont évalué 96 stimuli sur 10 échelles différentes
- Sous-échelle de 18 éléments de la Sophistication Musicale de l'Index de Sophistication Musicale de Goldsmiths
- Inventaire de Personnalité de dix éléments (TPI)
- Test bref des préférences musicales (STOMP-R)
Principales conclusions : Les caractéristiques acoustiques et de bas niveau dérivées de la récupération d'informations musicales (MIR) expliquent à peine la variance dans les évaluations de liking des participants. En revanche, les caractéristiques perceptuelles des voix ont permis d'atteindre environ 43% de prédiction, suggérant que les préférences pour les voix chantées ne reposent pas sur des attributs acoustiques en soi, mais davantage sur des caractéristiques perceptivement expérimentées par les auditeurs. Cette découverte montre l'importance de la perception individuelle en ce qui concerne la psychologie de la préférence musicale. Lire la suite.
Référence : Bruder, C., Poeppel, D., & Larrouy-Maestri, P. (2024). Les caractéristiques perceptuelles (mais pas acoustiques) prédisent les préférences pour les voix chantées. Scientific reports, 14(1), 8977.
6. Tâches de Décision Lexicale
La Tâche de Décision Lexicale (TDL) est un autre excellent exemple d'une tâche basée sur la langue où les participants sont invités à indiquer si une chaîne de lettres présentée est un mot ou un non-mot dans la langue cible. Il existe plusieurs variations de la tâche de décision lexicale en raison de sa popularité dans ce domaine. En savoir plus sur la TDL.
📌 Publication Highlight: Anosmie acquise et compréhension du langage lié aux odeurs
Dans cette étude menée dans Labvanced, les chercheurs ont voulu évaluer si l'anosmie acquise (perte de l'odorat survenant plus tard dans la vie) a un impact sur la compréhension du langage lié aux odeurs. Les chercheurs ont administré une série de tâches afin d'obtenir une image complète de la mémoire liée aux odeurs chez les anosmiques et les contrôles. Fait intéressant, l'étude a conclu qu'il n'y avait aucune preuve que l'anosmie acquise altère la compréhension des mots liés aux odeurs ou aux goûts, mais les associations émotionnelles avec les mots d'odeur et de goût étaient modifiées chez les anosmiques, avec des évaluations plus positives. Dans l'ensemble, ces résultats suggèrent que le traitement du langage peut dans certains cas être indépendant de la capacité à avoir une expérience sensorielle olfactive.
Référence : Speed, L. J., Iravani, B., Lundström, J. N., & Majid, A. (2022). La perte du sens de l'odorat n'interfère pas avec le traitement des mots liés aux odeurs. Brain and language, 235, 105200.
https://doi.org/10.1016/j.bandl.2022.105200 CC BY 4.0
7. Réseautage sémantique
Dans cette étude en psycholinguistique de l'Université Temple, les relations entre les mots sont évaluées. L'expérience est conçue pour tester la force des relations entre les mots (par exemple, sémantiques et phonologiques).
Les participants voient un mot, puis une séquence de lettres. Si la séquence de lettres a un sens dans la langue anglaise, le participant est invité à cliquer sur ‘Y’ sur le clavier, mais si la séquence de lettres n'a aucun sens, alors ‘N’ doit être pressé.
Le design est simple et direct, mais il démontre comment recueillir les réponses des participants à l'aide de pressions de boutons après avoir présenté des mots visuellement dans une séquence particulière.
📌 Publication Highlight: Suivi oculaire, langage et attention visuelle
Cette étude a examiné comment l'information sémantique, transmise par des mots ou des images, influence l'attention visuelle dans une tâche de signalisation spatiale. Les chercheurs ont utilisé le suivi oculaire par webcam de Labvanced comme vérification de validité pour s'assurer que les participants maintenaient une fixation centrale.
![]()
L'expérience a utilisé un design à mesures répétées et impliquait deux parties :
- Expérience 1 : Les participants ont vu soit des mots réels soit des pseudomots comme amorces, suivis d'un signal spatial les dirigeant vers une cible. L'objectif était d'évaluer comment ces amorces influençaient la vitesse de détection de la cible.
- Expérience 2 : Les participants ont été présentés avec de vrais objets ou des pseudo-objets comme amorces, qui correspondaient ou ne correspondaient pas à la cible. Cette expérience visait à explorer les effets de la congruence sémantique et perceptuelle sur l'engagement attentionnel et la détection de la cible.
Données collectées : Temps de réaction, données de suivi oculaire (fixations et motifs d'attention des participants), et détails sur les types d'amorces (mots réels, pseudomots, objets connus, objets inconnus) et leur statut de correspondance (correspondance vs. non-correspondance) avec les cibles.
Résultats : Les connaissances sémantiques, transmises par des mots et des objets réels, facilitent de manière significative une détection plus rapide de la cible et améliorent la capture attentionnelle, même lorsque les amorces ne fournissent pas d'informations spatiales sur les cibles.
Référence : Calignano G, Lorenzoni A, Semeraro G et Navarrete E (2024) Mots avant images : le rôle du langage dans le biais de l'attention visuelle. Front. Psychol. 15:1439397.
8. Test de parole dans le bruit
Dans cette étude sur la parole dans le bruit, les chercheurs ont demandé aux participants de participer à une expérience dans Labvanced afin de déterminer des mesures subjectives et objectives de la précision d'écoute et des efforts. 67 participants, dont 42 avec une audition normale et 25 avec une perte auditive, ont complété l'Échelle d'évaluation de l'effort (EAS) et une tâche de reconnaissance de phrases. Les phrases BKB ont été présentées dans un bruit ressemblant à de la parole à des rapports signal-bruit (SNR) de -8, -4, 0, +4, +8 et +20 dB. Les participants ont répété les phrases à voix haute, et leurs réponses ont été enregistrées via webcam et notées par des assistants de recherche. L'étude a utilisé plusieurs mesures de résultats pour évaluer l'exactitude et l'effort d'écoute, y compris l'intelligibilité objective, l'intelligibilité subjective, l'effort d'écoute subjectif, la tendance subjective à abandonner l'écoute, et le temps de réponse verbal (VRT). L'effort d'écoute subjectif a été la première mesure à montrer une sensibilité à l'aggravation du SNR, suivi de l'intelligibilité subjective, de l'intelligibilité objective, de la tendance subjective à abandonner l'écoute, et du VRT.
Référence : Wiggins, I. M., Stacey, J. E., Naylor, G., & Saunders, G. H. (2025). Relations entre les mesures subjectives et objectives de la précision d'écoute et de l'effort dans une étude en ligne sur la parole dans le bruit. Ear and hearing, 10-1097.
9. Test de lecture pour adultes
Le Test de lecture pour adultes de l'Université Nottingham Trent teste la capacité d'une personne à lire un extrait de texte à voix haute, en utilisant la fonction d'enregistrement vocal de Labvanced, puis à répondre à des questions sur le passage.
Avant de commencer la session de formation, l'étude demande également aux participants de fournir leur adresse e-mail afin que les réponses d'une section précédente dans Labvanced puissent être liées.
Dans la session de formation, le participant doit s'enregistrer en lisant à voix haute le passage demandé :
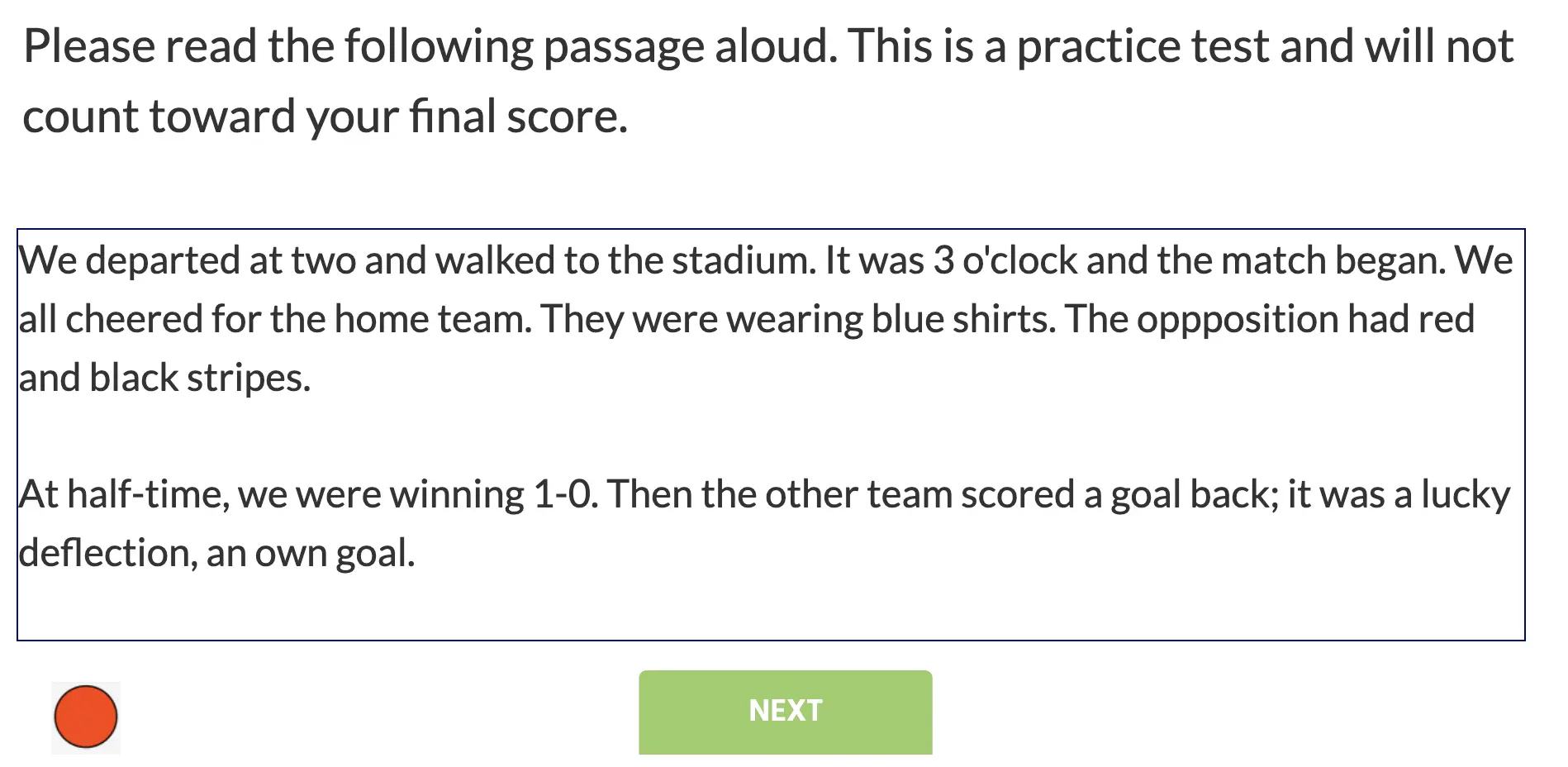
Après que l'enregistrement vocal ait été complété, une série de questions sur le passage suit :


Le Test de lecture pour adultes capture plusieurs types de mesures, des enregistrements vocaux aux réponses aux questionnaires. C'est un excellent moyen de mesurer la compréhension et la maîtrise du langage et peut être adapté à d'autres langues et groupes de population.
📌 Mise en avant de la publication : compréhension de la lecture numérique
Cette étude visait à comprendre comment les environnements de lecture numériques, avec des caractéristiques telles que le défilement et les hyperliens, affectent la compréhension de la lecture chez les enfants.
Les chercheurs ont utilisé Labvanced pour :
- Conception de la tâche : Elle a inclus l'intégration de différentes conditions (clic, défilement, hyperlien et combiné).
- Programmation des fonctionnalités de navigation : Boutons de navigation (par exemple, suivant, précédent, retour à l'histoire) et fonctionnalités d'hyperlien pour imiter les expériences de lecture numérique courantes.
- Suivi des participants : Facilitation de la participation à distance, permettant aux enfants de compléter les tâches depuis chez eux tout en étant surveillés par des assistants de recherche via des outils de conférence vidéo.
- Collecte de données : Mesures, telles que le temps que les participants ont passé à lire chaque passage, le temps pris pour référencer le texte lors de la réponse aux questions, et la fréquence des activations du bouton retour.
Les résultats ont montré que lorsque les enfants interagissaient avec des hyperliens flottants pour des définitions, cela avait un impact négatif sur leur compréhension de la lecture, tandis que le défilement n'avait pas d'effets néfastes sur la compréhension.
Référence : Krenca, K., Taylor, E., & Deacon, S. H. (2024). Défilement et hyperliens : les effets de deux caractéristiques numériques prévalentes sur la compréhension de la lecture numérique chez les enfants. Journal of Research in Reading.
10. Tâche de conscience prosodique
Une tâche de conscience prosodique est conçue pour évaluer la capacité d'un individu à reconnaître et manipuler les caractéristiques prosodiques du langage. Dans la démo ci-dessous dans Labvanced, les participants sont invités à prononcer un mot puis à identifier où se trouve la syllabe accentuée dans ce mot.
Exemples supplémentaires
Édition dynamique de texte
Dans certains cas, vous pourriez être intéressé à déterminer comment les participants éditent activement un texte écrit. La vidéo ci-dessous montre comment vous pouvez suivre l'édition de texte en temps réel, y compris les clics de souris, les pressions de touches et les modifications de paragraphes à l'aide de Labvanced.
Essayez cette démo d'Édition dynamique de texte, comme indiqué ci-dessus, pour vous-même en cliquant sur le Participate bouton ou Import à votre compte.
Mesures de dépistage de l'audibilité
Dans certains cas, il peut être important de vérifier l'audibilité de base des stimuli auditifs avant de procéder aux essais expérimentaux principaux. Dans cette étude comparant la faisabilité des tests neuropsychologiques à distance par rapport aux tests en face à face pour la recherche sur la démence.
La recherche a commencé par demander aux participants d'écouter un ensemble de 10 phrases de la liste de Bamford-Kowal-Bench (BKB) dans Labvanced.
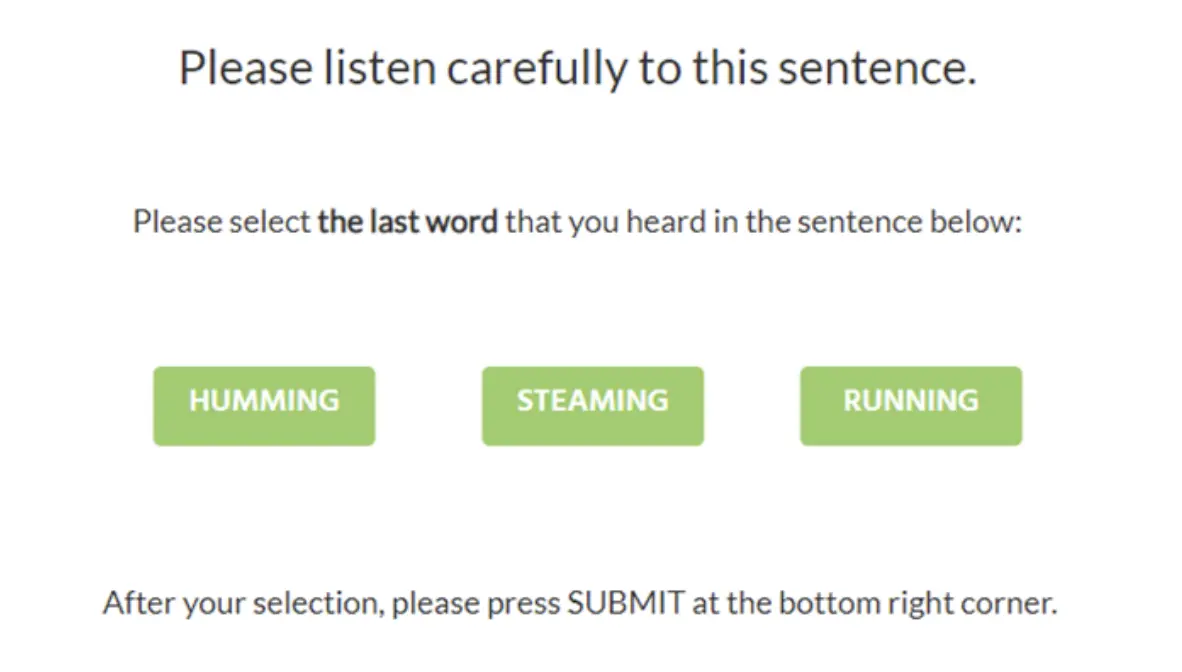
Dans l'exemple ci-dessus, la phrase prononcée était “Le moteur de la voiture fonctionne” et les participants devaient indiquer le dernier mot entendu. Pour chaque phrase, deux contrefaçons étaient affichées à côté de la cible, toutes deux ayant du sens dans la phrase lorsqu'elles remplaçaient la cible. De plus, l'une des contrefaçons a également été sélectionnée pour rimer vaguement avec le mot cible (par exemple ici ce serait “battement”).
Référence : Requena-Komuro, M. C., Jiang, J., Dobson, L., Benhamou, E., Russell, L., Bond, R. L., ... & Hardy, C. J. (2022). Tests neuropsychologiques à distance par rapport aux tests en face à face pour la recherche sur la démence : une étude comparative chez des personnes atteintes de la maladie d'Alzheimer, de démence frontotemporale et de personnes âgées en bonne santé. BMJ open, 12(11), e064576.
Glisser et déposer des stimuli pour la catégorisation
Cette étude a mené des recherches sur les sons musicaux en déterminant comment les participants classeraient des extraits comme étant « semblables à la parole » ou « semblables à la musique ».
Expérience Labvanced : Utilisant 30 enregistrements de tambours dùndún (un tambour ouest-africain qui est également utilisé comme substitut de parole), les participants devaient classer les enregistrements. Les chercheurs visaient à déterminer les prédicteurs potentiels des catégories musique-parole. 15 des enregistrements étaient considérés comme de la « musique » et consistaient en des rythmes de Yorùbá àlùjó (danse), tandis que les 15 autres enregistrements étaient des « substituts de parole », contenant des proverbes Yorùbá et des oríkì (poésie). Les participants devaient glisser et déposer pour catégoriser les stimuli audio que les participants pouvaient jouer librement pour écouter (voir image ci-dessous). Différents participants ont participé à chaque expérience.
Dans la première expérience, les catégories étaient fournies, à savoir « semblable à la parole » et « semblable à la musique ». Dans la deuxième expérience, les participants devaient déterminer par eux-mêmes quelles seraient les deux catégories pour différencier les sons et les étiquetèrent ensuite.
Résultats : Le regroupement hiérarchique des regroupements de stimuli des participants montre que la distinction parole/musique émerge et est observable, mais n'est pas primaire. Une analyse supplémentaire de la tâche de réponse libre a montré que les étiquettes assignées par les participants convergent avec les prédicteurs acoustiques des catégories. Un tel résultat soutient l'effet de priming dans la discrimination entre musique et parole, et éclaire ainsi les mécanismes de catégorisation de tels signaux auditifs courants.
Référence : Fink, L., Hörster, M., Poeppel, D., Wald-Fuhrmann, M., & Larrouy-Maestri, P. (2023). Caractéristiques sous-jacentes à la parole versus la musique en tant que catégories d'expérience auditive. Pre-print.
Conclusion
Ces 10 expériences linguistiques, ainsi que les exemples supplémentaires, représentent non seulement ce que vous pouvez faire dans Labvanced, mais aussi comment des chercheurs de diverses universités étudient la parole et le langage, mais aussi la perception à l'aide d'expériences en ligne pour enregistrer des données et des réponses.